
 我的工具
我的工具数据结构与算法
程序=数据结构+算法
- 勤于思考
- 多做多练
参考资料
https://www.bilibili.com/video/BV1nJ411V7bd 数据结构与算法基础(青岛大学-王卓)
https://zhuanlan.zhihu.com/p/72505589 记一次腾讯面试:有了二叉查找树、平衡树(AVL)为啥还需要红黑树?
https://wwa.lanzous.com/iunSbe70jgb 数据结构与算法教程app
https://wwa.lanzous.com/iz0Skey6rij 算法动画图解app
https://www.bilibili.com/video/BV1hE41147tP 红黑树结构详解
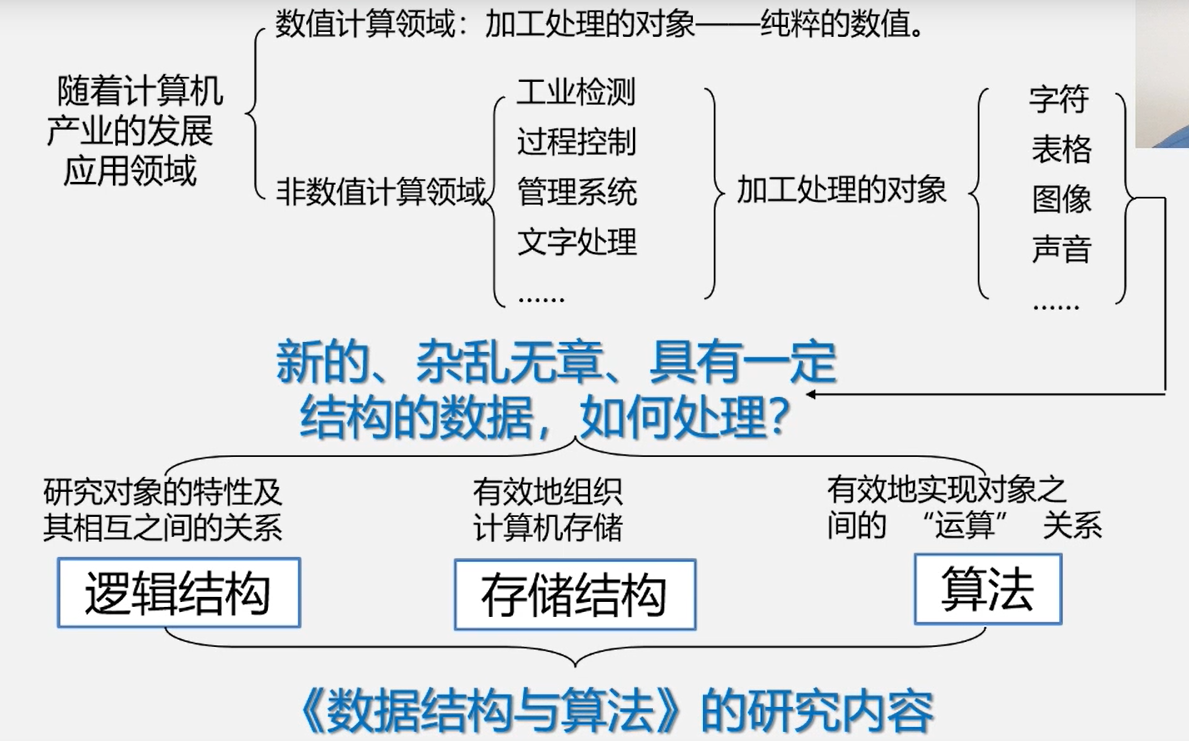
绪论
数据结构是一门研究非数值计算的程序设计中计算机的操作对象以及他们之间的关系和操作的学科
术语
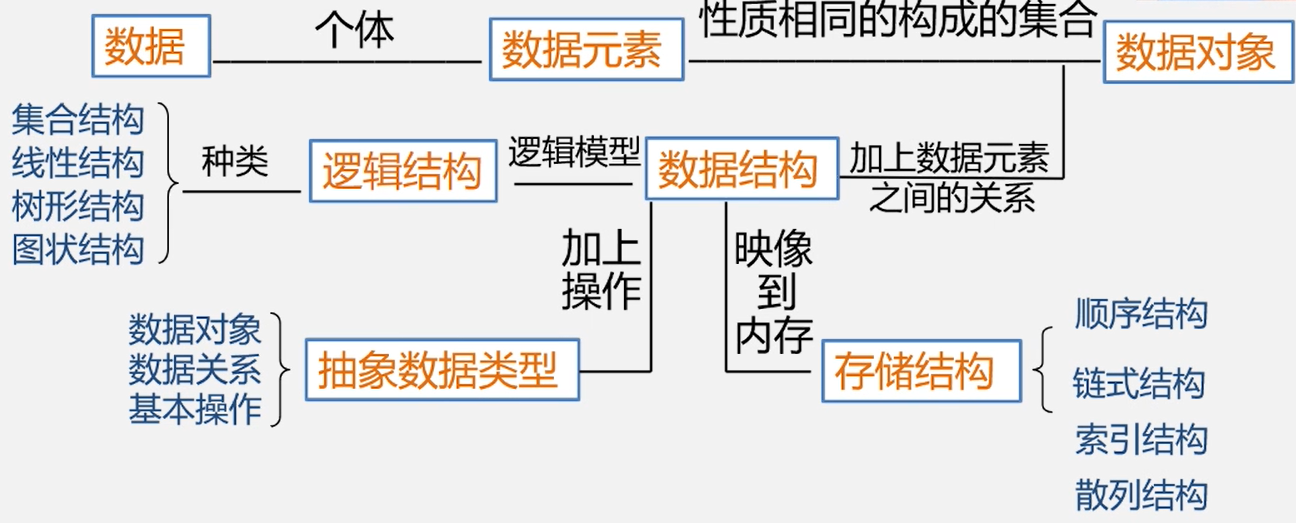
数据(Data)
- 是能够输入计算机且能被计算机处理的各种符号的集合
- 信息的载体
- 是对客观事物符号化的表示
- 能够被计算机识别、存储和加工
- 包括
- 数值型的数据:整形、实数等
- 非数值型数据:文字、声音、图像、图形
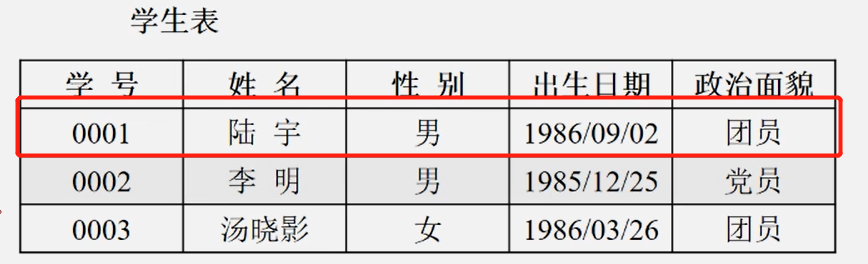
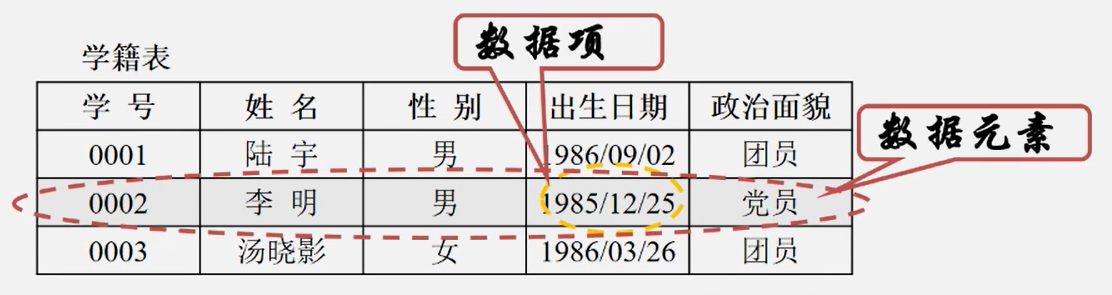
数据元素(Data element)
- 是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理
- 也简称为元素、记录、结点或顶点
数据项
- 构成数据元素的不可分割的最小单位
数据对象(Data Object)
- 性质相同的数据元素的集合,是数据的一个子集
- 整数数据对象是集合N={0,±1,±2}
数据结构(Data Structrue)
1、数据元素之间的逻辑关系,也成为逻辑结构
2、数据元素及其关系在计算机内存中的表示(又称映像),成为数据的物理结构或数据的存储结构。
3、数据的运算和实现,即对数据元素可以施加的操作以及这些操作在响应存储结构上的实现
-
逻辑结构
- 描述数据元素之间的逻辑关系
- 与数据的存储无关,独立于计算机
- 是从具体问题抽象出的数学模型
-
物理结构
- 数据元素及其关系在计算机存储器中的结构
-
逻辑结构与存储结构的关系
- 逻辑结构是数据结构的抽象,存储结构是数据结构的实现
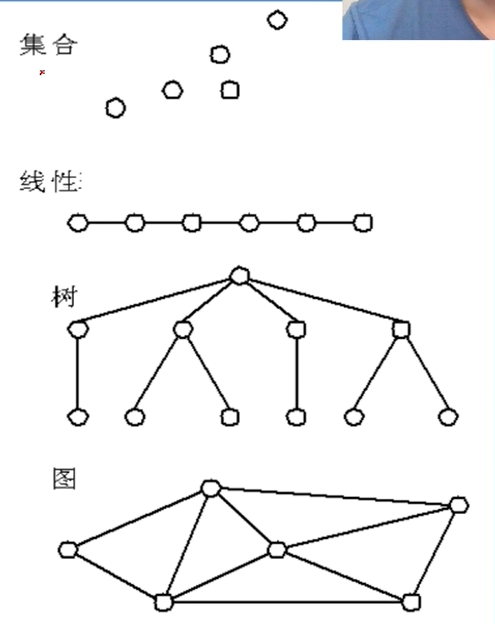
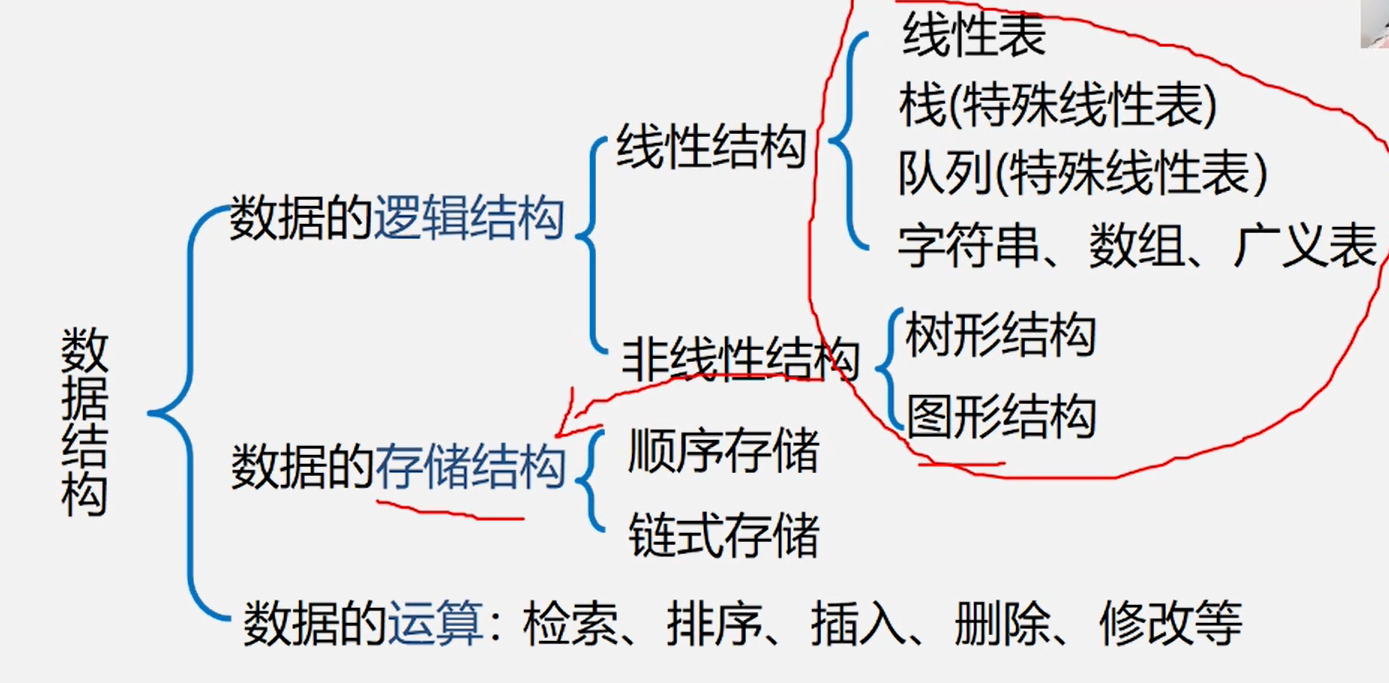
逻辑结构的种类
划分方式一
- 线性结构
- 有且仅有一个开始和一个终端结点,并且所有阶段都最多只有一个直接前趋和一个直接后继
- 例如:线性表、栈、队列、串
- 非线性结构
- 一个节点可能有多个直接前趋和直接后继
- 例如:树、图
划分方式二
- 集合结构:结构中的数据元素之间除了同属于一个集合的关系外,无任何其他关系
- 线性结构:结构中的数据元素之间存在着一对一的线性关系
- 树形结构:结构中的数据元素之间存在这一对多的层次关系
- 图状结构、网状结构:结构中的数据元素之间存在着多对多的任意关系
存储结构的种类
顺序存储结构

链式存结构
索引存储结构
散列存储结构
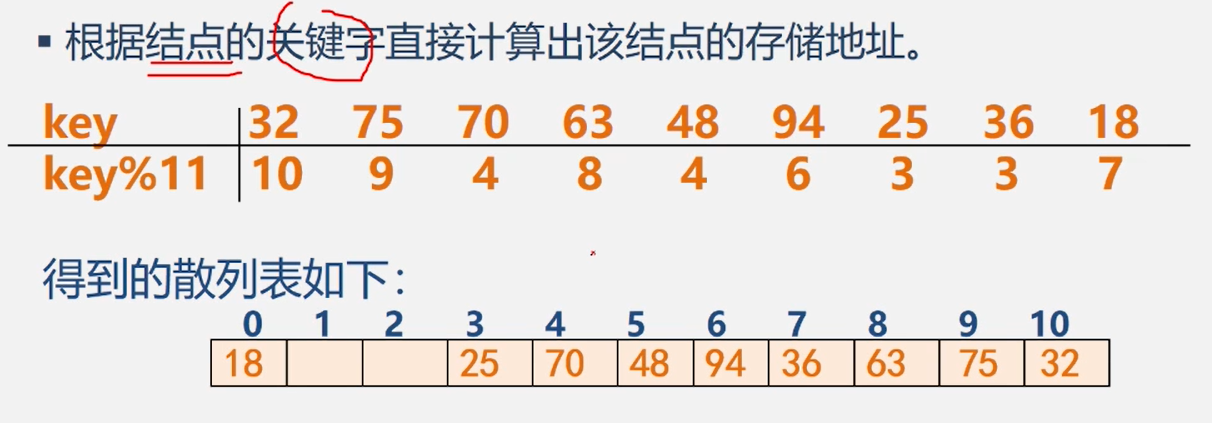
数据类型和抽象数据类型
数据类型 Data Type

- 高级语言中的数据类型明显地或隐含地规定了程序执行期间变量和表达的所有可能的取值范围,以及在这些数值范围上所允许进行的操作。
- 例如,C语言中定义变量i为int类型,就表示i是[-min,max]范围的整数,在这个整数集上可以进行+、-、*、/、%等操作
- 数据类型的作用
- 约束变量或常量的取值范围
- 约束变量或常量的操作


抽象数据类型(Abstract Data Type ,ADT)

什么是抽象?
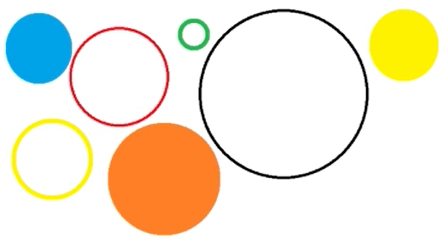
上面图中画的是什么?是各种圆形,什么是圆,(到某个点的距离相等的点的集合)。运算:构造圆、求面积、求周长。不同底色,不同边框,不同大小。为什么不说是正方形呢?这就是抽象
抽象数据类型的形式定义



基本操作定义格式说明

定义举例:Circle的定义
ADT Circle {
数据对象:D = {r,x,y | r,x,y均为实数}
数据关系:R = {<r,x,y> | r是半径,<x,y>是圆心坐标}
基本操作:
Circle(&C,r,x,y)
操作结果:构造一个圆
double Area(C)
初始条件:圆已存在。
操作结果:计算面积。
double Circumnference(C){
初始条件:圆已存在。
操作条件:计算周长。
}
}ADT Circle
抽象数据类型的实现概念
抽象数据类型可以通过固有 的数据类型(如整形、实性、字符型等)来表示和实现
即利用处理器中已存在的数据类型来说明新的结构,用已实现的操作来组合新的操作
概念小结
算法
算法的定义
- 对特定问题求解方法和步骤的一种描述,他是指令的有限序列。其中每个指令表示一个或多个操作。
- 简而言之:
算法就是解决问题的方法和步骤。
算法的描述
- 自然语言
- 流程图
- 伪代码
- 程序代码
算法与程序
- 算法是解决问题的一种方法或一个过程,考虑如何将输入转换为输出、一个问题可以有多种算法
- 程序是用某种程序设计语言对算法的具体实现

算法特性
- 有穷性 一个算法必须总是在执行有穷步之后结束,且每一步都在有穷时间 内完成
- 确定性 算法中的每一条指令必须有确切的含义,没有二义性,在任何条件下,只有唯一的一条执行路径,即对于相同的输入只能得到相同的输出
- 可行性 算法是可执行的,算法描述的操作可以通过已经实现的基本操作执行有限次来实现。
- 输入 一个算法有零个或多个输入
- 输出 一个算法有一个或多个输出
算法设计要求
- 正确性(Correctness) 算法满足问题要求,能正确解决问题
- 程序中不含语法错误
- 程序对于几组输入数据能够得出满足要求的结果
- 程序对于精心选择的、典型、苛刻且带有刁难性的几组输入数据能够得出满足要求的结果
- 程序对于一切合法的输入数据都能得出满足要求的结果
- 可读性(Readability)
- 算法主要是为人的阅读和交流其次才是为计算机执行,因此算法应该易于人的理解;
- 另一方面,晦涩难读的算法易于隐藏较多错误而难以调试。
- 健壮性(Robustness)
- 指当输入非法数据时,算法恰当的做出反应或进行相应处理,而不是产生莫名其妙的输出结果。
- 处理出错的方法,不应是中断程序的执行,而应是返 回一个表示错误或错误性质的值,以便在更高的抽象层次上进行处理
- 高效性(Efficiency)
- 要求花费尽量少的时间和尽量低的存储需求
算法分析
对于同一个问题,可以有许多不同的算法。究竟如何来评价这些算法的优劣程度呢?
算法分析的目的是看算法实际是否可行,并在同一问题存在多种算法时进行性能上的比较,以便从中挑选出比较优的算法。
一个好的算法首先要具备正确性然后是健壮性、可读性在几个方面都满足的情况下,主要考虑算法的效率,通过算法的效率高低来评判不同算法的优劣。
算法的效率由一下两个方面考虑
- 时间效率 : 指的是算法所耗费的时间
- 空间效率: 指的是算法执行过程中所耗费的存储空间
时间效率和空间效率有时候是矛盾的,需要使用者从中取舍。
时间复杂度
算法时间效率的度量
- 算法时间效率可以用依据该算法编制的程序在计算机上执行所消耗的时间来度量。
- 两种度量方法
- 事后统计
- 将算法实现,测算其时间和空间开销
- 缺点:编写程序实现算法将花费较多的时间精力;得到的实验结果依赖于计算机软硬件等环境因素,掩盖算法本身优劣
- 事前分析
- 对算法所消耗资源的一种估算方法
- 事后统计
事前分析法
一个算法的运行时间是指一个算法在计算机上运行所耗费的时间大致可以等于计算机执行一种简单的操作(如赋值、比较、移动等)所需的时间与算法中进行的简单操作次数乘积。
算法运行时间=每条语句的频度 x 该语句执行一次所需的时间
每条语句执行一次所需的时间,一般是随机器而异的。取决于机器的指令性能、速度以及编译的代码质量。是由机器本身软硬件环境决定的,它与算法无关。
所以,我们可
假设执行每条语句所需的时间均为单位时间。此时对算法的运行时间的讨论就可转化为讨论该算法中所有语句的执行次数,即频度之和了。

算法时间复杂度的渐进表示法


算法时间复杂度定义

什么是基本语句?
- 算法中重复执行教和算法的执行时间成正比的语句
- 对算法运行时间的贡献最大
执行次数最多
问题规模f(n),n越大算法的执行时间越长
- 排序:n为记录数
- 矩阵:n为矩阵的阶数
- 多项式:n为多项式的项数
- 集合:n为元素个数
- 树:n为树的结点个数
- 图:n为图的顶点数或边数

分析算法时间复杂度的基本方法
- 找出语句频度最大的那条语句作为基本语句
- 计算基本语句的频度得到问题规模n的某个函数f(n)
- 取其数量级用符号“O”表示
- 循环中语句嵌套最深的往往就是执行次数最高的
int x = 0; int y = 0;
for(int k = 0; K<n; K++){ n+1
x++; n
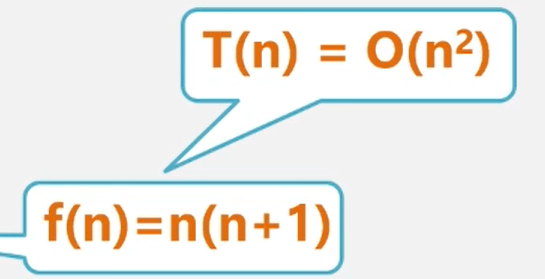
for (int i = 0; i<n ; i++){ n*n
for( int j = 0; j<n ; j++){ n*(n+1) //这是执行次数最多的语句 f(n)=n(n+1)
y++; n*n
}
}
}
对数例子

请注意:有的情况下,算法中基本操作重复执行的次数还随问题的输入数据集不同而不同


算法的时间复杂度
- 最坏时间复杂度:指在最坏情况下,算法的时间复杂度。
- 平均时间复杂度:指在所有可能输入实例在等概率出现的情况下,算法的期望运行时间。
- 最好时间复杂度:指在最好情况下,算法的时间复杂度
一般总是考虑在最坏情况下的时间复杂度,以保证算法的运行时间不会比它更长。

算法时间效率的比较
当n取得很大时,指数时间算法和多项式时间算法在所需时间上非常悬殊
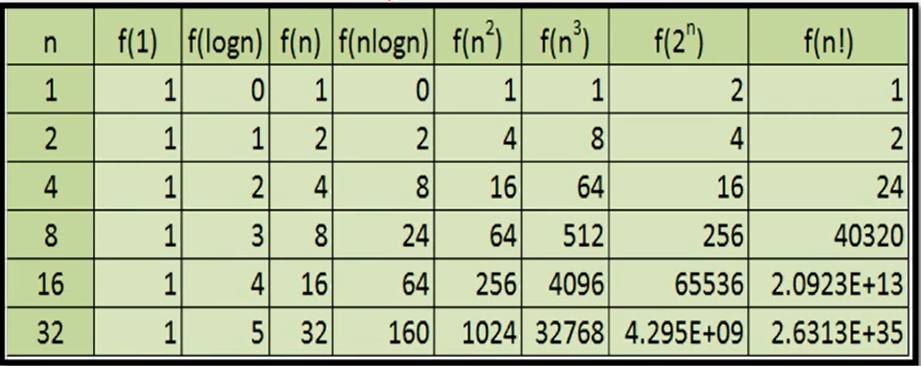
增长曲线
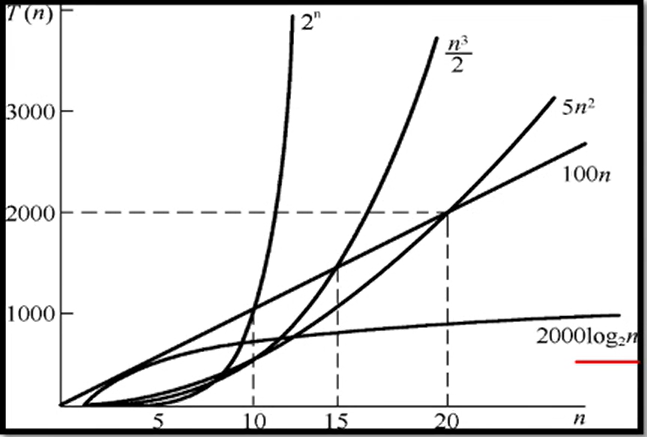
时间复杂度T(n)按数量级递增顺序为:

空间复杂度
空间复杂度:算法所需存储空间的度量,
记作:S(n)=O(f(n))
其中n为问题的规模(或大小)
算法要占据的空间
- 算法本身要占据的空间,输入/输出,指令,常数,变量等
- 算法要使用的辅助空间

public static void main(String[] args) {
int[] nubers = {1,2,3,4,5,6,7,8,9};
for (int i = 0 ; i<nubers.length/2;i++){
int temp = nubers[i];
nubers[i] = nubers[nubers.length-i-1];
nubers[nubers.length-i-1] = temp;
}
System.out.println(Arrays.toString(nubers));
}
小结
基本的数据结构
线性结构
线性表
2.1线性表的定义和特点
线性表是具有相同特性的数据元素的一个有限序列

线性表
- 由n(n≥0)个数据元素结点)a1,a2,…an组成的有限序列。
- 其中数据元素的个数n定义为表的长度。
- 当n=0时称为空表将非空的线性表(n>0)记作:(a1,a2,…an)
- 这里的数据元素a(1≤i≤n)只是一个抽象的符号,其具体含义在不同的情况下可以不同。


同一线性表中的元攀必定具有相同特性,数据元素间的关系是线性关系
逻辑特征

2.2案例引入
一元多项式的运算


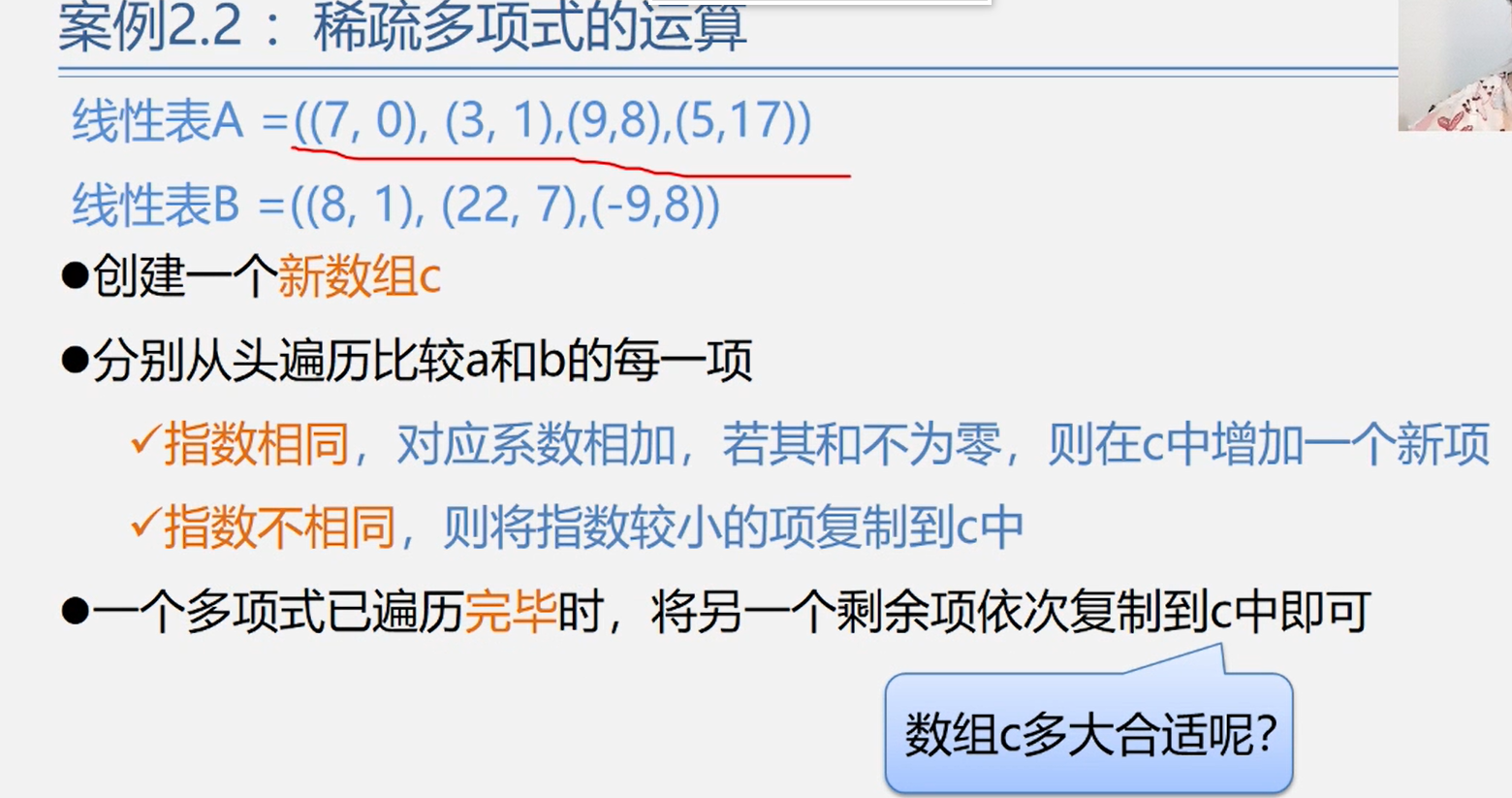
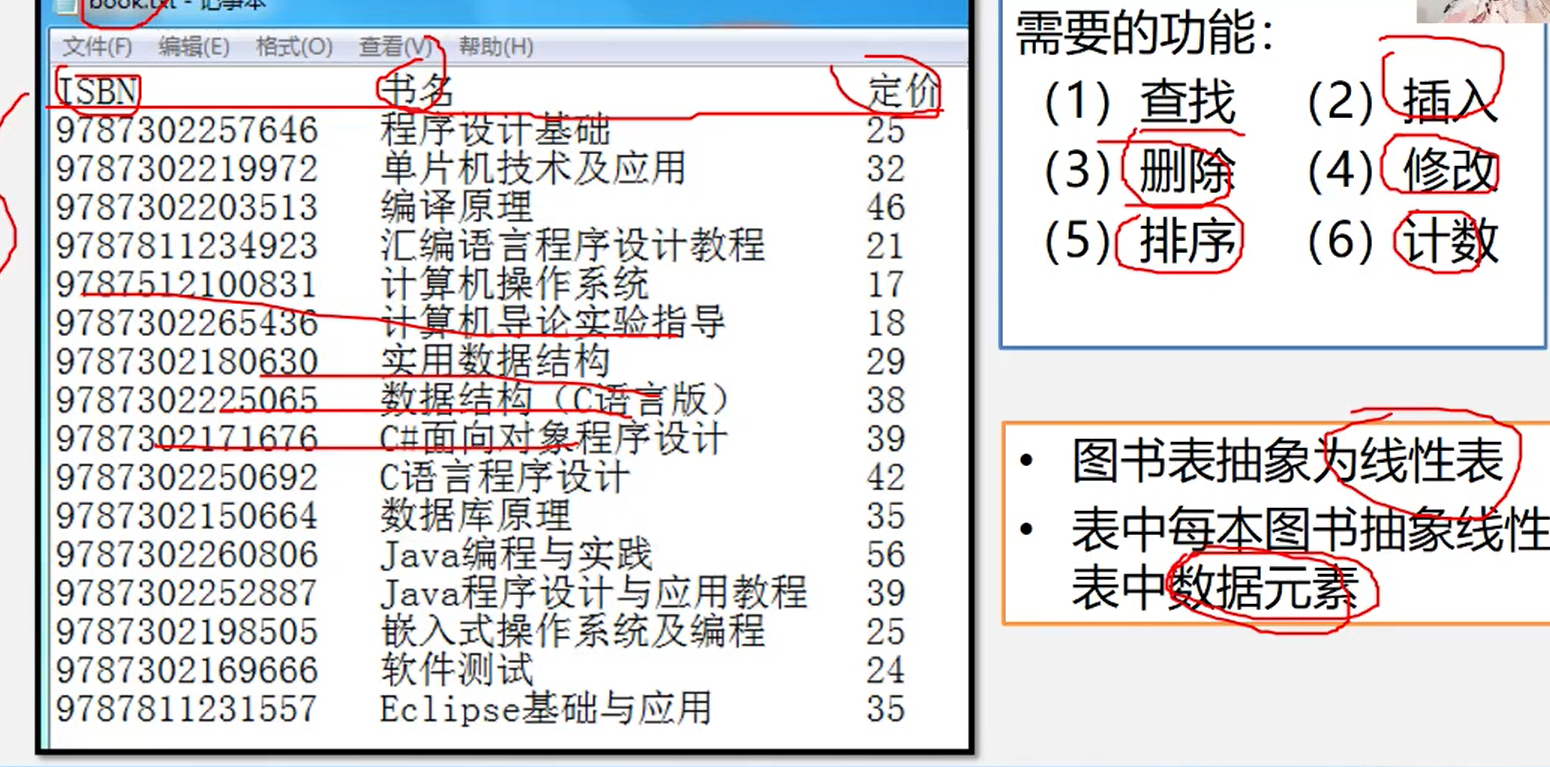
图书管理系统

总结、
- 线性表中数据元素的类型可以为简单类型,也可以为复杂类型
- 许多实际应用问题所涉的基本操作有很大相似性,不应为每个具体应用单独编写一个程序
- 从具体应用中抽象出共性的逻辑结构和基本操作(抽象数据类型),然后实现其存储结构和基本操作
2.3线性的类型定义
抽象数据类型的定义
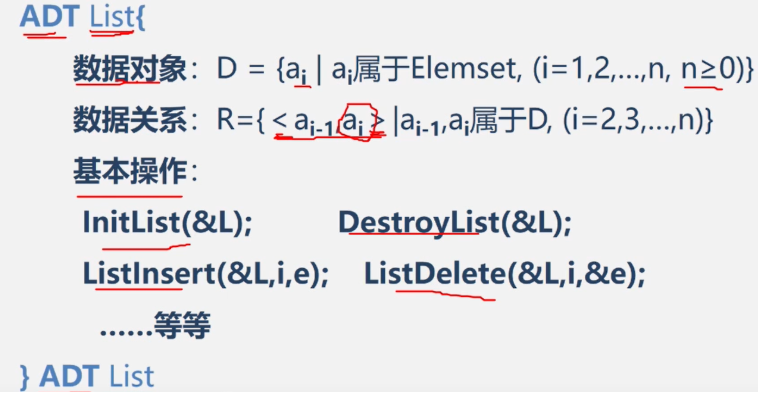
基本操作








以上所提及的运算是逻辑结构上定义的运算。只要给出这些运算功能是"做什么",至于"如何做"等实现细节,只有待确定了存储结构之后才考虑。
2.4线性表的顺序表示和实现
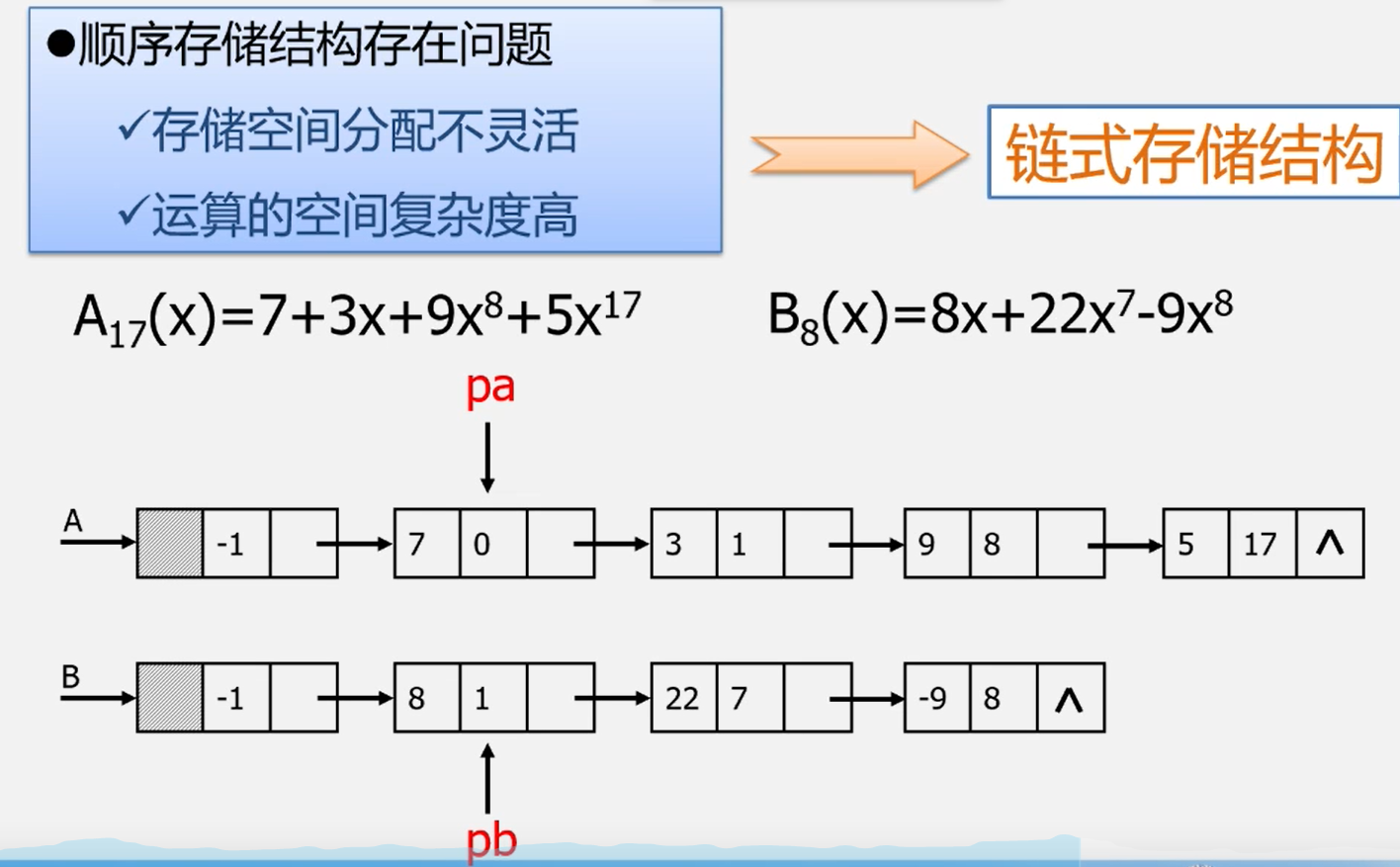
在计算机内,线性表有两种基本的存储结构。顺序存储结构和链式存储结构。
线性表的顺序表示又称为顺序存储结构或顺序映像。
顺序存储定义:把逻辑上相邻的数据元素存储在物理上相邻的存储单元中的存储结构。
简而言之,逻辑上相邻,物理上也相邻
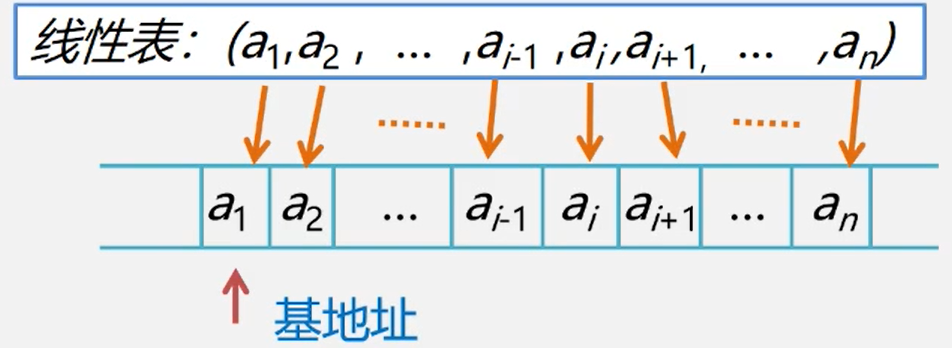
基地址:线性表的第1个数据元素a的存储位置,称作线性表的起始位置或基地址。
例如:线性表(1,2,3,4,5,6)的存储结构
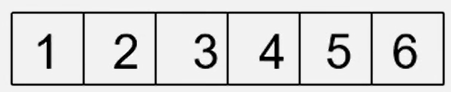
数据依次存储,地址连续中间没有空出存储单元。这样的是一个典型的线形表顺序存储结构。
如果是:

地址不连续中间存在空的存储单元。不是一个线形表顺序存储结构。
线形表顺序存储结构占用一片续单存储空间。
知道某个元素的存储位置就可以计算其他元素的存储位置
顺序表中元素存储位置的计算

如果每个元素占用8个存储单元,$a_i$ 存储位置是2000单元,则$a_{i+1}$存储位置是? 2008单元
假设线性表的每个元素需占i个存储单元,则第i+1个数据元素的存储位置和第i个数据元素的存储位置之间满足关系
$$
LOC(a_{i+1}) = LOC(a_i)+i
$$
由此,所有数据元素的存储位置均可由第一个数据元素的存储位置得到
$$
LOC(a_i) = LOC(a_i)+(i-1)×i
$$
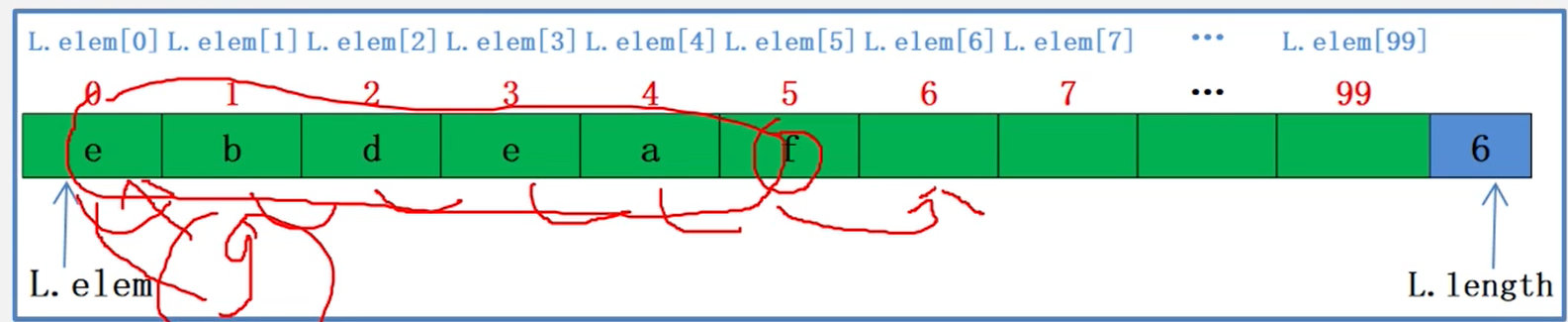
线性表的顺序存储表示


图书表的顺序存储结构类型定义
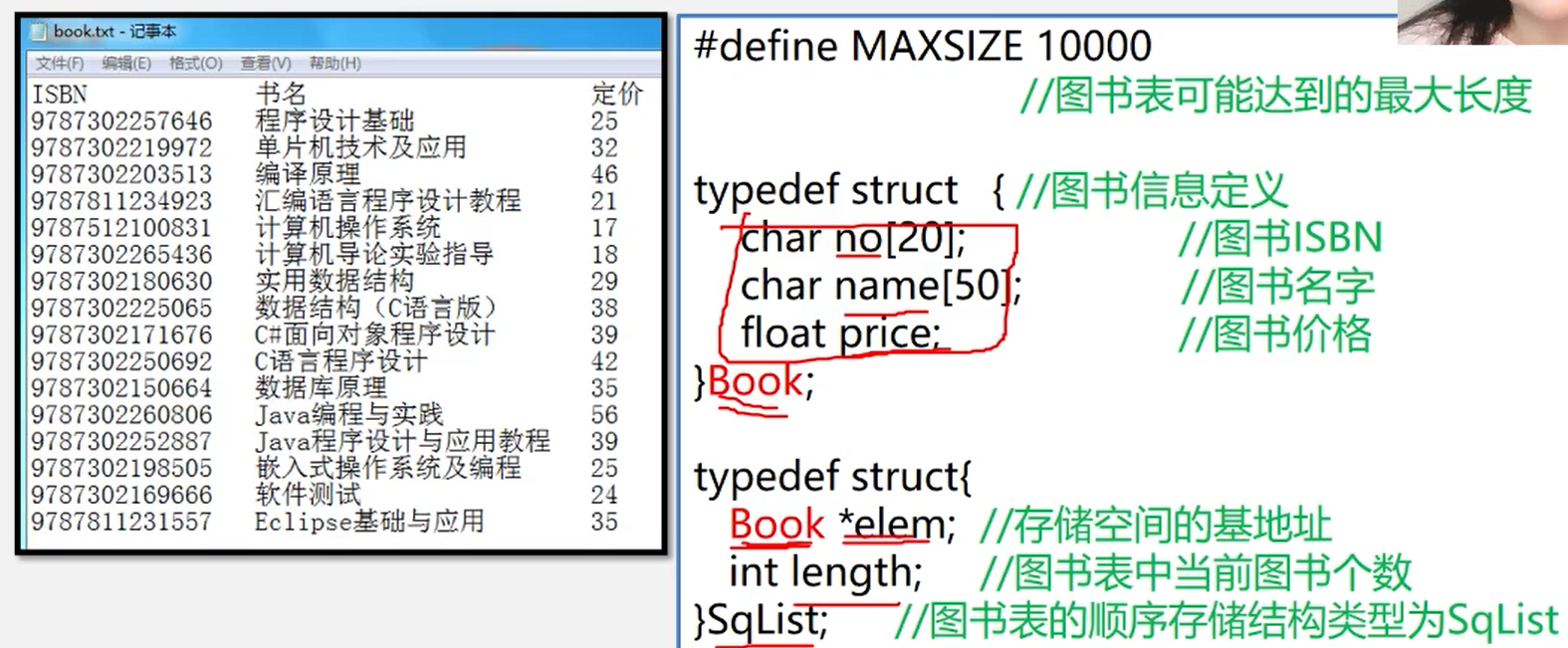
public class BookList {
int lenth;
Book[] book;
}
class Book{
Long ISBN;
String name;
float price;
}
顺序表示意图
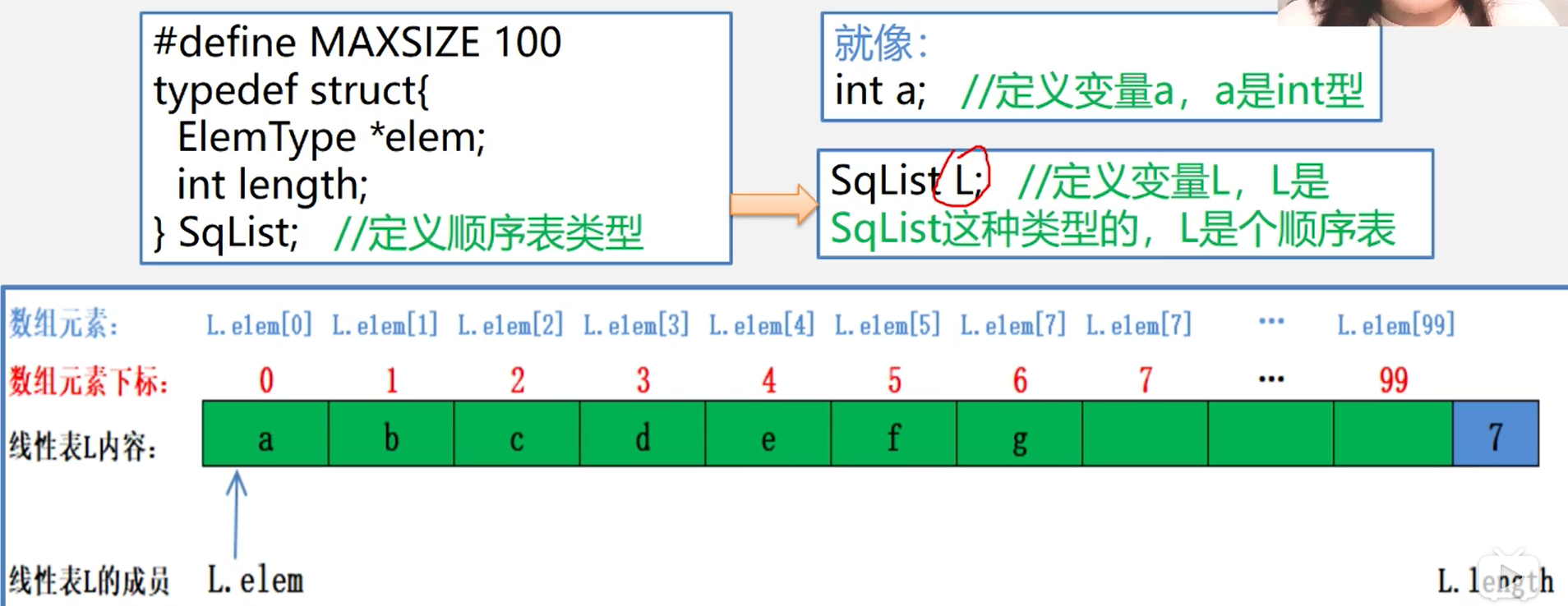
基本操作
初始化

public class BookList {
final int MAXSIZE = 20;
int lenth;
Book[] book;
BookList(){
book = new Book[MAXSIZE];
lenth = 0;
}
}
class Book{
Long ISBN;
String name;
float price;
}
销毁与清空线性表

public class BookList {
final int MAXSIZE = 20;
int lenth;
Book[] book;
BookList(){
book = new Book[MAXSIZE];
lenth = 0;
}
void DestroyList(){
book = null;
}
}
class Book{
Long ISBN;
String name;
float price;
}
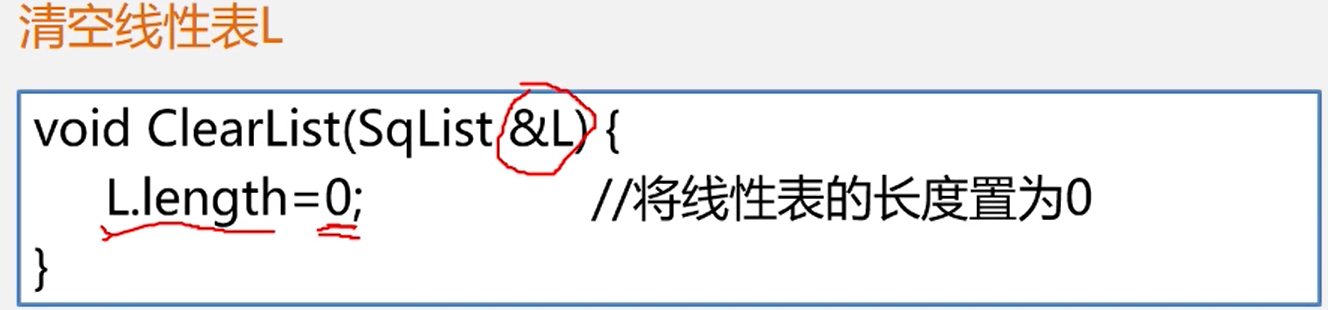
void clearList(){
lenth = 0;
}
求线性表长度
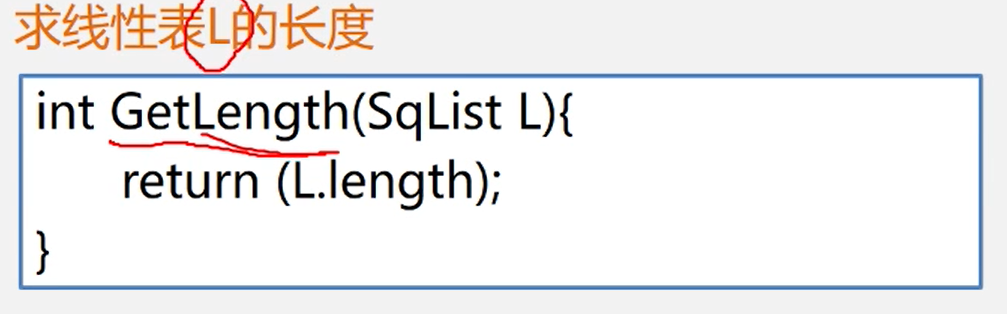
int getLenth(){
return lenth;
}
判断线性表是否为空
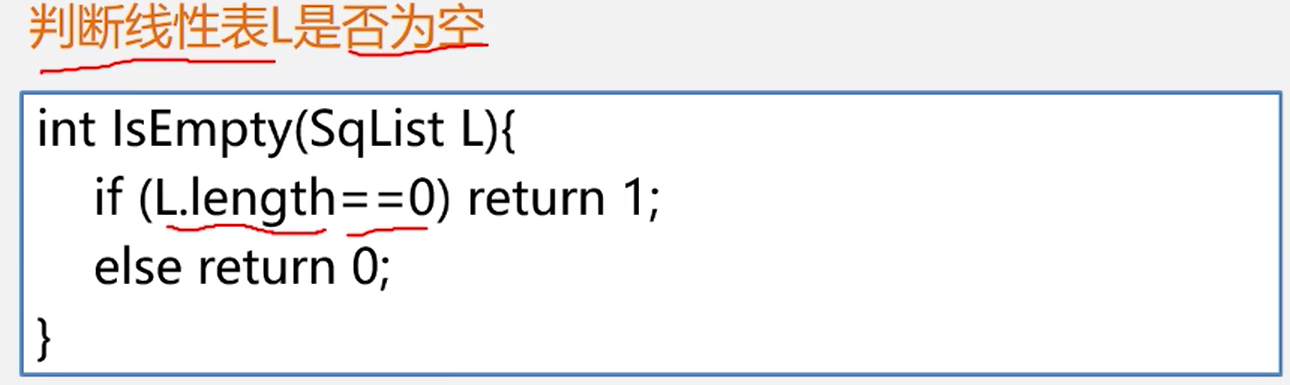
boolean isEmpty(){
return lenth == 0 ? true : false ;
}
顺序表的取值
 、
、
//根据位置获得元素
Book getElem(int i){
if (i<1||i>lenth) //判断位置是否合理
throw new ArrayIndexOutOfBoundsException();
return book[i-1]; //第i-1的单元存储这第i个数据
}
顺序查找
例如:在图书表中,按照给定书号进行查找,确定是否存在该图书如果存在:输出是第几个元素,如果不存在:输出0

- 在线性中查找与指定值 e 相同的数据元素的位置
- 从表的一端开始,逐个进行记录的关键字和给定值的比较,找到,返回该元素的位置序号,未找到,返回0

//查找元素
int locateElem(Book b){
for (int i = 0; i < book.length; i++) {
if (book[i] == b) return i+1;
}
return 0;
}
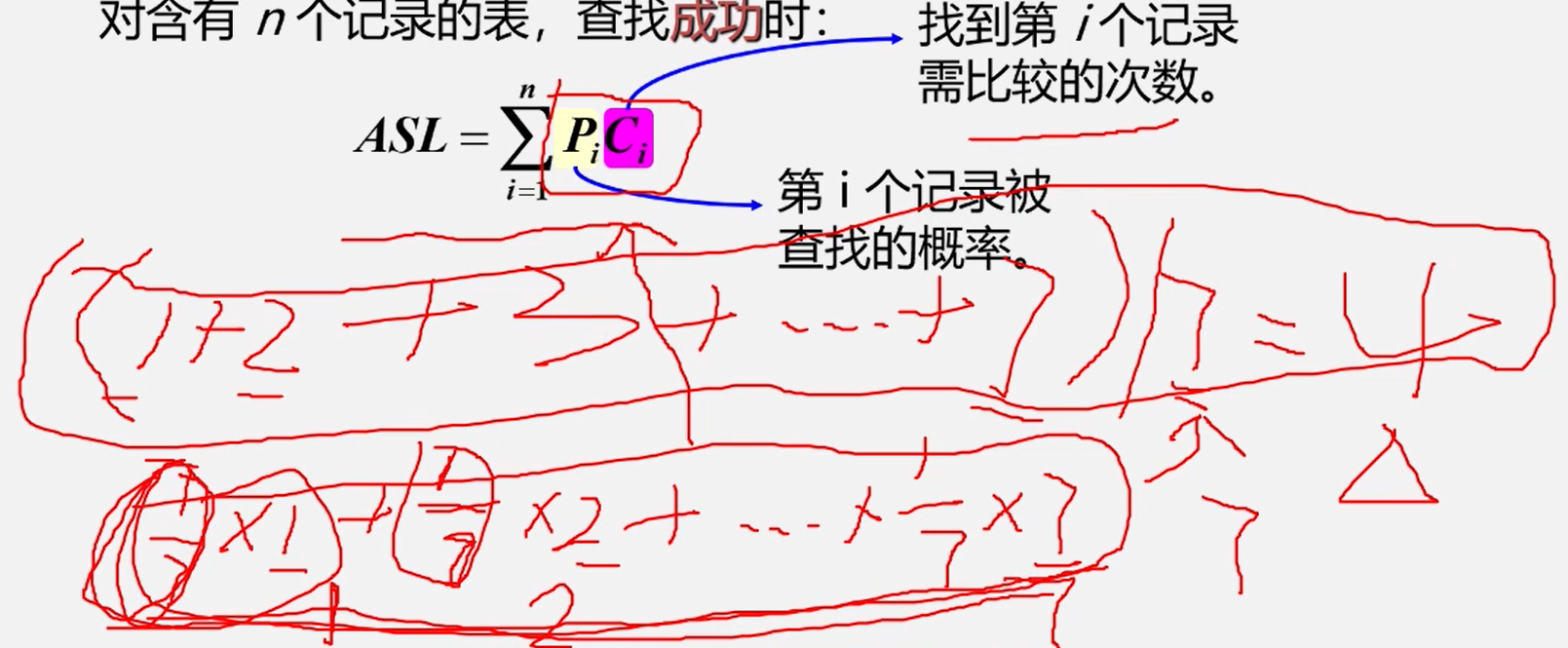
顶序表的查找算法分析:
平均查找长度AsL( Average Search Length)
- 为确定记录在表中的位置,需要与给定值进行比较的关键字的个数的期望值叫做查找算法的
平均查找长度
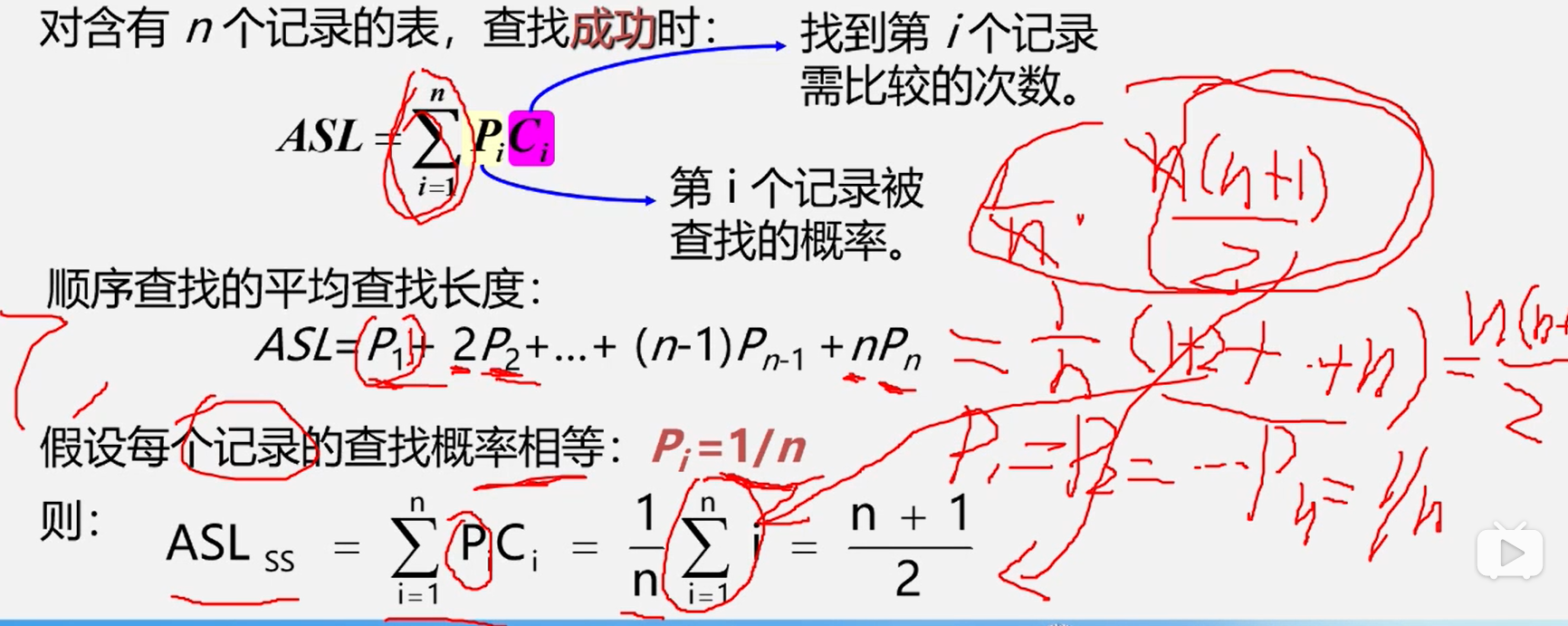
顺序表的插入
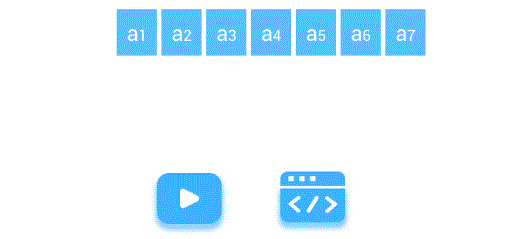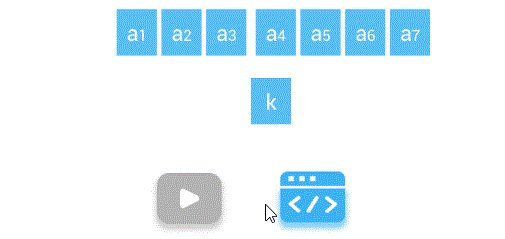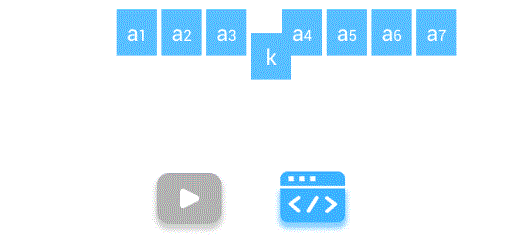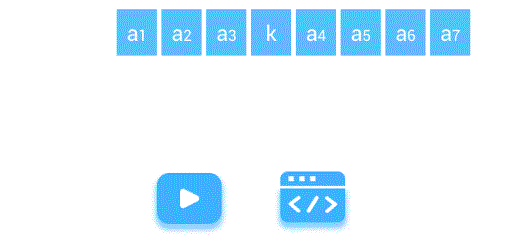
线性表的插入运算是指在表的第(1≤i≤η+1)个位置上,插入一个新结点e,使长度为η的线性表(a1,…,ai-1,ai,…,an)变成长度为n+1的线性表(a1,…,ai-1,e,ai,…an)
算法思想:
1、判断插入位置i是否合法。0~n
2、判断顺序表的存储空间是否已满,若已满返回 ERROR。
3、将第n至第i位的元素依次向后移动一个位置,空出第个位置。
4、将要插入的新元素e放入第i个位置。
5、表长加1,插入成功返回OK
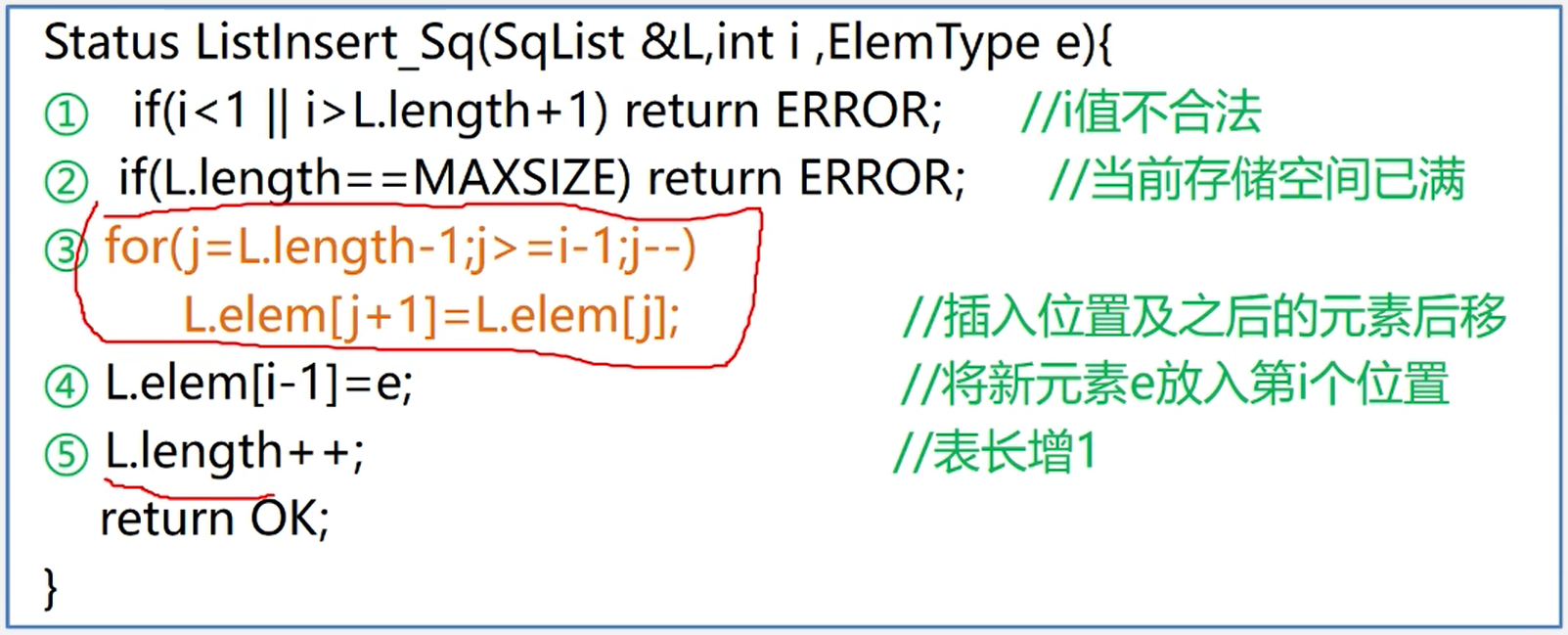
//插入元素
int listInsert(Book b , int i){
if (i<1 || i>lenth+1) throw new ArrayIndexOutOfBoundsException(); //判断插入位置是否合法
if (lenth == MAXSIZE) throw new RuntimeException(); //当前存储空间已满
for (int j = lenth-1; j>lenth-1; j--){
book[j+1] = book[j]; //插入位置及之后的元素后移
}
book[i-1] = b; //将元素e放到第i个位置
lenth++; //表增长
return Const.OK;
}
顺序表插入的算法分析
- 若插入在尾结点之后,则根本无需移动(特别快)
- 若插入在首结点之前,则表中元素全部后移(特别慢)
- 若要考虑在各种位置插入(共n+1种可能)的平均移动次数,该如何计算
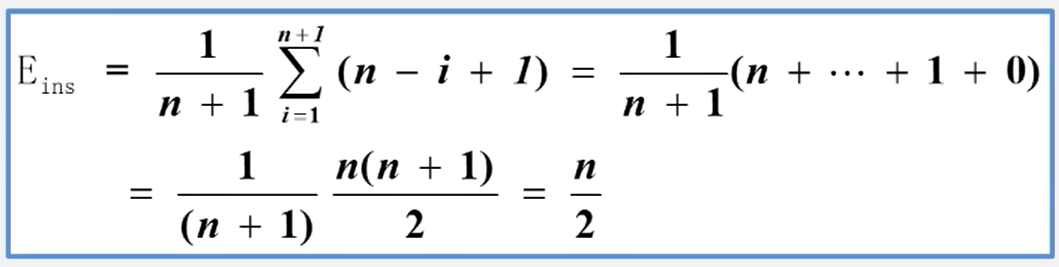
顺序表插入算法的平均时间复杂度为O(n)
顺序表的删除

①判断删除位置是否合法(合法值为1s≤n)
②将额删除的五素保留在e
③将第+1至第位的元素依次向移动个位置。
④表长减1,删除成功返回○K

//删除元素
int listDelete(int i){
if (i<1 || i>lenth) throw new ArrayIndexOutOfBoundsException(); //判断删除位置是否合法
for (int j = i;j<=lenth-1;j++){
book[j-1] = book[j];
}
lenth--;
return Const.OK;
}

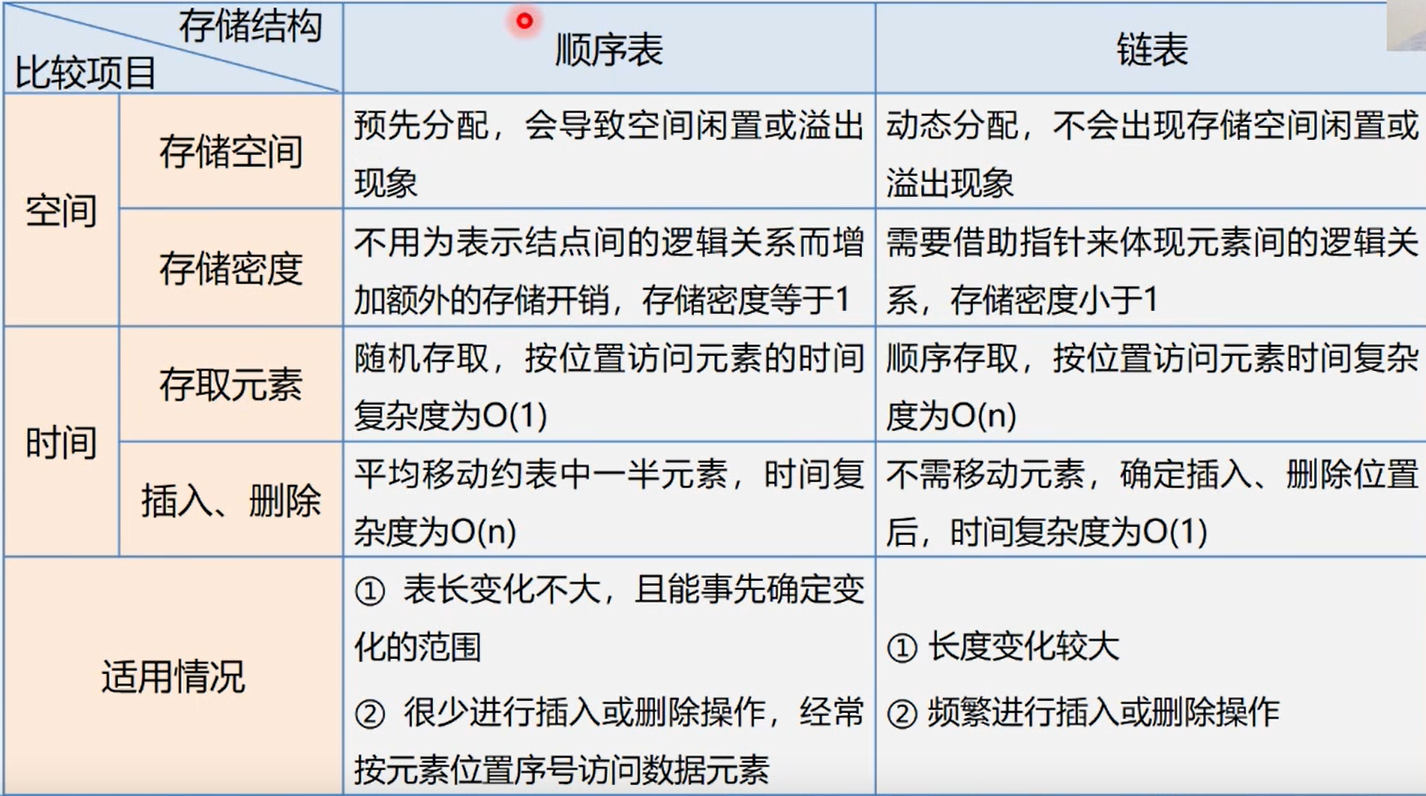
顺序表优缺点
优点:
- 存储密度大(结点本身所占存储量/结点结构所占存储量)
- 可以随机存取表中任一元素
缺点:
- 在插入、删除某一元素时,需要移动大量元素
- 存储空间不灵活
- 属于静态存储形式,数据元素的个数不能自由扩充
2.5线性表的链式表示和实现
定义
结点在存储器中的位置是任意的,即逻辑上相邻的数据元素在物理上不一定相邻。
线性表的链式表示又称为非顺序映像或链式映像。
用一组物理位置任意的存储单元来存放线性表的数据元素。
这组存储单元既可以是连续的,也可以是不连续的,甚至是零散分布在内存中的任意位置上的。
链表中元素的逻辑次序和物理次序不一定相同。
特点
(1)结点在存储器中的位置是任意的,即逻辑上相邻的数据元素在物理上不一定相邻。
(2)访问时只能通过以指针进入链表)并通过每个结点的指针域依次向后顺序扫描其余结点,所以寻找第一个结点和最后一个结点所花费的时间不等--这种存取元素的方法被称为顺序存取法
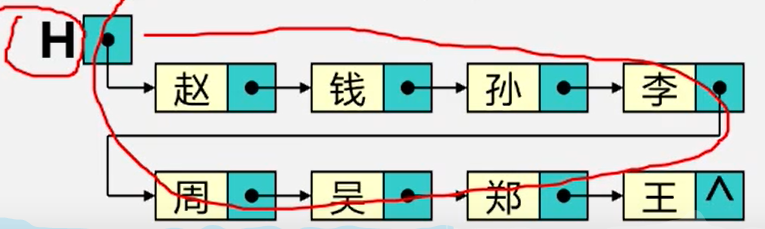
例子1,姓表
例:线性表:(赵,钱,孙,李,周,吴,郑,王)

例子2,字母表
26个英文小写字母表的链式存储结构


各结点由两个域组成:
- 数据域:存储元素数值数据
- 指针域:存储直接后继结点的存储位置

术语
1、结点:
数据元秦的存储映像。由数据域和指针域两部分组成
2、链表:
n个结点由指针链组成一个链表。它是线性表的链式存储映像,称为线性表的链式存储结构

3、单链表、双链表、循环链表
结点只有一个指针域的链表,称为单链表或线性链表

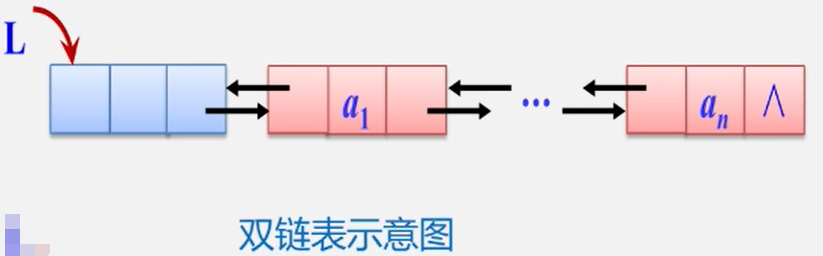
结点有两个指针域的链表,称为双链表
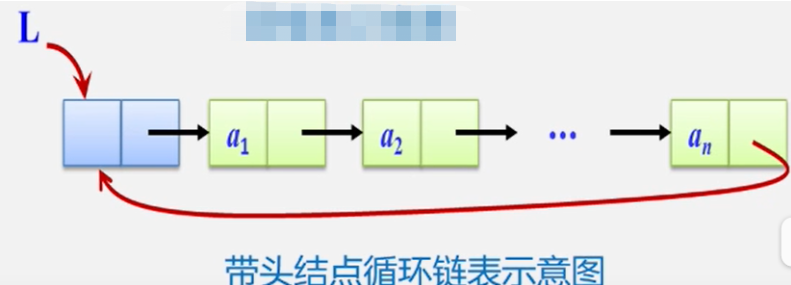
首尾相接的链表称为循环链表
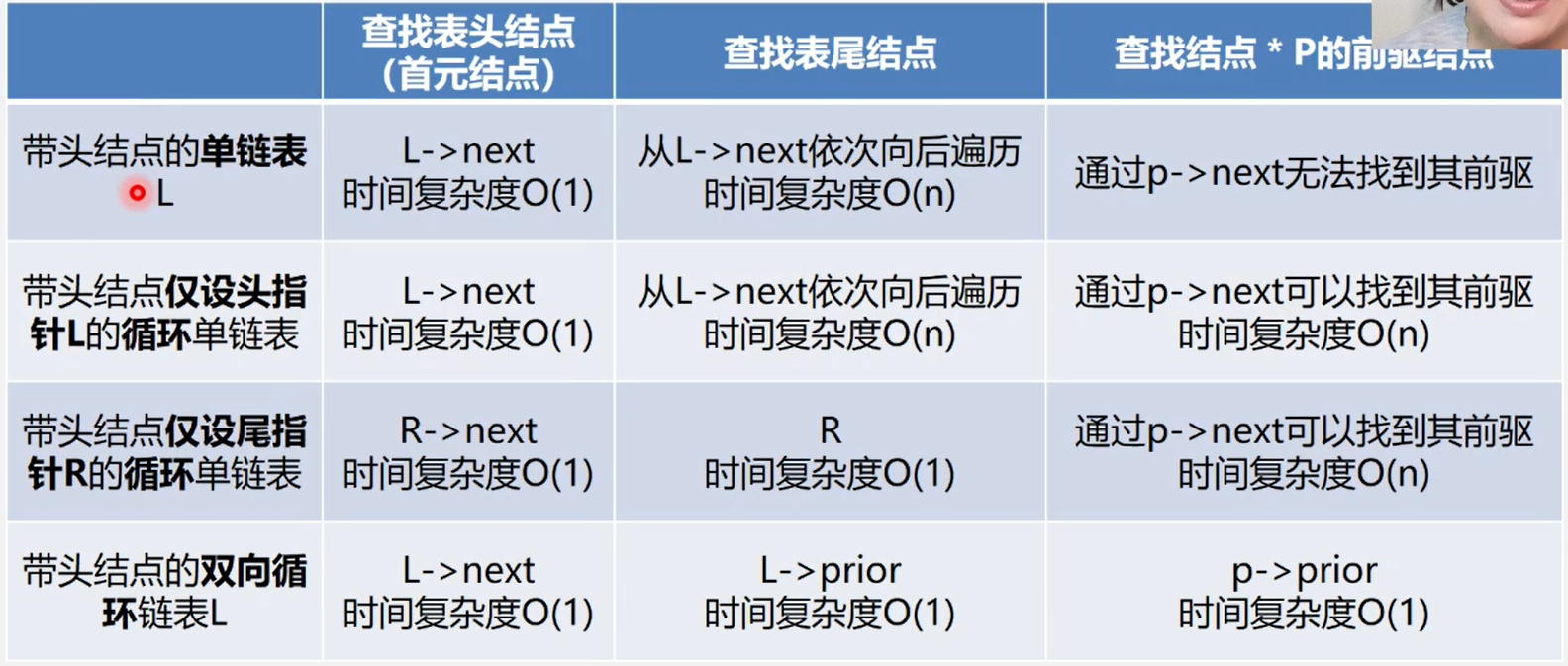
4、头指针、头结点和首元结点:

头指针:是指向链表中第一个结点的指针
首元结点:是指链表中存储第一个数据元素a的结点
头结点:是在链表的首元结点之前附设的一个结点;
前面的例子中的链表的存储结构示意图有以下两种形式
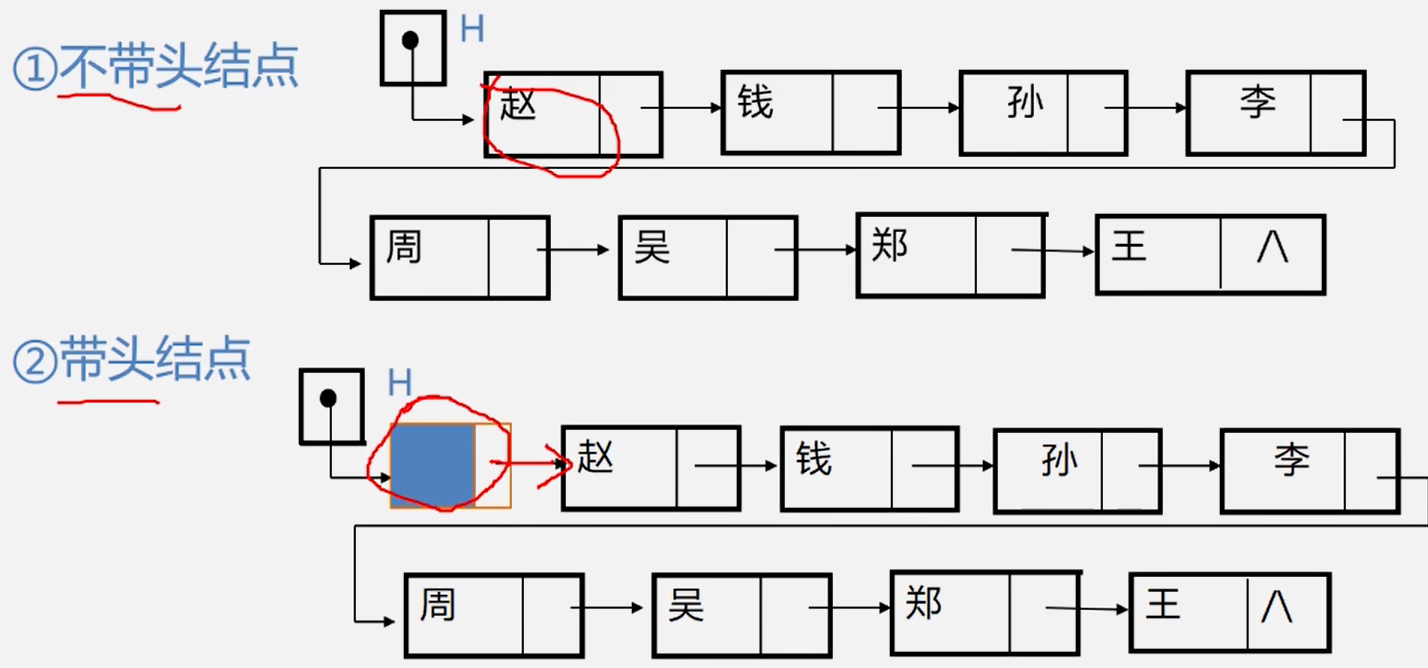
讨论:如何表示空表
无头结点时,头指针为空时表示空表
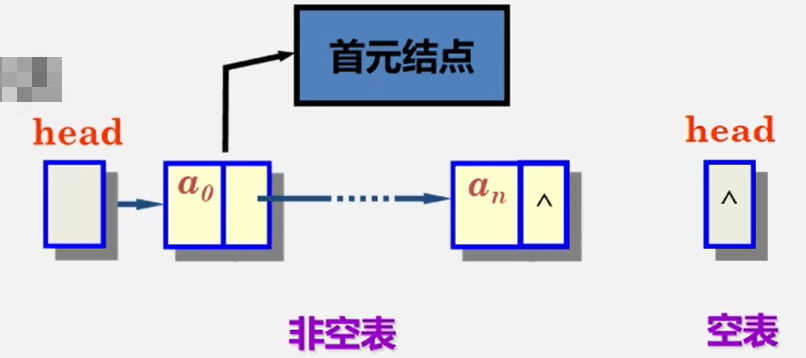
有头结点时,当头结点的指针域为空时表示空表
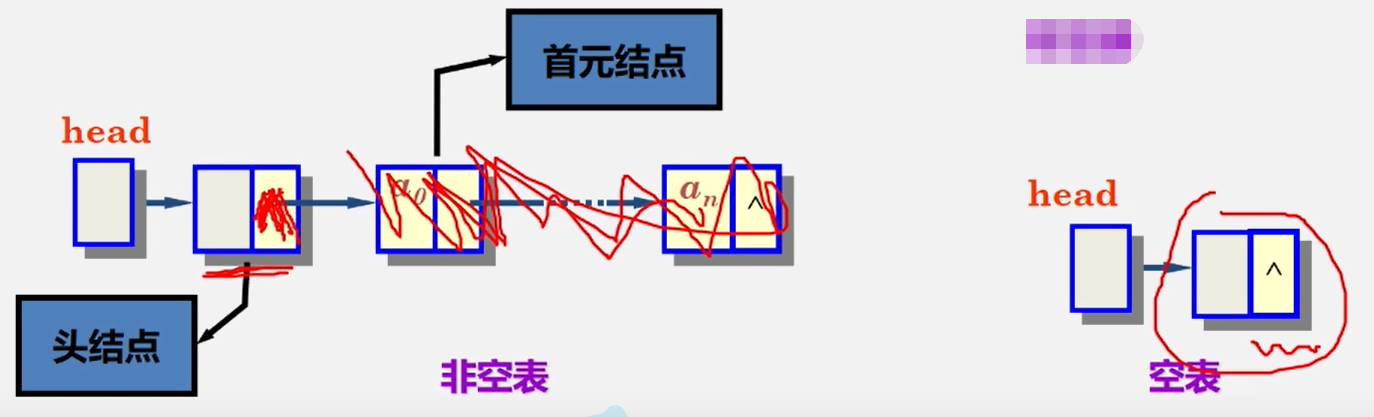
讨论2:在链表中设置头结点有什么好处?
1、便于首元结点的处理首元结点的地址保存在头结点的指针域中,所以在链表的第一个位置上的操作和其它位置一致,无须进行特殊处理;
2、便于空表和非空表的统一处理无论链表是否为空,头指针都是指向头结点的非空指针,因此空表和非空表的处理也就统一了。
讨论3:头结点的数据域内装的是什么?
头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值。
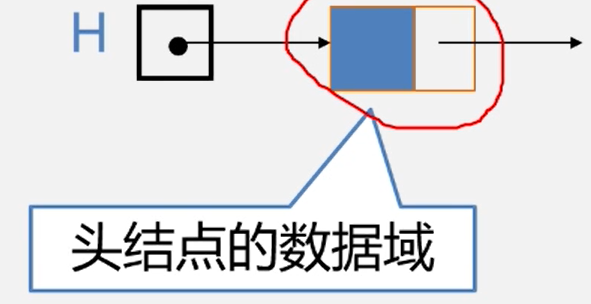
带头结点的单链表
单链表是由表头唯一确定,因此单链表可以用头指针的名字来命名, 若头指针名是L,则把链表称为表L

存储结构
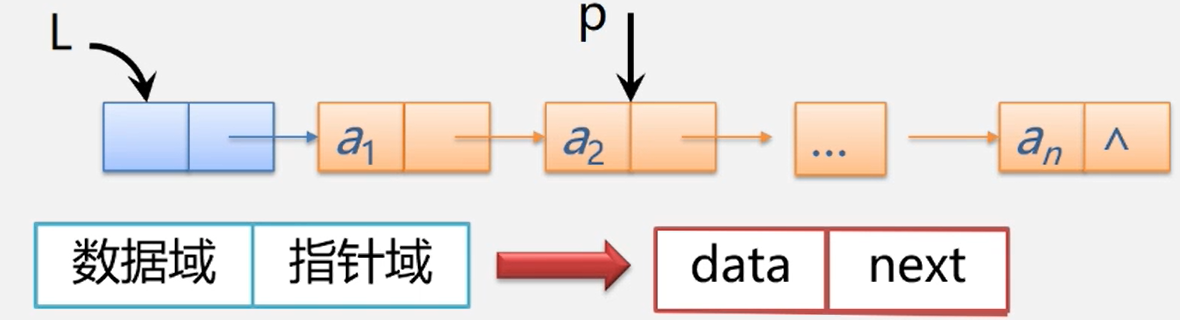


例子:学生信息
存储学生学号、姓名、成绩的单链表结点类型定义如下:

为了统一链表的操作,通常这样定义

public class LinkList {
private static class Node{
Student student;
Node next;
public Node(Student student, Node next) {
this.student = student;
this.next = next;
}
}
Node head;
int size;
LinkList(){
}
}
class Student{
String name;
int score;
}
单链表基本操作
初始化
生成新结点作头结点,用头指针指向头结点。
将头结点的指针域置空。
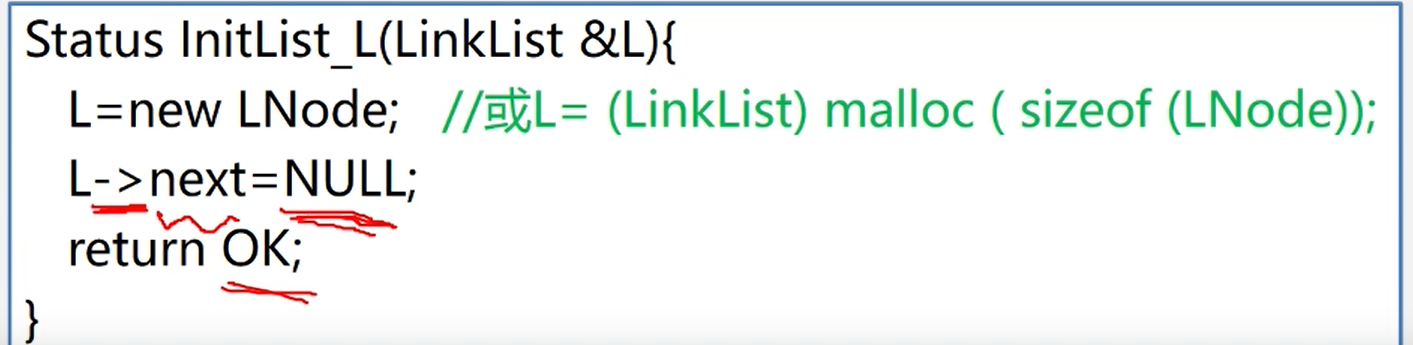
LinkList(){
size = 0;
}
判断链表是否为空
空表:链表中无亓素,称为空链表(头指针和头结点仍然在
算法思路:判断头绩点指针域是否为空


boolean listEmpty(){
return head.next == null ? true : false;
}
单链表的销毁:链表销毁后不存在

销毁链表没有java实现
清空链表
链表仍存在,但链表中无元素,成为空链表(头指针和头结点仍然在)
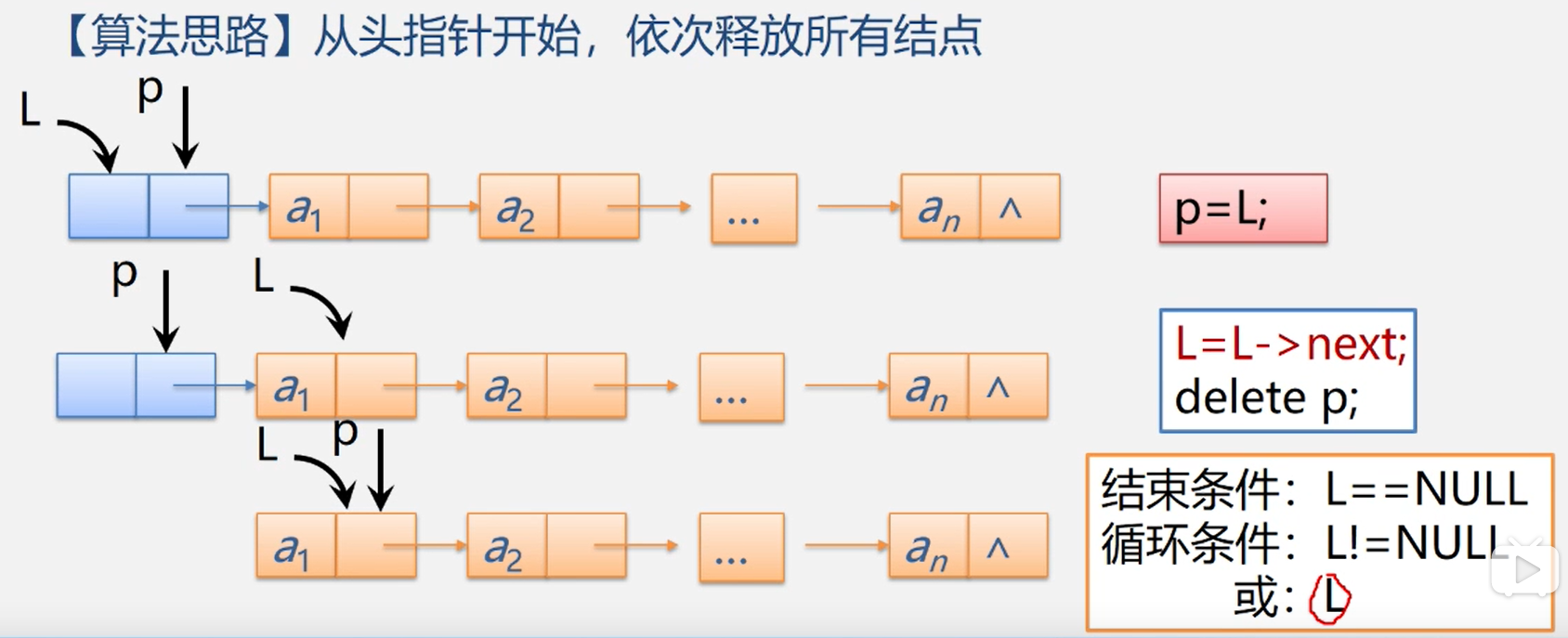
【算法思路】依次释放所有结点,并将头结点指针域设置为空

void clear(){
Node temp = head;
while (temp != null){
Node next = temp.next;
temp.next = null;
temp.student = null;
temp = next;
}
size = 0;
}
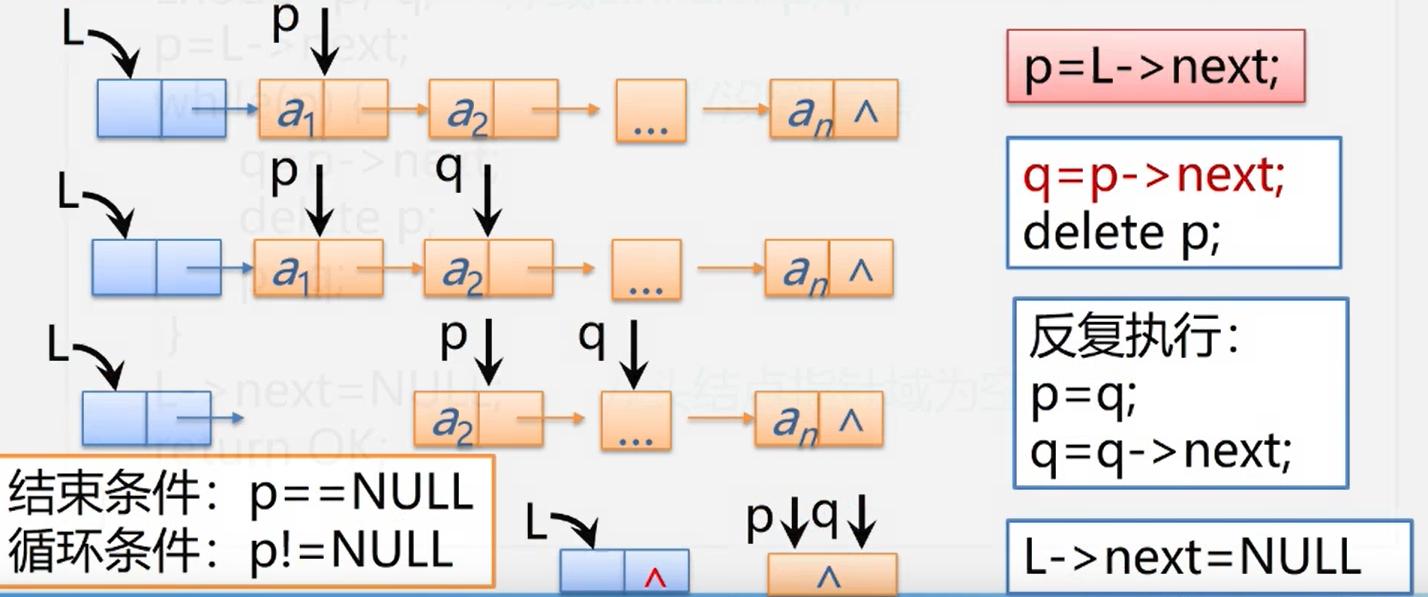
求单链表的表长
int size(){
int num = 0;
Node temp = head.next;
while (temp != null){
Node next = temp.next;
temp = next;
num++;
}
return num;
}
取值--取单链表第i个元素的内容
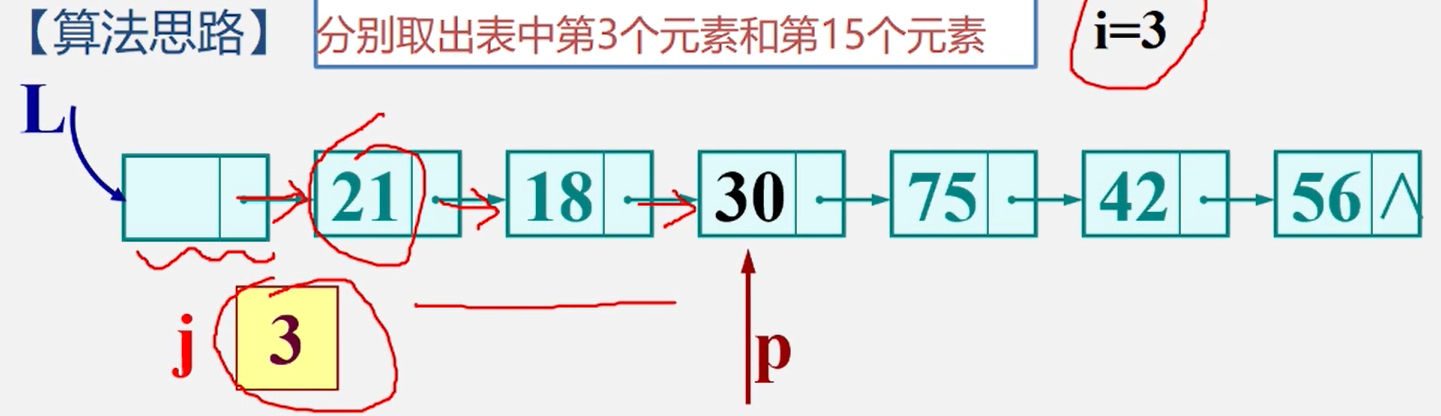
从链表的头指针岀发,顺着链域next逐个结点往下搜索,直至搜索到第i结点为止。因此,链表不是随机存取结构。
【算法步骤】
1、从第1个结点(L->next)顺链扫抽,用指针p指向当前扫描到的结点,p初值p=L->next
2.j做计数器,累计当前扫描过的结点数,j初值为1
3.当p指向扫描到的下一结点时,计数器j加1。
4当j=i时,p指的结点就是要找的第i个结点
【算法描述】

Student getElem(int i){
int index = 1;
Node temp = head.next;
while (temp != null && index < i){
temp = temp.next;
index++;
}
if (temp.next != null) return temp.student;
return null;
}
按值查找—根据指定数据获取该数据所在的位置(地址)

【算法步骤】
1.从第一个结点起,依次和e相比较。
2如果找到一个其值与e相等的数据元素,则返回其在链表中的/位置或地址;
3如果查遍整个链表都没有找到其值和e相等的元素,则返回0或NULL
【返回地址算法】

//查找元素
Student findElem(Student s){
Node temp = head.next;
while (temp != null && temp.student != s){
temp = temp.next;
}
return temp.student;
}
按值查找根据指定数据获叹该数据位置序号

//查找元素的位置序号
int indexof(Student s){
int index = 1;
Node temp = head.next;
while (temp != null && temp.student != s){
temp = temp.next;
index ++;
}
return temp==null ? 0 : index;
}
插入—在第个结点前插入值为e的新结点

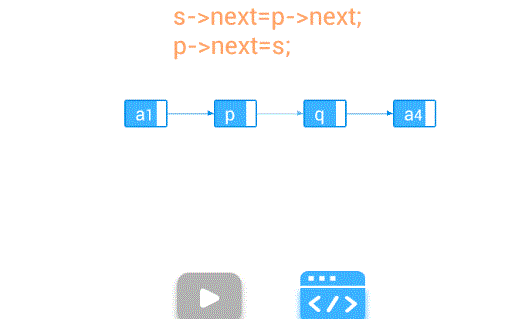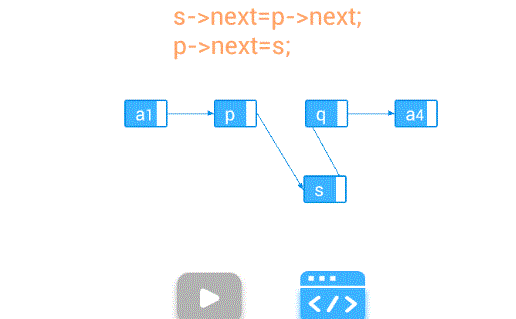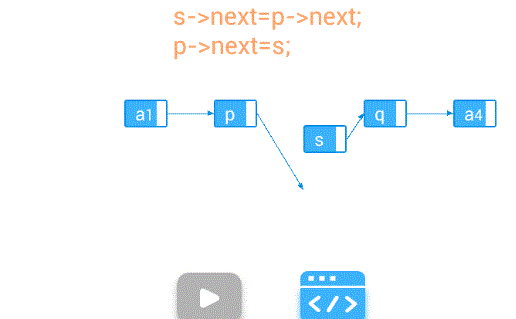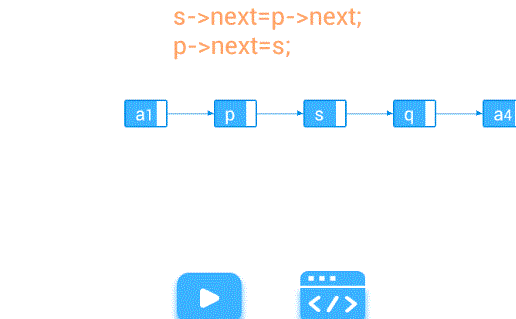
【算法步骤】


//插入节点
void set(int i , Student s){
Node p = head.next ; int index = 1;
while (p != null && index < i-1){
p = p.next;
index++;
}
if(p!=null){
Node node = new Node(s, p.next);
p.next = node;
}
}
删除—删除第个结点
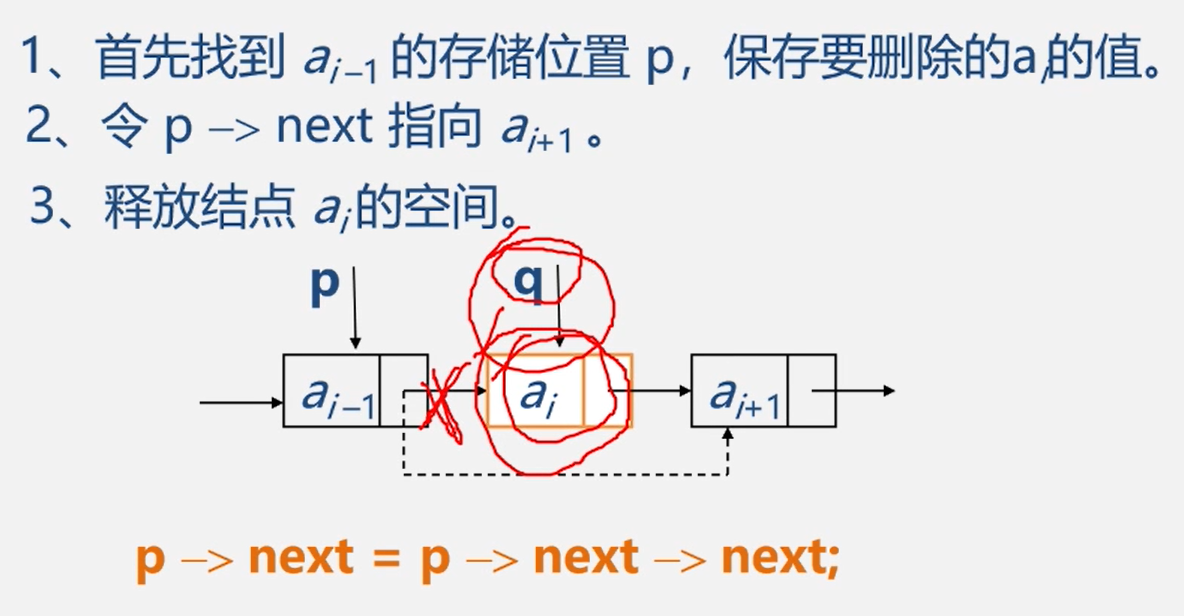
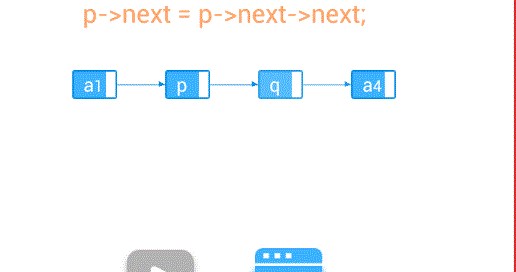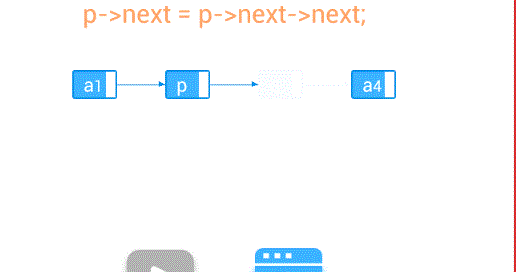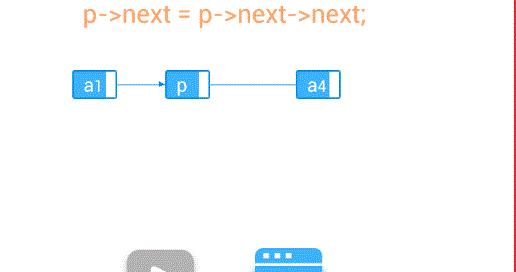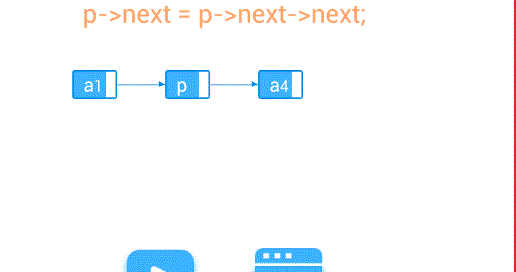

//删除节点
void delete(int i){
Node p = head.next ;int index = 1;
while (p != null && index < i-1){
p = p.next;
index++;
}
if(p.next!=null){
p.next = p.next.next;
}
}
单链表的查找、插入、删除算法时间效率分析
1、查找
因线性链表只能顺序存取,即在査找时要从头指针找起,查找的时间复杂度为O(n)
2、插入和删除
- 因线性链表不需要移动元素,只要修改指针,一般情况下时间复杂度为O(1)
- 但是,如果要在单链表中进行前插或删除操作,由于要从头查找前驱结点,所耗时间复杂度为O(n)
头插法
建立单链表:头插法——元素插入在链表头部,也叫头插法
1、从一个空表开始,重复读入数据;
2、生成新结点,将读入数据存放到新结点的数据域中
3、从最后一个结点开始,依次将各结点插入到链表的前端
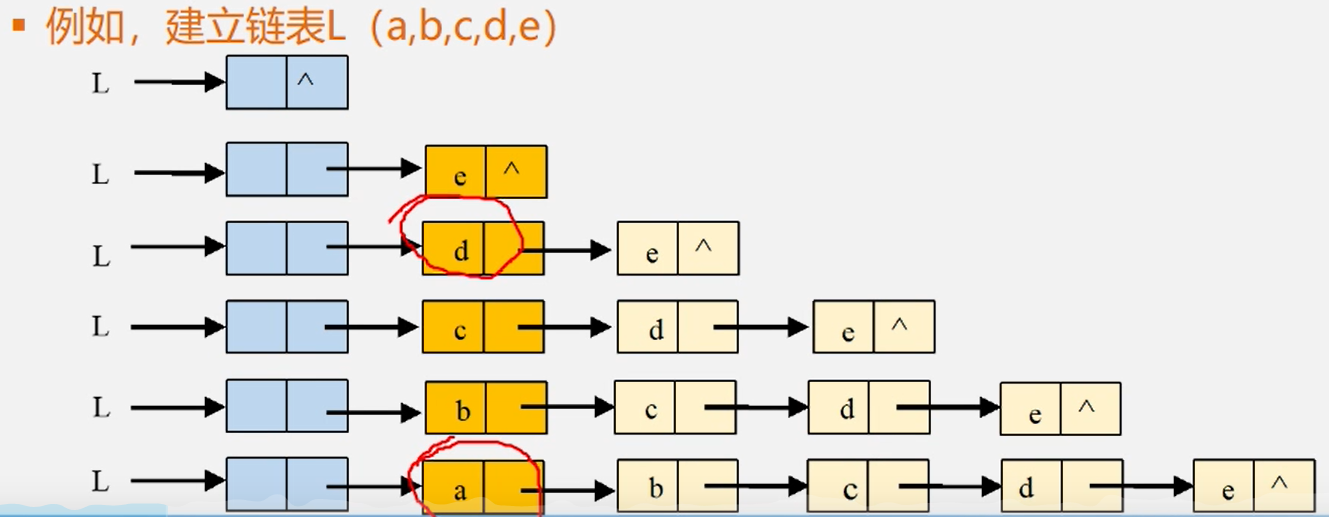
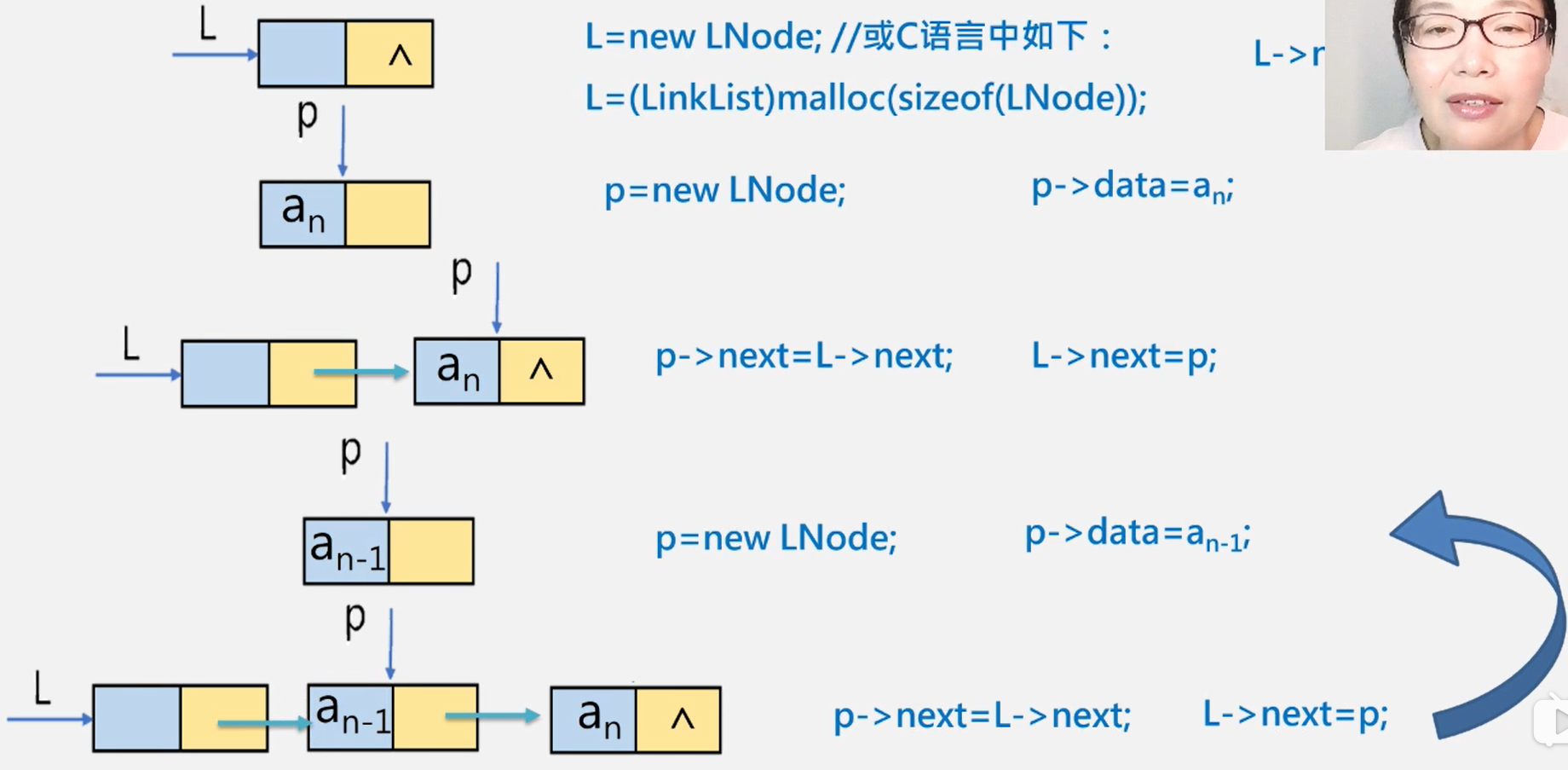
【算法描述】
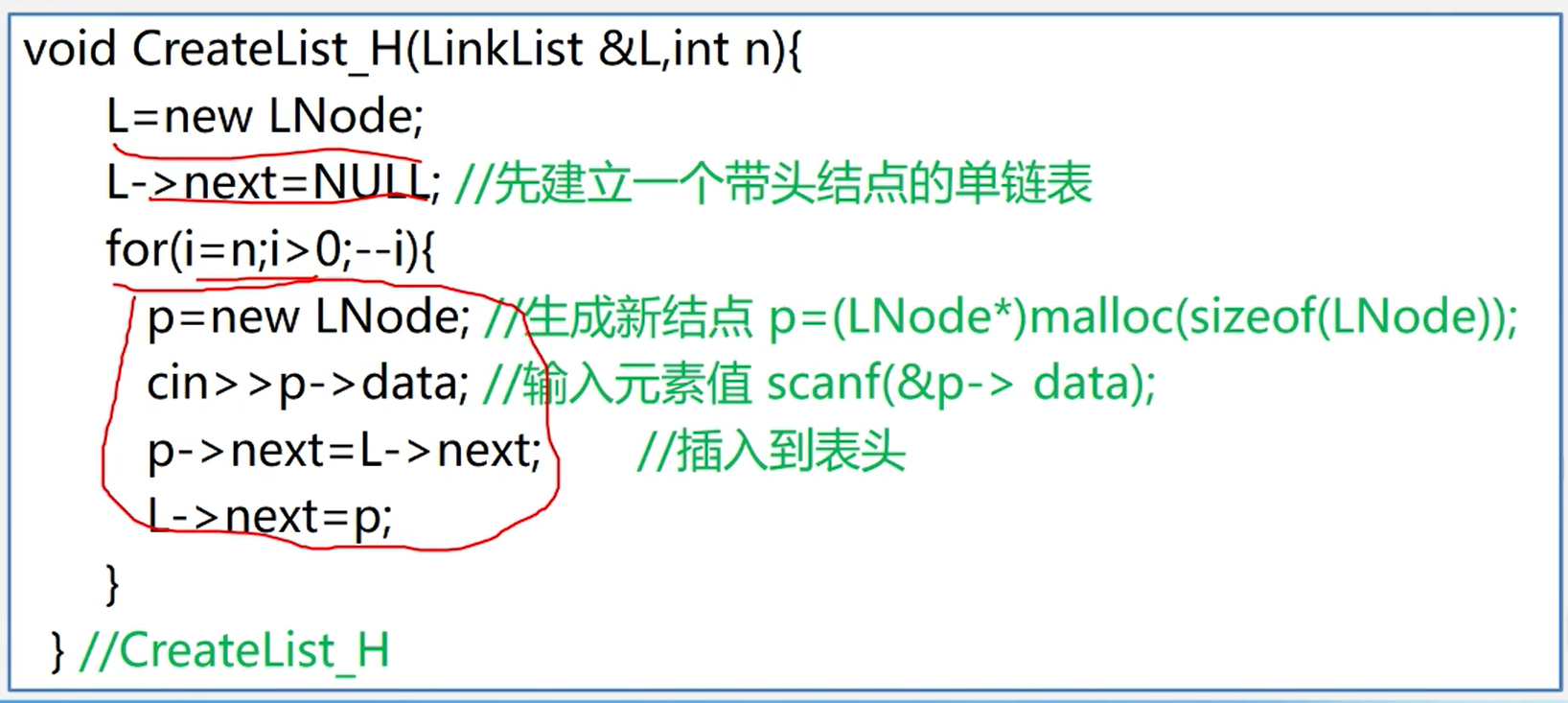
//头插法
void createList(int n){
head.next = null;
head = new Node();
for (int i = n; i > 0; i--) {
Node node = new Node();
node.next = head.next;
head.next = node;
}
}
尾插法
建立单链表尾插法元素插入在链表尾部,也叫后插法
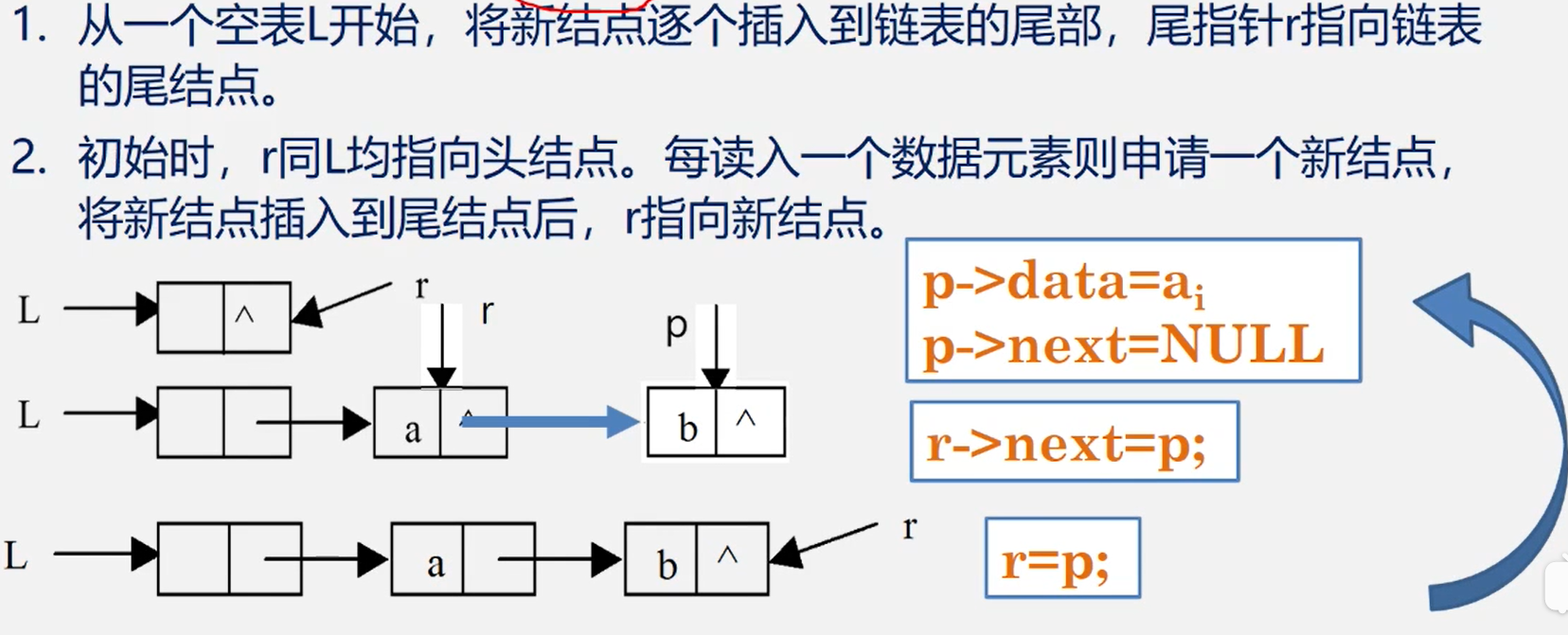
//尾插法
void createListEnd(int n){
head.next = null;
head = new Node();
Node end = head;
for (int i = 0; i < n; i++) {
Node node = new Node();
end.next = node; //插入表尾
node.next = null;
end = node; //end指向新的节点
}
}
循环链表
循环链表:是一种头尾相接的链表(即:表中最后一个结点的指针域指向头结点,整个链表形成一个环)
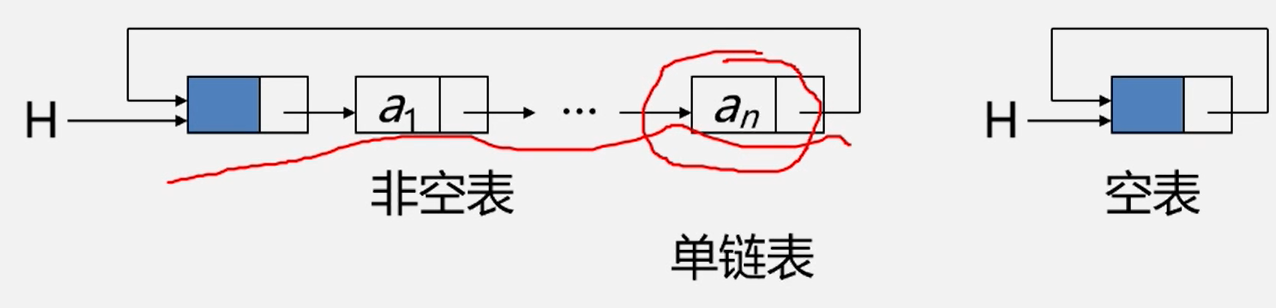
优点:
- 从表中任意一节点出发均可找到表中其他节点。
- 适合频繁操作首尾节点的情况
注意:由于循环链表中没有NUL指针,故涉及遍历操作时,其终止条件就不再像非循环链表那样判断p或p→>next是否为空,而是判断它们是否等于头指针。


循环链表操作
带尾指针循环链表的合并(将Tb合并在Ta之后)
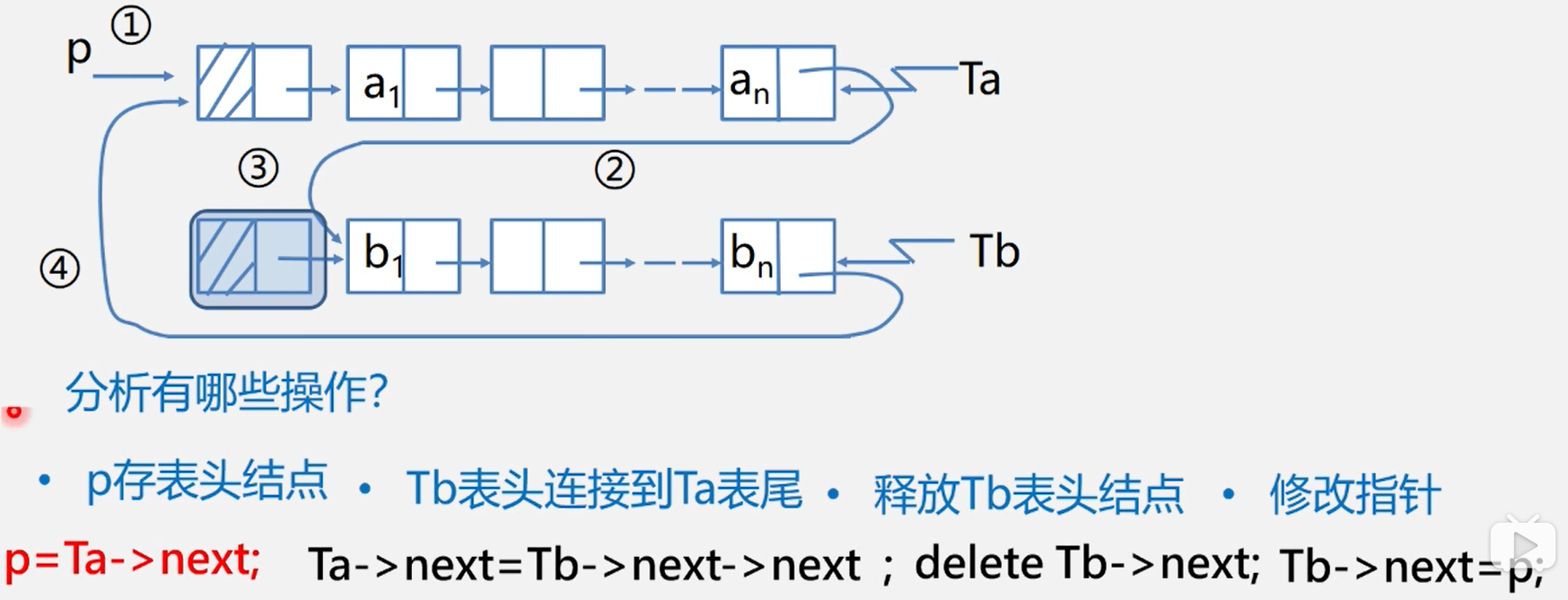

双向链表
为什么要讨论双向链表?
单链表的结点--》有指示后继的指针域一找后继结点方便
即:查找某结点的后继结点的执行时间为 O(1)
→无指示前驱的指针域一找前驱结点难
即:查找某结点的前驱结点的执行时间为O(n)
双向链表:在单链表的每个结点里再增加一个指向其直接前驱的指针域 prior,这样链表中就形成了有两个方向不同的链,故称为双向链表。
也就是在node中添加了一个指向前驱节点的指针地址。
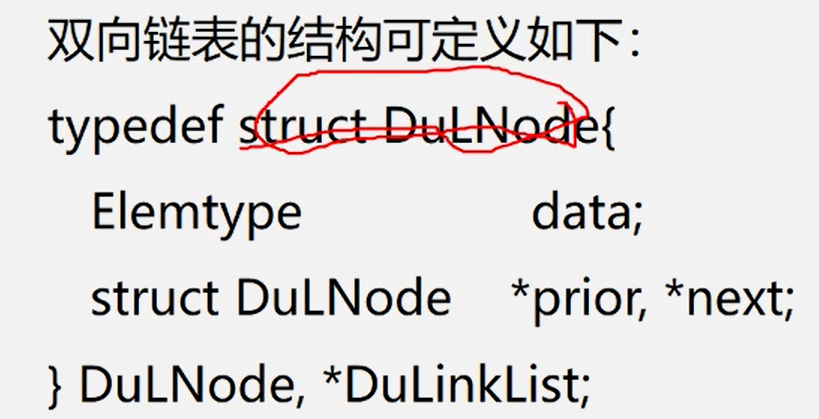

双向链表结构__空表与非空表

双向循环链表
和单链的循环表类似,双向链表也可以有循环表
- 让头结点的前驱指针指向链表的最后一个结点
- 让最后一个结点的后继指针指向头结点。

双向链表的对称性

在双向链表中有些操作(如:listLength、 GetElem等),因仅涉及一个方向的指针,故它们的算法与线性链表的
相同。但在插入、删除时,则需同时修改两个方向上的指针,两者的操作的时间复杂度均为O(n)。
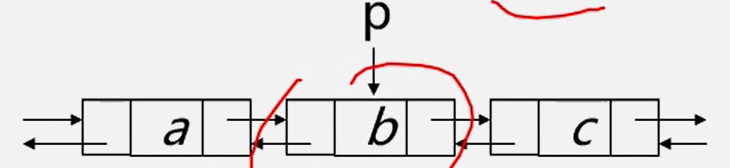
public class DuLinkedList {
class DuNode{
int data;
DuNode prior; //上一节点
DuNode next; //下一节点
}
DuNode head; //头节点
DuLinkedList(){
head = new DuNode();
head.prior = head;
head.next = head;
}
}
双向链表的插入


//获得第几个元素
DuNode getElem(int i){
int index = 1;
DuNode temp = head.next;
while (temp != null && index < i){
temp = temp.next;
index++;
}
if (temp.next != null) return temp;
return null;
}
//插入
boolean add(String data , int i){
DuNode p = getElem(i);
if (p!=null){
DuNode s = new DuNode();s.data = data;
s.prior = p.prior;
s = p.prior.next;
s.next = p;
p.prior = s;
return true;
}else {
return false;
}
}
双向链表的删除


//删除
boolean remove(int i){
DuNode p = getElem(i);
if (p!=null){
p.prior.next = p.next;
p.next.prior = p.prior;
return true;
}else {
return false;
}
}
2.6顺序表和链表的比较
典型操作时间效率的比较
链式存储结构优缺点
链式存储结构的优点:
- 结点空间可以
动态申请和释放; - 数据元素的逻辑次序靠结点的指针来指示,
插入和删除时不需要移动数据元素。
链式存储结构的缺点:
存储密度小,每个结点的指针域需额外占用存储空间。当每个结点的数据域所占字节不多时,指针域所占存储空间的比重显得很大。- 链式存储结构是
非随机存取结构。对任结点的操作都要从头指针依指针链査找到该结点,这增加了算法的复杂度。
顺序表和链表的选择
存储密度
存储密度是指结点数据本身所占的存储量和整个结点结构中所占的存储量之比,即:

例如:

一般地,存储密度越大,存储空间的利用率就越高。显然,顺序表的存储密度为1(100%),而链表的存储密度
小于1。
2.7线性表的应用
线性表的合并
假设利用两个线性表La和Lb分别表示两个集合A和B现要求一个新的集合R=AUB

算法步骤
1、依次取出Lb中的每个元素,在La中查找该元素。
2、如果找不到,则将其插入La的最后

//线性表的合并
void union(LinkedList list){
int asize = size();//当前链表长度
int bsize = list.size();
for (int i = 1; i < bsize; i++) {
int elem = list.getElem(i);
if (getElem(elem)!=0) set(asize+1,elem);
}
}

有序表合并-顺序表实现
已知线性表La和Lb中的数据元素按值非递减有序排列,现要求将La和Lb归并为一个新的线性表Lc,且Lc中的数据元素仍按值非递减有序排列。

算法步骤
1、创建一个空表Lc
2、依次从La或Lb中摘取”元素值较小的结点插入到Lc表的最后,直至其中一个表变空为止
3、继续将La或Lb其中一个表的剩余结点插入在Lc表的最后
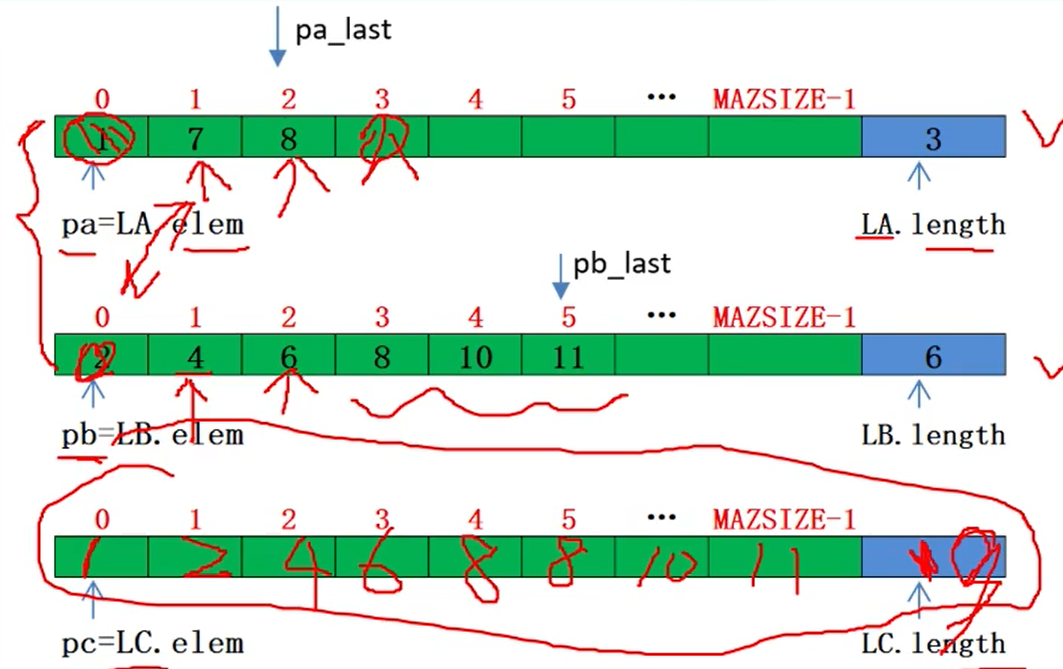
//合并线性表
IntList mergeList(IntList b){
IntList intList = new IntList(b.length + length);
//创建两个指针
int aList = 0;
int bList = 0;
loop:while (true){
//当一个表空了
if (aList == length || bList == b.length){
break loop;
}
if (data[aList] < b.data[bList]){
intList.add(data[aList]);
aList++;
}else {
intList.add(b.data[bList]);
bList++;
}
}
//如果a表空了
for (int i = bList; i < b.length; i++) {
intList.add(b.data[i]);
}
//如果b表空了
for (int i = aList; i < length; i++) {
intList.add(data[i]);
}
return intList;
}

个人认为时间复复杂度取决于最长的表。
有序表合并-链表实现‘
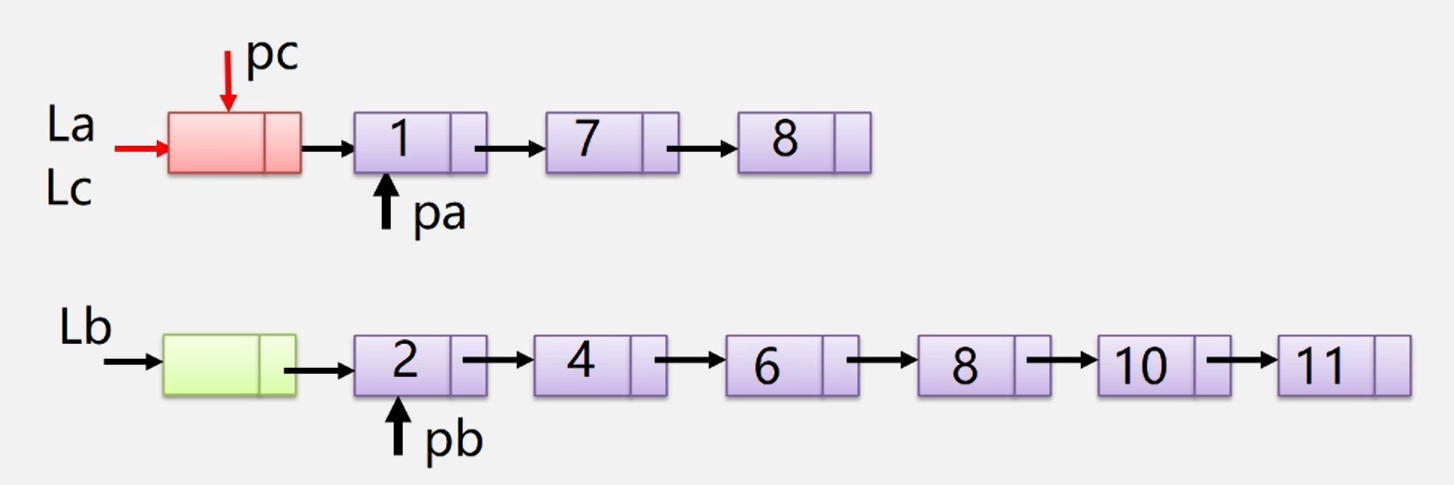


//递归法
public static Node mergeTwoLists(Node l1, Node l2) {
if (l1 == null) {
return l2;
}
if (l2 == null) {
return l1;
}
Node mergedNode;
if (l1.data < l2.data) {
mergedNode = l1;
mergedNode.next = mergeTwoLists(l1.next, l2);
} else {
mergedNode = l2;
mergedNode.next = mergeTwoLists(l2.next, l1);
}
return mergedNode;
}
public static Node merge(Node list1,Node list2){
//空判断 如果有一个为空则 返回另一个链表
if(list1==null)
return list2;
else if(list2==null)
return list1;
Node newHead=null; //结果节点
Node tmp=null; //临时指针
//往新链表一个个添加节点 直至有一个链表为空
//tmp存放最后一个添加进新链表的节点 用于后续的拼接
while(list1!=null&&list2!=null){
if(list1.data<list2.data){
if(newHead==null){
newHead=tmp=list1;
}else{
tmp.next=list1;
tmp=tmp.next;
}
list1=list1.next;
}else{
if(newHead==null){
newHead=tmp=list2;
}else{
tmp.next=list2;
tmp=tmp.next;
}
list2=list2.next;
}
}
//拼接剩余链表至新链表尾节点
if(list1==null){
tmp.next=list2;
}else{
tmp.next=list1;
}
return newHead;
} public static Node merge(Node list1,Node list2){
//空判断 如果有一个为空则 返回另一个链表
if(list1==null)
return list2;
else if(list2==null)
return list1;
Node newHead=null; //结果节点
Node tmp=null; //临时指针
//往新链表一个个添加节点 直至有一个链表为空
//tmp存放最后一个添加进新链表的节点 用于后续的拼接
while(list1!=null&&list2!=null){
if(list1.data<list2.data){
if(newHead==null){
newHead=tmp=list1;
}else{
tmp.next=list1;
tmp=tmp.next;
}
list1=list1.next;
}else{
if(newHead==null){
newHead=tmp=list2;
}else{
tmp.next=list2;
tmp=tmp.next;
}
list2=list2.next;
}
}
//拼接剩余链表至新链表尾节点
if(list1==null){
tmp.next=list2;
}else{
tmp.next=list1;
}
return newHead;
}
28案例分析与实现
两个多项式相加运算

图书管理
顺序表实现
TODO
链表实现
TODO
栈与队列
3.1栈和队列的定义和特点
- 栈和队列是两种常用的、重要的数据结构
- 栈和队列是限定插入和删除只能在表的“端点”进行的
线性表

栈——后进先出
- 类似手电筒的电池,弹匣。最后放进去的取出时会先取
- 由于栈的操作具有后进先出的固有特性,使得栈成为程序设计常用工具。另外,如果问题求解的过程具有"后进先出"的天然特性的话,则求解的算法中也必然需要利用"栈
- 数制转换
- 表达式求值
- 括号匹配的检验
- 八皇后问题
- 行编辑程序
- 函数调用
- 迷宫求解
- 递归调用的实现
队列——先进先出
- 类似排队
- 由于队列的操作具有先进先出的特性,使得队列成为程序设计中解决类似
排队问题的有用工具。- 脱机打印输出:按申请的先后顺序依次输出
- 多用户系统中,多个用户排成队,分时地循环使用CPU和内存
- 按用户的优先级排成多个队,每个优先级一个队列
- 实时控制系统中,信号按接收的先后顺序依次处理
- 网络电文传输,按到达的时间先后顺序依次进行
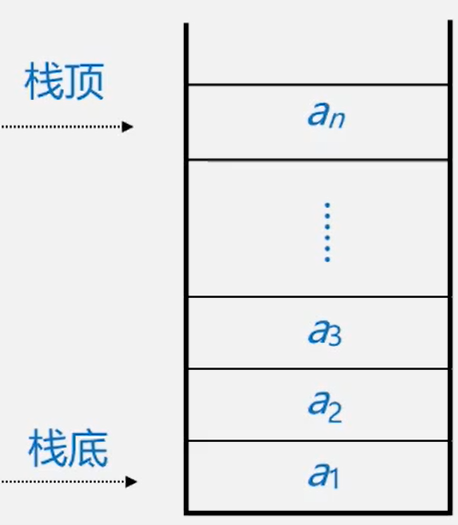
栈的定义和特点
- 栈( stack)是一个特殊的线性表,是限定仅在一端(通常是表尾进行插入和删除操作的线性表)
- 又称为后进先出( Last In First Out)的线性表,简称LFO结构。
相关概念
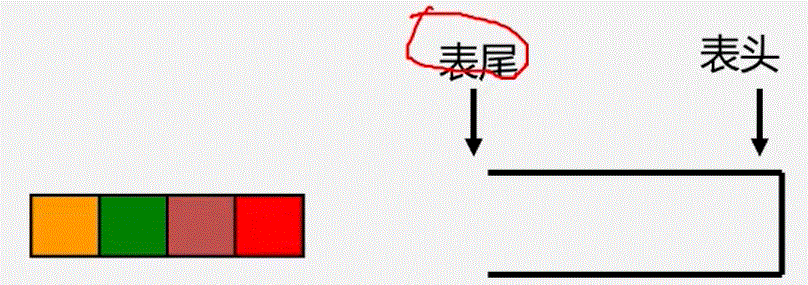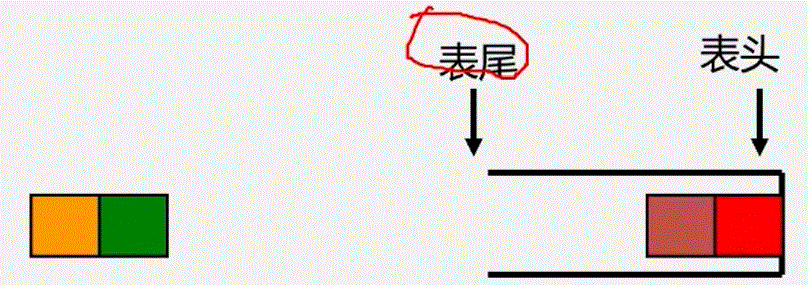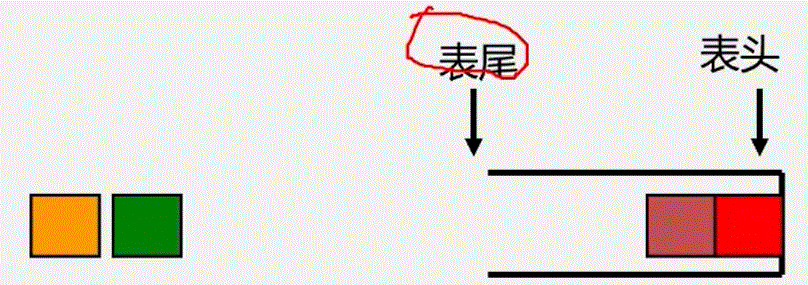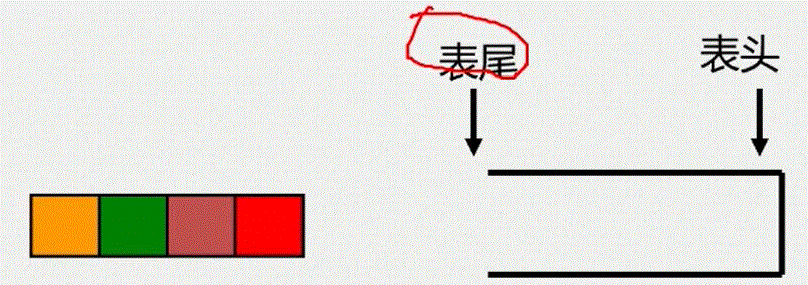
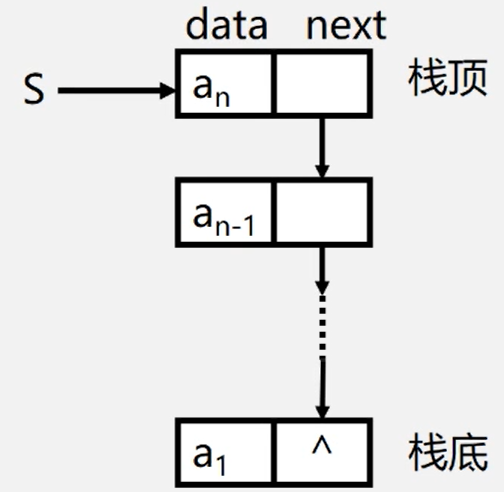
- 栈是仅在表尾进行插入、删除操作的线性表。
- 表尾即a端称为栈顶Top;表头即a1端)称为栈底Base
- 插入元素到
栈顶(即表尾)的操作,称为入栈 PUSH - 从
栈顶(即表尾)删除最后一个元素的操作,称为出栈 POP

栈的示意图
【思考】假设有3个元素a,b,c,入栈顺序是a,b,c则它们的出栈顺序有几种可能?(入栈出栈可以随时)
栈与一般线性表有什么不同?
| 一般线性表 | 栈 | |
|---|---|---|
| 逻辑结构 | 一对一 | 一对一 |
| 存储结构 | 顺序表、链表 | 顺序栈、链栈 |
| 运算规则 | 随机存取 | 先进后出(LIFO) |
队列的定义和特点
队列( queue)是一种先进先出( Frist in frist out-HFO的线性表。在表一端插入(表尾),在另一端(表头)删除
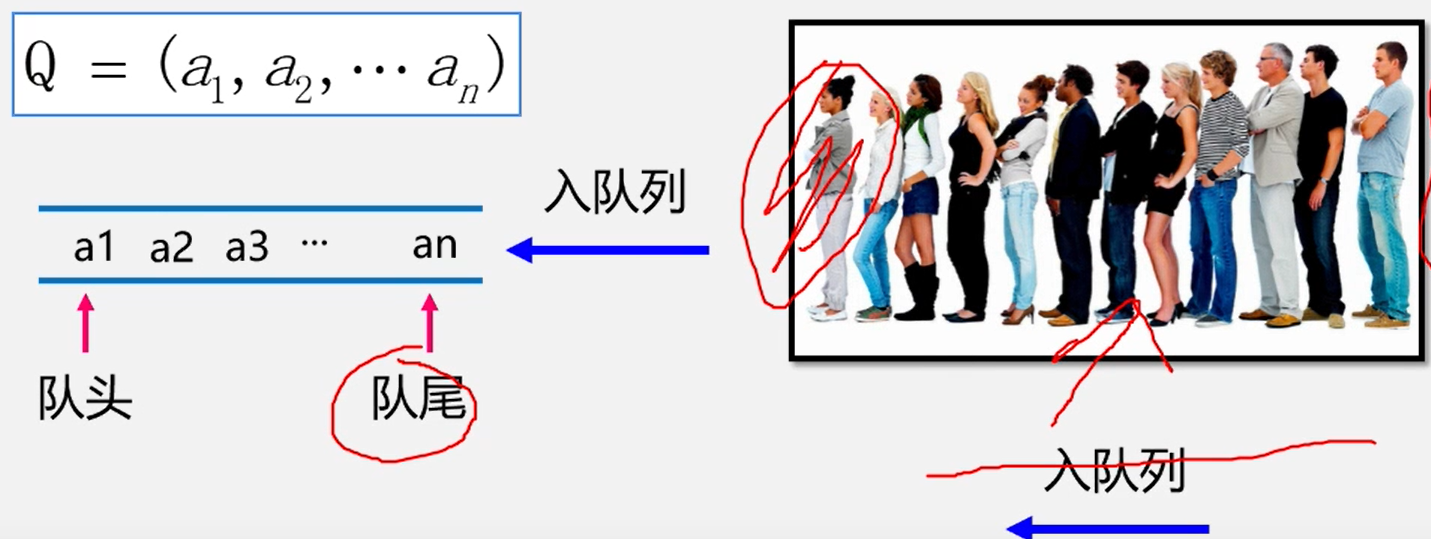
定义
只能在表的一端进行插入运算,在表的另一端进行删除运算的线性表
(头删尾插)
逻辑结构
与同线性表相同,仍为一对一关系。
存储结构
顺序队或链队,以循环顺序队列更常见。
运算规则
只能在队首和队尾运算,且访问结点时依照先进先出(FIFO)的原则。
实现方式
关键是掌握入队种出队操作,具体实现顺序队或链队的不同而不同
3.2案例引入
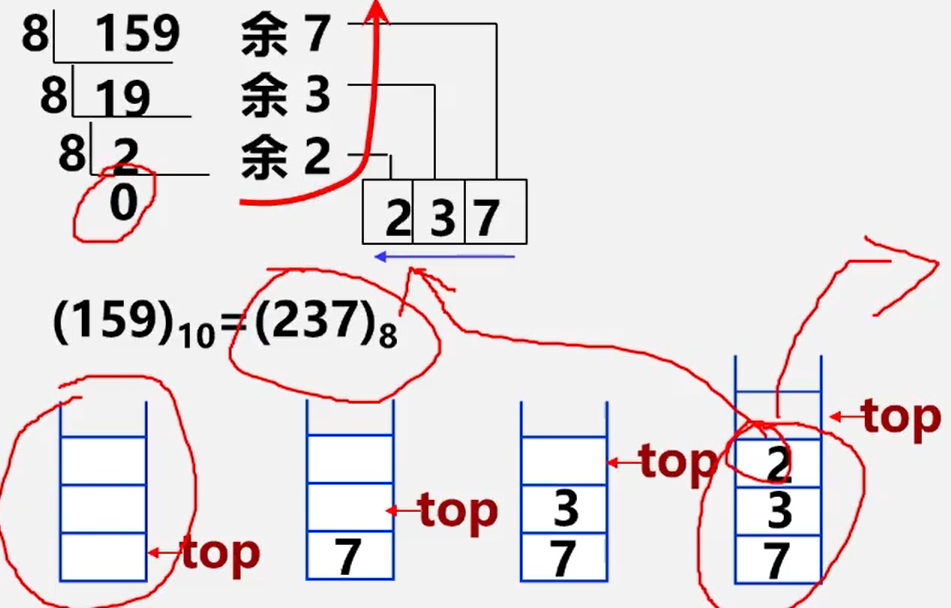
案例1、进制转换
例: 把十进制数159转换成八进制数。
案例2、括号匹配的检验
假设表达式中允许包含两种括号:圆括号和方括号
其嵌套的顺序随意,即
([]())或[([][])]为正确格式[(])为错误格式;([())为错误格式
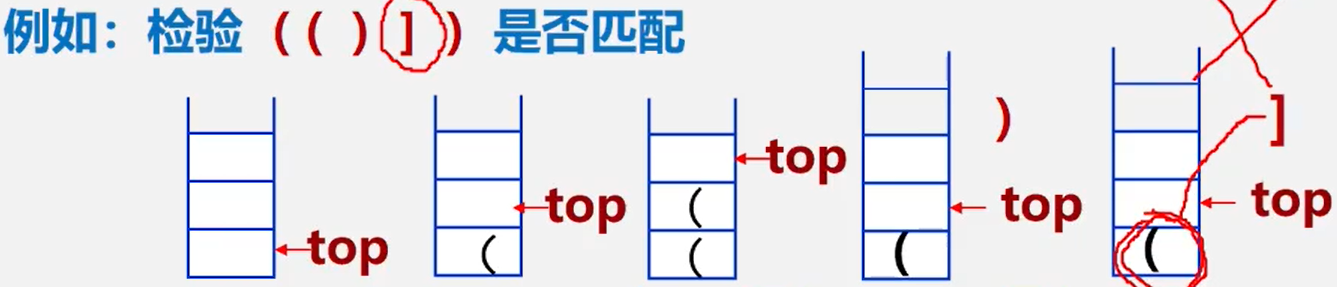
算法步骤:
符号顺序进栈,每次入栈时判断入栈元素与栈顶元素,如果相同将元素压入栈中,如果是同类型的另一半则元素不压栈并弹出栈顶元素,如果是不同类型的元素则返回匹配失败
案例3、表达式求值
表达式求值是程序设计语言编译中一个最基本的问题,它的实现也需要运用栈。
这里介绍的算法是由运算符优先级确定运算顺序的对表达式求值算法算——算符优先算法。
- 表达式的组成
- 操作数( operand):常数、变量。
- 运算符 (operator)):算术运算符、关系运算符和逻辑运算符。
- c界限符( delimiter):左右括弧和表达式结束符。
- 任何一个算术表达式都由
操作数(常数、变量)、算术运算符(+、-、*、/)和界限符(括号、表达式结束符"#、虚设的表达式起始符“#′组成。后两者统称为算符。
例如:#3 * ( 7 - 2)# 其中3、7、2是操作数,*、-是运算符,# () 是运算符
算法步骤:
为了实现表达式求值。需要设置两个栈
一个是算符栈OPTR,用于寄存运算符。
另一个称为操作数栈OPND,用于寄存运算数和运算结果。
求值的处理过程是自左至右扫描表达式的每一个字符
- 当扫描到的是运算数,则将其压入栈OPND,
- 当扫描到的是运算符时
- 若这个运算符比OPTR栈顶运算符的优先级高,则入栈OPTR,继续向后处理
- 若这个运算符比OPTR栈顶运算符优先级低,则从OPND栈中弹出两个运算数,从栈OPND中弹出栈顶运算符进行运算,并将运算结果压入栈OPND
- 继续处理当前字符,直到遇到结束符为止。
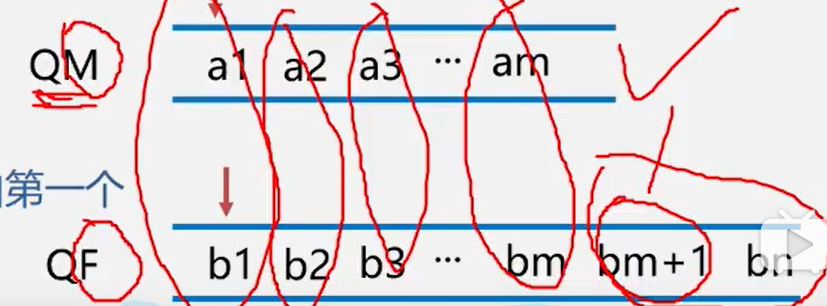
案例4、舞伴问题
- 假设在舞会上,男士和女士各自排成一队。舞会开始时依次从男队和女队的队头各出一人配成舞伴。如果两队初始人数不相同,则较长的那一队中未配对者等待下轮舞曲。现要求写一算法模拟上述舞伴配对问题。
- 显然,先入队的男士或女士先出队配成舞伴。因此该问题具有典型的先进先出特性,可以用队列作为算法的数据结构。
- 首先构造两个队列
- 依次将队头元素出队配成舞伴
- 某队为空,则另外一队等待者则是下一舞曲第一个可获得舞伴的人。
3.3栈的表示和操作的实现
栈的抽象数据类型定义
ADT Stack{
数据对象:
D={ ai | ai ∈ ElemSet, i=1,2...n , n ≥ 0}
数据关系:
R1={ < ai-1 , ai >| ai-1,ai ∈ D , i=2,...n}
约定an端为栈顶,a1端为栈底。
基本操作:
初始化、进栈、出栈、取顶栈元素等
}ADT Stack
initStack(&S)初始化操作
操作结果:构造一个空栈S。
Destroy Stack(&S)销毁栈操作
初始条件:栈S已存在。
操作结果:栈S被销毁。
StackEmpty(S)判定S是否为空栈
初始条件:栈S已存在。
操作结果:若栈S为空栈,则返回RUE否则 FALSE。
StackLength(S)求栈的长度
初始条件:栈S已存在。
操作结果:返回S的元素个数,即栈的长度
GetTop(S,&e)取栈页元素
初始条件:栈S已存在且非空。
操作结果:用e返回S的栈顶元素。
Clearstack(&S)栈置空操作
初始条件:栈S已存在。
操作结果:将S清为空栈。
Push(&s,e)入栈操作
初始条件:栈S已存在。
操作结果:插入元素e为新的栈顶元素。
Pop(&S、&e)出栈操作
初始条件:栈S已存在且非空。
操作结果:删除S的栈顶元素an,并用e返回其值。
顺序栈的表示和实现
存储方式:同一般线性表的顺序存储结构完全相同,利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素。栈底一般在低地址端。
- 附设
top指针,指示栈顶元素在顺序栈中的位置。 - 另设
base指针,指示栈底元素在顺序栈中的位置。
但是,为了方便操作,通常top指示真正的栈顶元素之上的下标地址
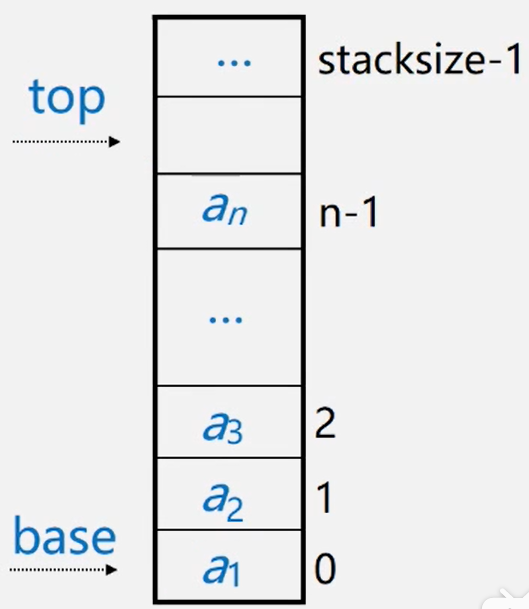
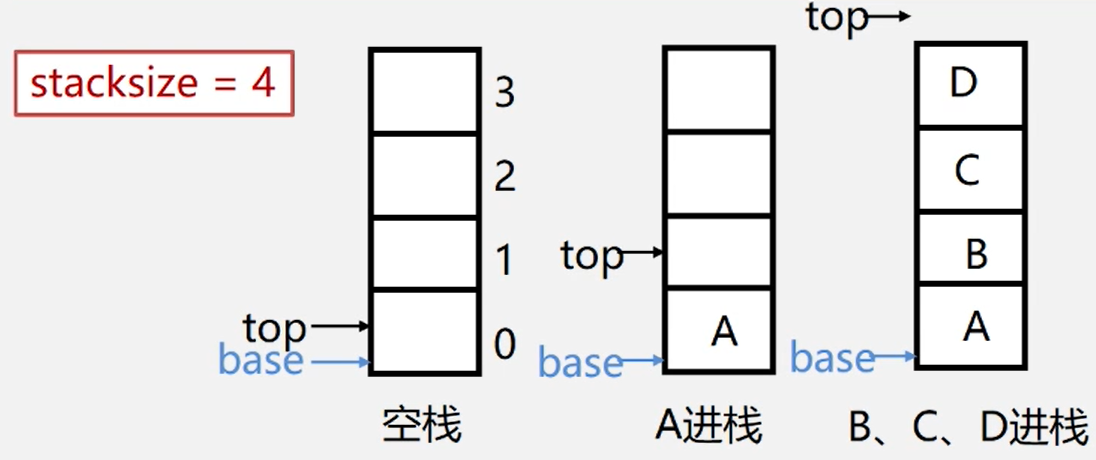
空栈:base==top是栈空标志
栈满:top-base== stacksize
栈满时处理方法
1、报错
2、分配更大空间,作为栈的存储空间,原栈的内容移入新栈
特点
作为顺序栈存储方式的特点简单方使、但易产生溢出(数组大小固定)
上溢( overflow):栈已经满,又要压入
元素下溢 (underflow)栈已经空,还要弹详出元
注:上溢是一种错误,使问题的处理无法进行;而下溢一般认为是种结束条件,即问题处理结束。
顺序栈的表示


顺序栈的初始化

public class StackList {
final int defaultSize = 20;
int data[];
int top;
int base;
int stackSize; //容量
StackList(int size){
data = new int[size];
stackSize = size;
top = 0;
base = 0;
}
StackList(){
data = new int[defaultSize];
stackSize = defaultSize;
top = 0;
base = 0;
}
}
顶序栈判断栈是否为空

boolean empty(){return base==top;}
求顺序栈长度

int size(){return top-base;}
清空顺序栈
将top指针指向base指针

//清空栈
void clear(){top = base;}
销毁顺序栈

顺序栈的入栈
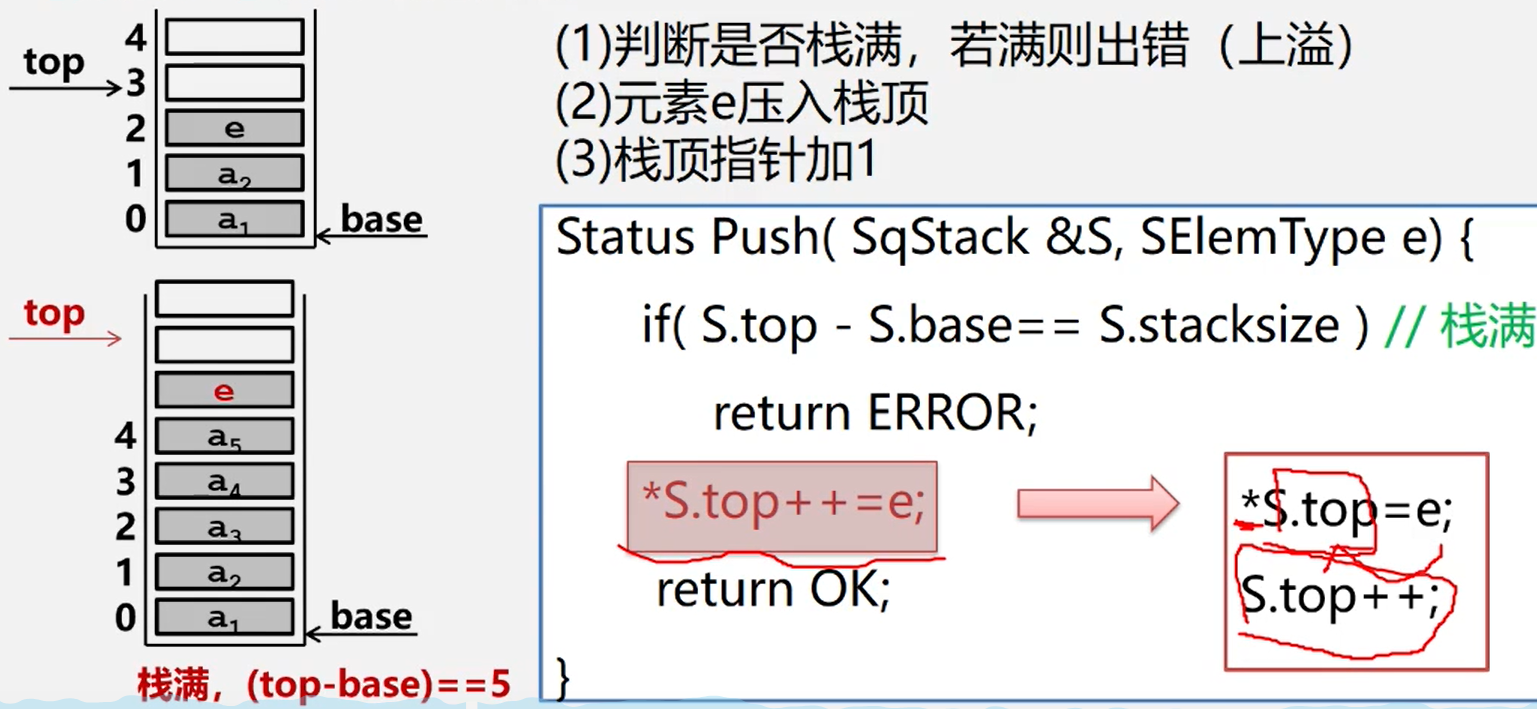
int push(int item){
if (top == 0 && base == 0){base = item;}
if(top-base == stackSize){throw new StackOverflowError();}
data[top] = item;
top++;
return item;
}
顺序栈的出栈
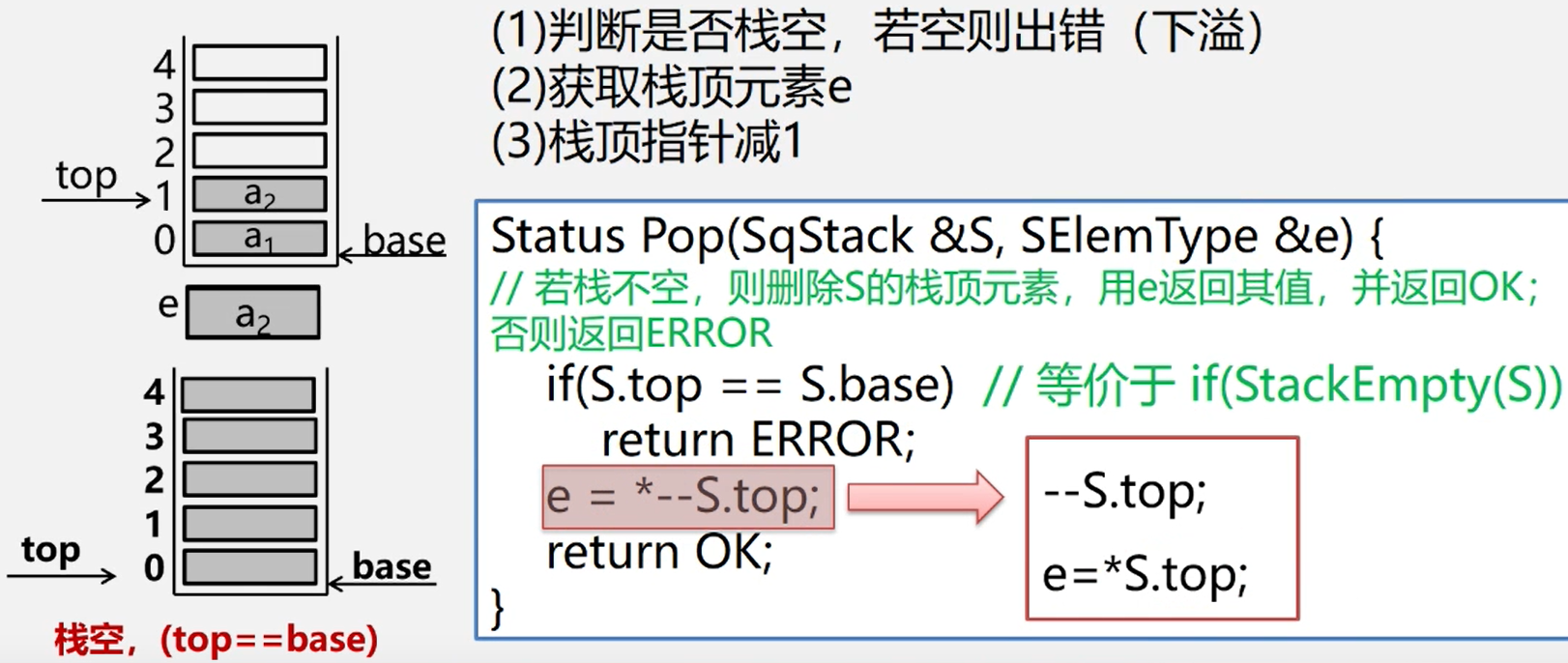
int pop(){
if (empty()){
throw new EmptyStackException();
}else {
int item = data[top-1];
top--;
return item;
}
}
完整代码
import java.util.EmptyStackException;
/**
* @program: javaBaseLearn
* @description: 线性表实现的栈
* @author: Jishun Zhao
* @create: 2020-07-05 12:45
*/
public class StackList {
final int defaultSize = 20;
int data[];
int top;
int base;
int stackSize; //容量
StackList(int size){
data = new int[size];
stackSize = size;
top = 0; //存储顶元素+1的下标
base = 0; //存储底元素的下标
}
StackList(){
data = new int[defaultSize];
stackSize = defaultSize;
top = 0;
base = 0;
}
int push(int item){
if (top == 0 && base == 0){base = item;}
if(top-base == stackSize){throw new StackOverflowError();}
data[top] = item;
top++;
return item;
}
int pop(){
if (empty()){
throw new EmptyStackException();
}else {
int item = data[top-1];
top--;
return item;
}
}
//清空栈
void clear(){top = base;}
int size(){return top-base;}
boolean empty(){return base==top;}
int getTop(){return data[top-1];}
@Override
public String toString() {
return super.toString();
}
public static void main(String[] args) {
StackList stackList = new StackList();
for (int i = 0; i < 19; i++) {
stackList.push(i);
}
while (!stackList.empty()){
System.out.println(stackList.pop());
}
}
}
链栈的表示和实现
链栈的表示
链栈是运算受限的单链表,只能在链表头部进行操作
typedef struct StackNode{
SElemType data;
struct StackNode *next;
}StackNode , *LinkStack;
LinkStack S;
注意指针的方向:指针方向从栈顶指向栈底
- 链表的头指针就是栈顶
- 不需要头节点
- 基本不存在栈满的情况
- 空栈相当于头指针指向空
- 插入和删除仅在栈顶处执行
链栈的初始化

public class LinkedStack {
class Node{
int data;
Node next;
}
Node data;
LinkedStack(){
data = null;
}
}
判断链栈是否为空

//判断是否为空
boolean empty(){return data == null;}
链栈的入栈
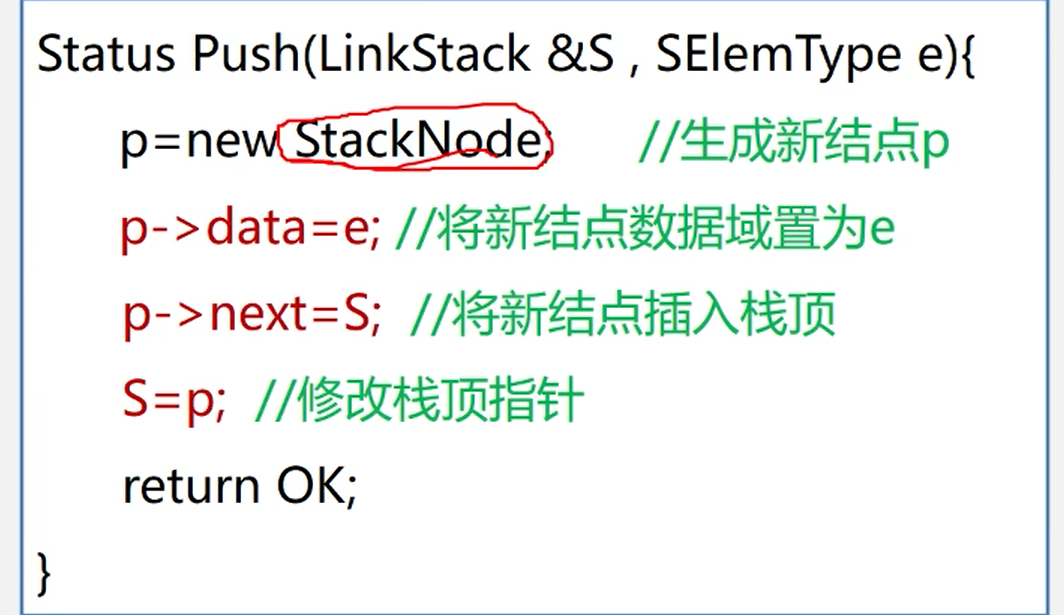
//入栈
int push(int emel){
Node node = new Node(); //创建新节点p
node.data = emel; //设置新节点数据
node.next = data; //节点next域指向栈顶指针
data = node; //将栈顶指针指向新节点
return emel;
}
链栈的出栈
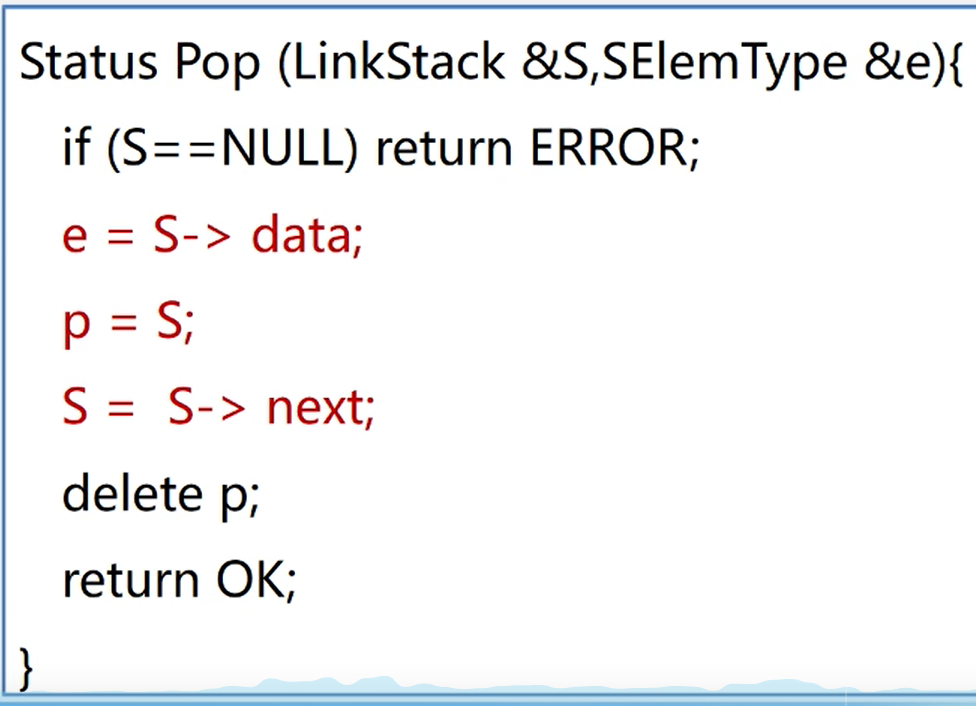
//出栈
int pop(){
if (empty()){ //判断是否还有元素
throw new StackOverflowError(); //没有元素抛出错误
}else {
int emel = data.data; //保存栈顶数据方便返回
data = data.next; //将栈顶指针指向 栈顶的下一个元素
return emel;
}
}
获得栈顶元素

//获得栈顶元素
int topEmel(){
if (empty()){
throw new StackOverflowError();
}else {
return data.data;
}
}
完整代码
public class LinkedStack {
class Node{
int data;
Node next;
}
Node data;
//初始化
LinkedStack(){
data = null;
}
//判断是否为空
boolean empty(){return data == null;}
//入栈
int push(int emel){
Node node = new Node(); //创建新节点p
node.data = emel; //设置新节点数据
node.next = data; //节点next域指向栈顶指针
data = node; //将栈顶指针指向新节点
return emel;
}
//出栈
int pop(){
if (empty()){ //判断是否还有元素
throw new StackOverflowError(); //没有元素抛出错误
}else {
int emel = data.data; //保存栈顶数据方便返回
data = data.next; //将栈顶指针指向 栈顶的下一个元素
return emel;
}
}
//获得栈顶元素
int topEmel(){
if (empty()){
throw new StackOverflowError();
}else {
return data.data;
}
}
public static void main(String[] args) {
LinkedStack linkedStack = new LinkedStack();
for (int i = 0; i < 10; i++) {
linkedStack.push(i);
}
while (!linkedStack.empty()){
System.out.println(linkedStack.pop());
}
}
}
3.4栈与递归
递归的定义
- 若一个对象部分地包含它自己,或用它自己给自己定义,则称这个对象是递归的;
- 若一个过程直接地或间接地调用自己,则称这个过程是递归的过程。
例如:递归求n的阶乘

以下三种情况常常用到递归方法
- 递归定义的数学函数
- 具有递归特性的数据结构
- 可递归求解的问题
具有递归特性的数据结构
- 二叉树
- 广义表

递归问题——分治法求解
分治法:对于一个较为复杂的问题,能够分解成几个相对简单的且解法相同或类似的子问题来求解
必备的三个条件:
1、能将一个问题转变成一个新问题,而新问题与原问题的解法相同或类同,不同的仅是处理的对象,且这些处理对象是变化有规律的
2、可以通过上述转化而使问题简化
3、必须有一个明确的递归出口,或称递归的边界
分治法求解递归问题算法的一般形式

例如:

函数调用过程
调用前,系统完成:
1、将实参,返回地址等传递给被调用函数
2、为被调用函数的局部变量分配存储区
3、将控制转移到被调用函数的入口
调用后,系统完成:
1、保存被调用函数的计算结果
2、释放被调用函数的数据区
3、依照被调用函数保存的返回地址将控制转移到调用函数
当多个函数嵌套调用时
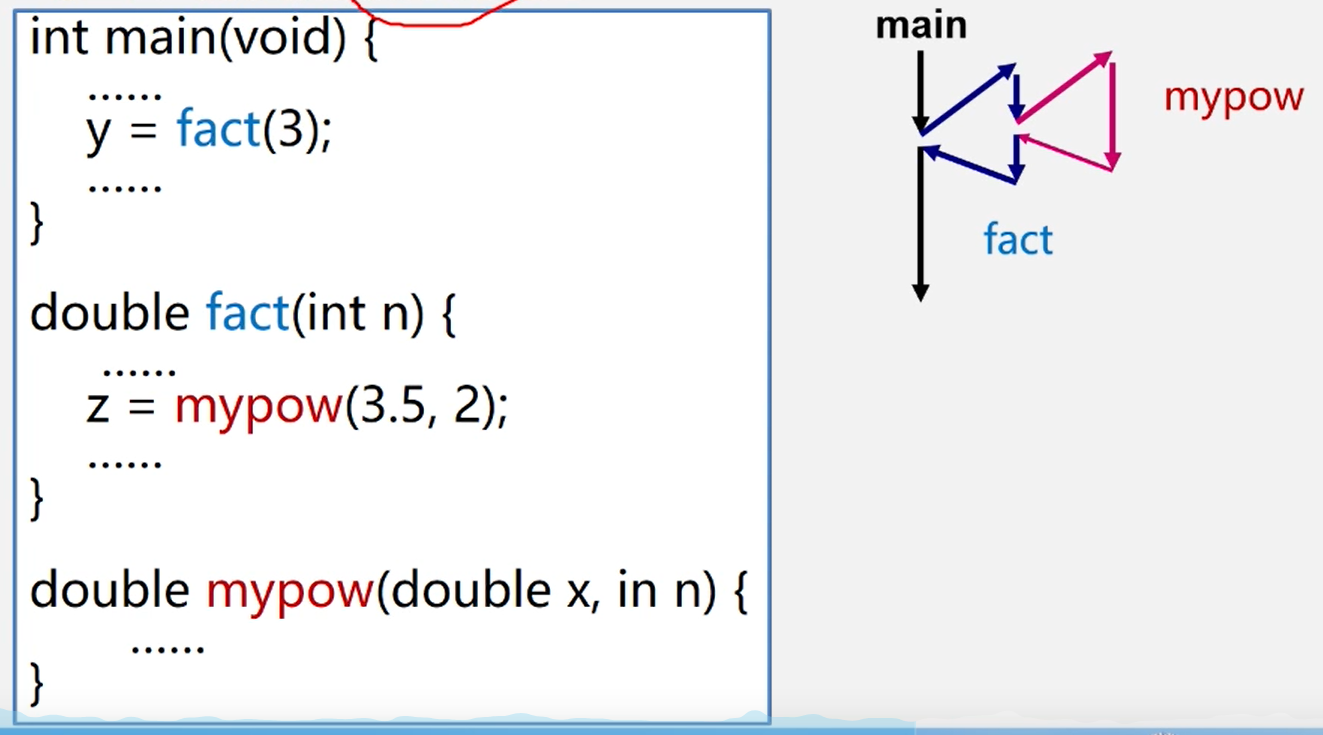
遵循后调用的先返回,和栈非常像
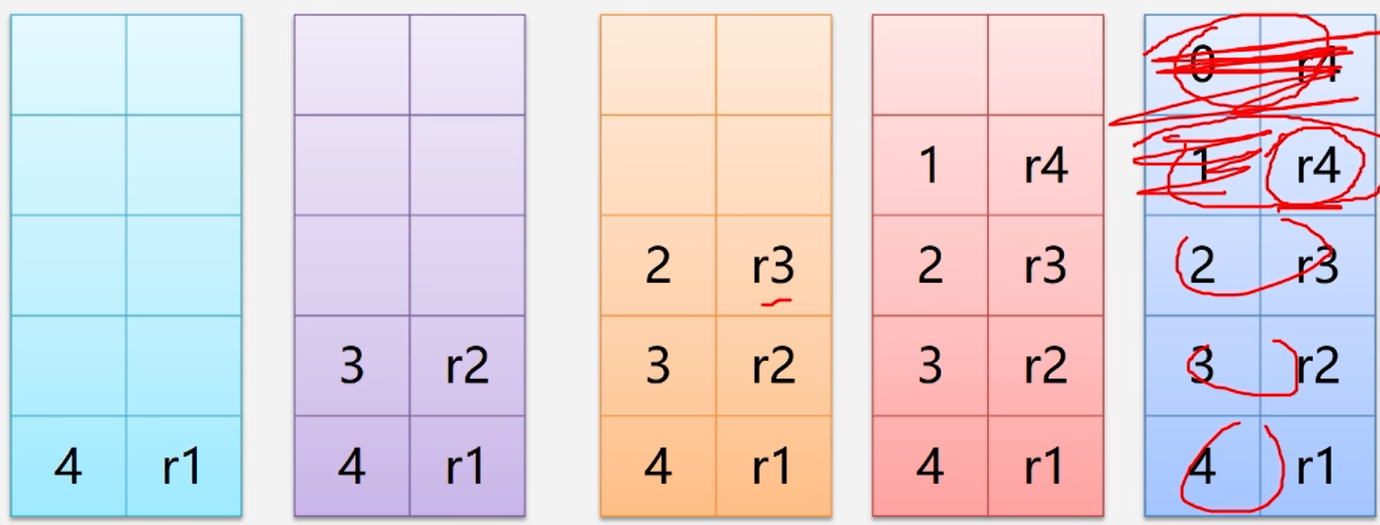
例子:求解阶乖n!的过程


递归函数的调用实现


归工作栈——》递归程序运行期间使用的数据存储区
在作记录——》实在参数,局部变量,返回地址
进行fact(4)调用的系统栈的变化状态
递归的优缺点
优点:结构清晰,程序易读
缺点:每次调用要生成工作记录,保存状态信息,入栈;返回时要出栈,恢复状态信息。时间开销大。
当时间开销较大时可以使用非递归方式代替递归方式
方法1:尾递归、单向递归——》循环结构
方法2:自用栈模拟系统的运行时栈
尾递归——》循环结构

单项递归——》循环结构
虽然有一处以上的递归调用语句,但各次递归调用语句的数只和主调函数有关,相互之间参数无关,并且这些递归调用语句处于算法的最后。
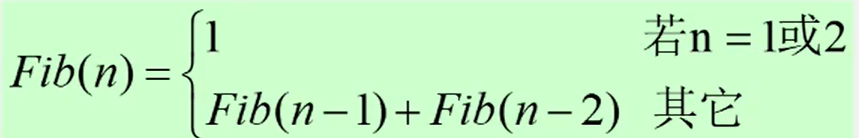

借助栈改写递归的方法(了解)
递归程序在执行时需要系统提供栈来实现,仿照递归算法执行过程中递归工作栈的状态变化可写出相应的非递归程
序,改写后的非递归算法与原来的递归算法相比,结构不够清晰,可读性较差,有的还需要经过一系列优化
(1)设置一个工作栈存放递归工作记录(包括实参、返回地址及局部变量等)
(2)进入非递归调用入口(即被调用程序开始处)将调用程序传来的实在参数和返回地址入栈(递归程序不可以作为主程序,因而可认为初始是被某个调用程序调用)。
(3)进入递归调用入口:当不满足递归结束条件时,逐层递归,将实参、返回地址及局部变量入栈,这一过程可用循环语句来实现_模拟递归分解的过程。
(4)递归结束条件满足,将到达递归出口的给定常数作为当前的函数值。
(5)返回处理:在栈不空的情况下,反复退岀栈顶记录,根据记录中的返回地址进行题意规定的操作,即逐层计算当前函数值,直至栈空为止—模拟递归求值过程。
3.5队列的的表示和操作的实现
队列的物理存储可以用顺序存储结构,也可用链式存储结构。相应地,队列的存储方式也分为两种,即顺序队列和链式队列。
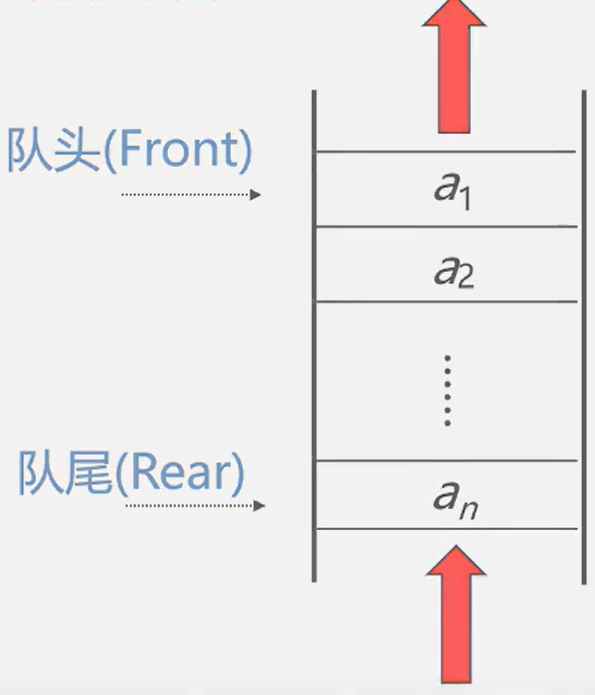
队列示意图
相关术语
队列( Queue)是仅在表尾进行插入操作,在表头进行删除操作的线性表- 表尾即an端,称为
队尾;表头即a端,称为队头。 - 它是一种先进先出(FFO)的线性表
插入元素称为入队;删除元素称为出队。
队列的存储结构为链队或顺序队(常用循环顺序队)
相关概念
定义
只能在表的一端进行插入运算,在表的另一端进行删除运算的线性表(头删尾插)
逻辑结构
与同线性表相同,仍为一对一关系。
存储结构
顺序队或链队,以循环顺序队列更常见。
运算规则
只能在队首和队尾运算,且访问结点时依照先进先出(FIFO)的原则。
实现方式
关键是掌握入队种出队操作,具体实现顺序队或链队的不同而不同
队列的常见应用
- 脱机打印输岀:按申请的先后顺序依次输岀
- 多用户系统中,多个用户排成队,分时地循环使用CP∪和主存
- 按用户的优先级排成多个队,每个优先级一个队列
- 实时控制系统中,信号按接收的先后顺序依次处理
- 网络电文传输,按到达的时间先后顺序依次进行
队列的抽象数据类型定义

队列的顺序表示
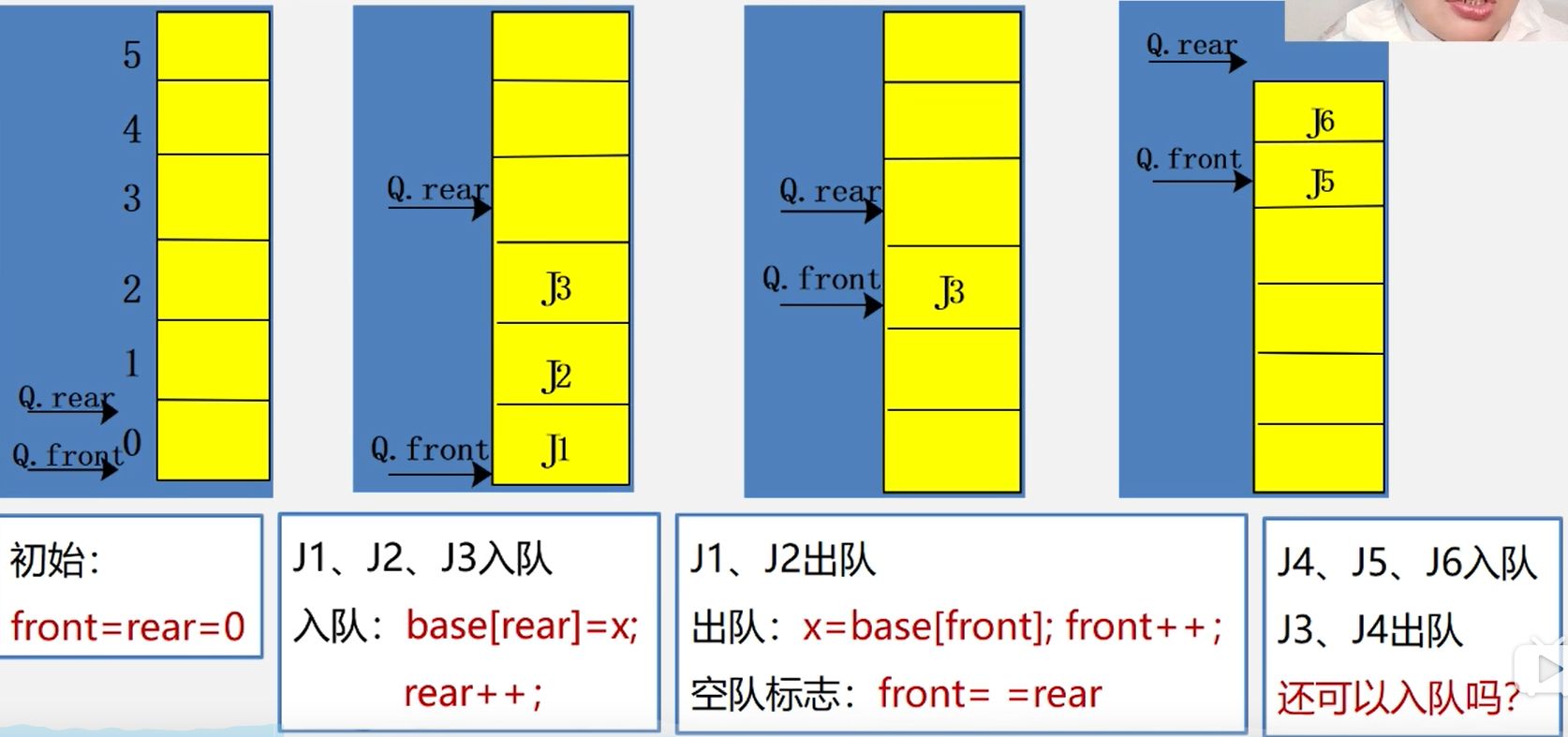
队列的顺序表示——用一维数组 base[MAXQsIze]
#define MAXQSIZE 100 //最大队列长度
Typedef struct{
QEmelType *base; //初始化动态分配内存空间
int front; //头指针
int rear; 尾指针
}SqQueue;

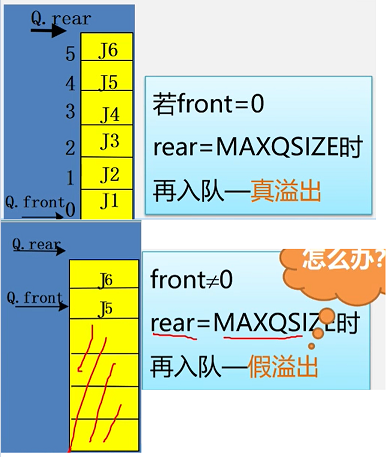
假溢出时怎么办?
◆解决假上溢的方法
1、将队中元素依次向队头方向移动。
缺点:浪费时间。每移动一次,队中元素都要移动。
2、将队空间设想成一个循环的表,即分配给队列的m个存储单元可以循环使用,当rear为mansize时,若向量的开始端空着,又可从头使用空着的空间。当 front为maxqsize时,也是一样。
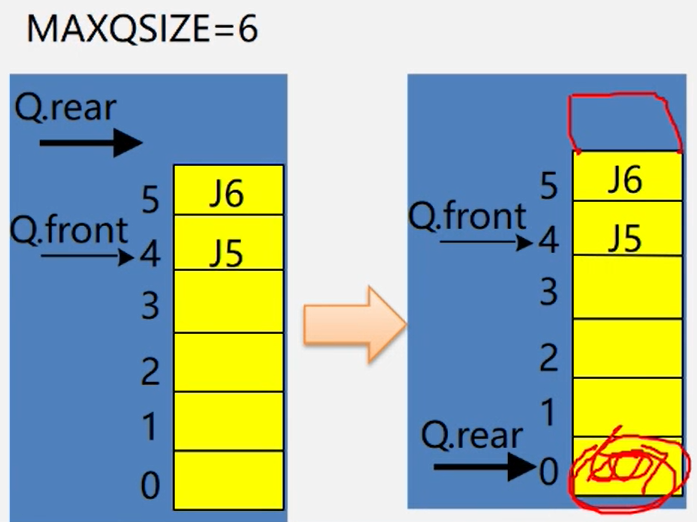
引入循环队列

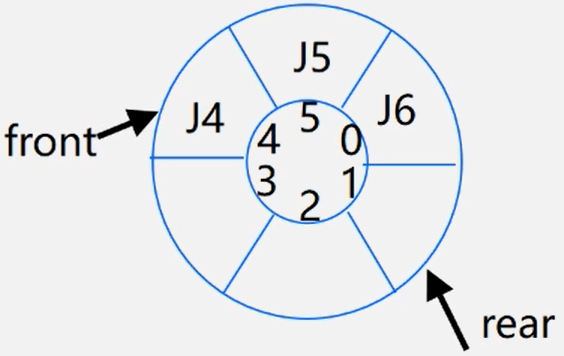
如何表示队空队满?

解决方式:
1、另外设一个标志以区别队空、队满
2、另设一个变量,记录元素个数
3、少用一个元素空间
本次使用方式3来表示表空
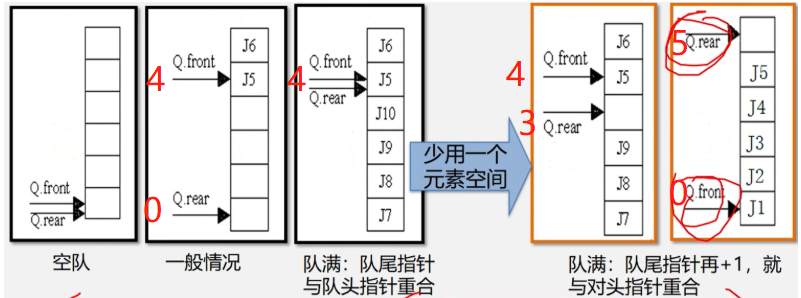
队满时的表示:(rear+1) % MAXQSIZE == front 这里的MAXSIZE = 5
( 3 + 1) % 5 == 4
顺序队列的操作
队列的初始化

public class SqQueue {
final int MAXSIZE = 20;
String[] data;
int front; //头指针
int rear; //尾指针
SqQueue(){
data = new String[MAXSIZE];
front = rear = 0;
}
// SqQueue(int size){
// data = new String[size];
// front = rear = 0;
// }
}
求队列的元素个数


//获得队列元素个数
int size(){return (rear - front + MAXSIZE) % MAXSIZE;}
循环队列入队

//元素入队
String enQueue(String elem){
if ((rear + 1) % MAXSIZE == front) //判断是否队满
throw new RuntimeException("队列已满");
data[rear] = elem; //新元素加入队尾
rear = (rear + 1) % MAXSIZE; //尾指针+1,求模可以在尾指针到最大下标时重新回到0位置
return elem;
}
循环队列出队
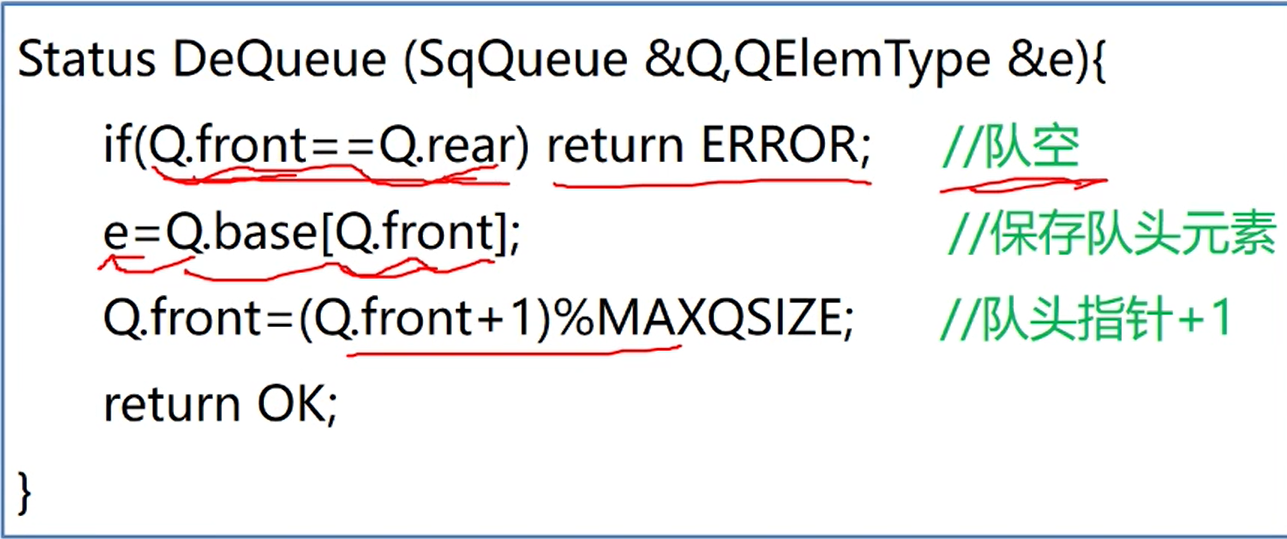
//元素出对
String deQueue(){
if (front == rear) throw new RuntimeException("队空"); //队空判断
String res = data[front]; //取出对头元素
front = (front + 1) % MAXSIZE; //头指针+1,求模可以在头指针到最大下标时重新回到0位置
return res;
}
取队头元素

//取队头元素
String getHead(){
if (front == rear) throw new RuntimeException("队空");
return data[front];
}
队列的链式表示
◆若用户无法估计所用队列的长度,则宜采用链队列

链队列的类型定义
#define MAXQUEUE 100 //最大队列长度
typedef struct Qnode{
QemelType data;
Stuct Qnode *next;
}Qnode, *QueuePtr;
typedef struct{
QueuePty front; //队头指针
QueuePty rear; //队尾指针
}LinkQueue;
public class LinkedQueue {
class Qnode{
String data;
Qnode next;
}
Qnode headNode; //头节点
Qnode front; //队头指针
Qnode rear; //队尾指针
}
链队列运算指针变化状况
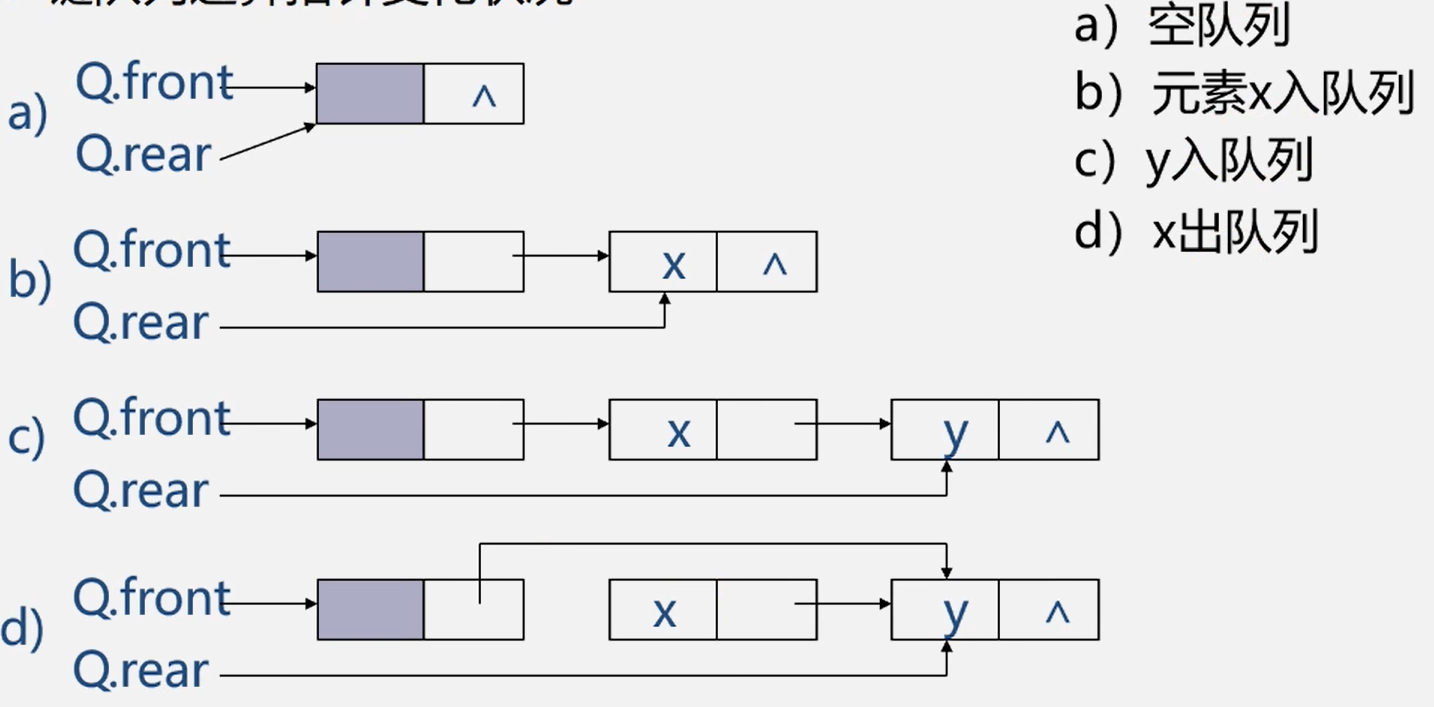
链队列的操作
链队列初始化
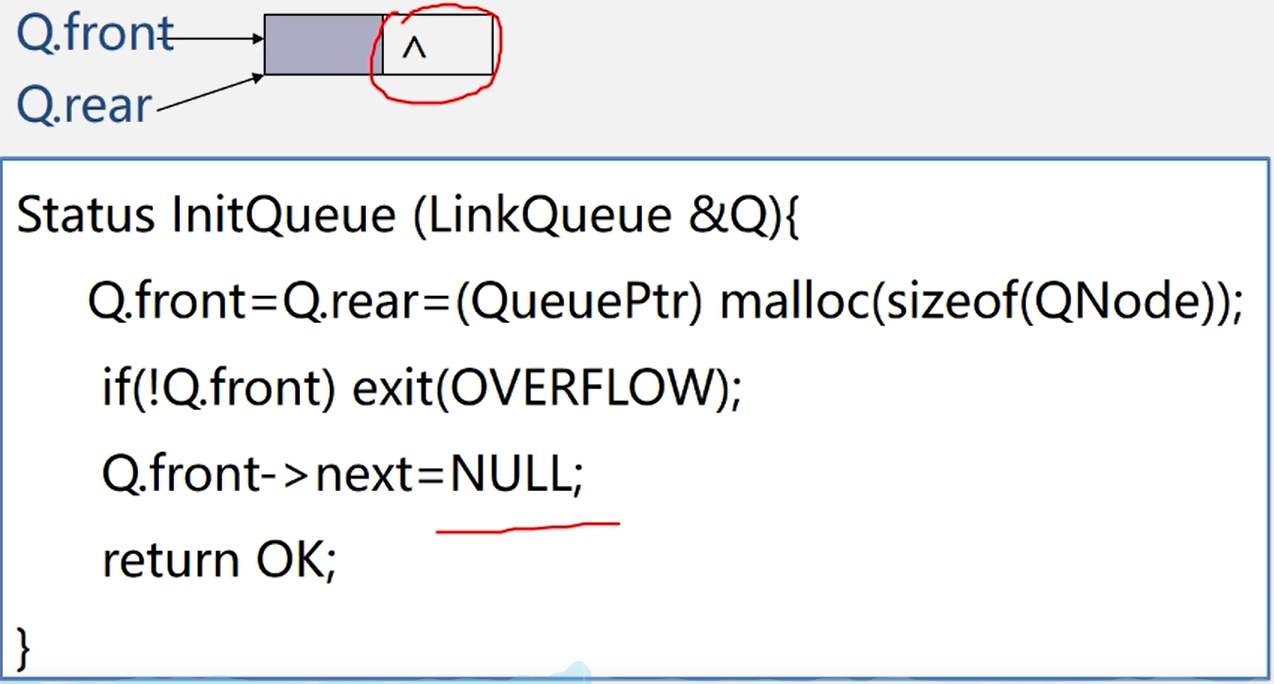
LinkedQueue(){
rear = front = headNode = new Qnode();
}
链队列销毁

java没有销毁操作
链队列入队
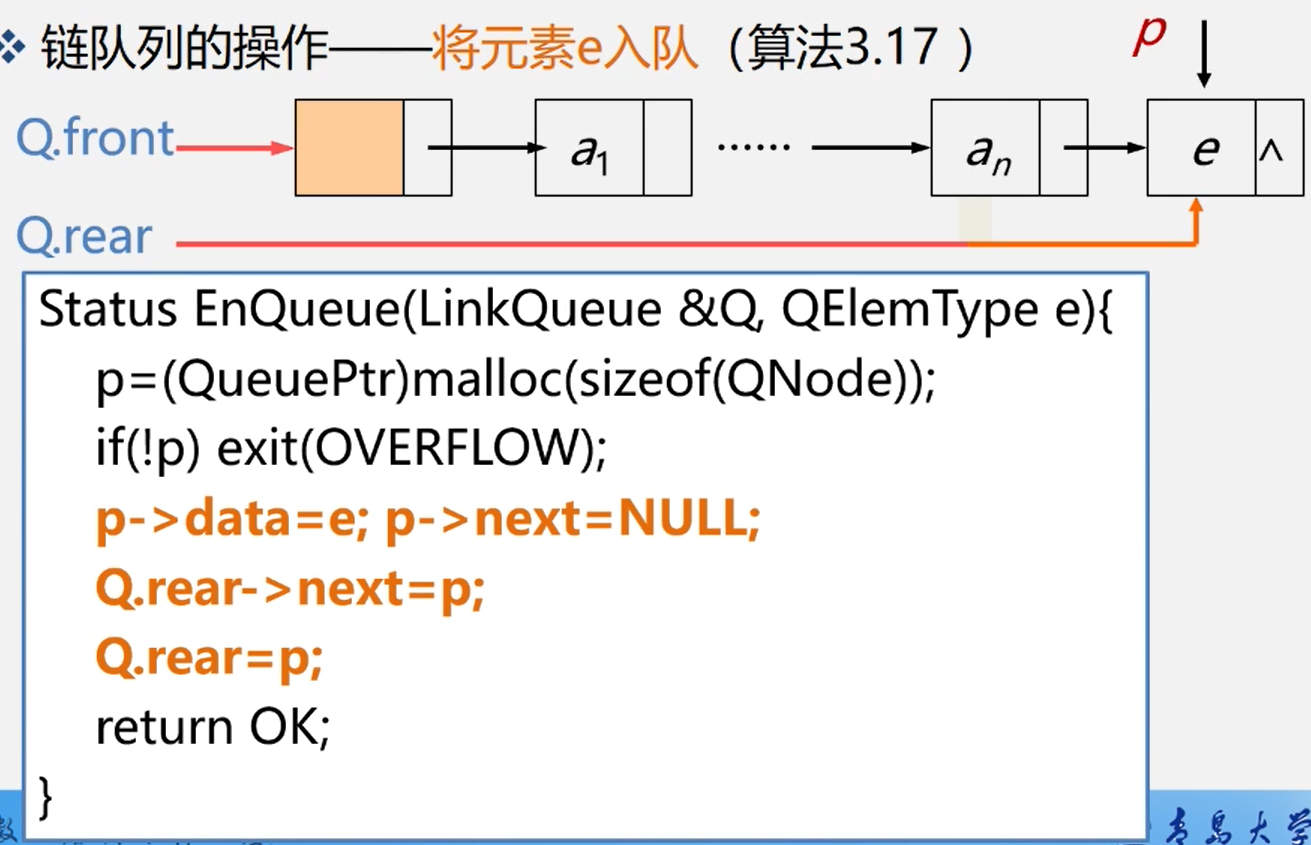
//入队
String enQueue(String emel){
Qnode qnode = new Qnode();
qnode.data = emel;
rear.next = qnode;
rear = qnode;
return emel;
}
链队列的出队


//出队
String deQueue(){
if (front == rear) throw new RuntimeException("队空");
Qnode temp = front.next; //要出队的元素
front.next = temp.next;
if (rear == temp) rear = front; //如果要出队的元素是尾节点,那么将尾节点指向头节点
return temp.data;
}
取队头元素

//取头节点
String getHead(){
return front.next.data;
}
3.6案例分析与实现
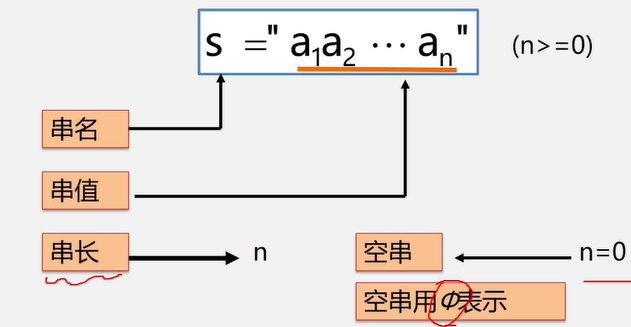
串String
串( String)——零个或多个任意字符组成的有限序列
串的相关术语
子串
子串:一个串中任意个连续字符组成的子序列(含空串)称为该串的子串。
例如,“ abcde"的子串有"","a" "ab" "abc"、“abcd和“ abcde"等
真子串是指不包含自身的所有子串。
主串
主串:包含子串的串相应地称为主串
字符位置
字符位置:字符在序列中的序号为该字符在串中的位置
子串位置
子串位置:子串第一个字符在主串中的位置
空格串
空格串:由一个或多个空格组成的串,与空串不同

串相等
串相等:当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才是相等的。
如:"abcd" ≠ “abc” "abcd" ≠ "abcde"
所有的空串是相等的。
案例引入
串的应用非常广泛,计算机上的非数值处理的对象大部分是字符串数据,例如:文字编辑、符号处理、各种信息处
理系统等等。
案例1、病毒感染检测
研究者将人的DNA和病毒DNA均表示成由一些字母组成的字符串序列。
然后检测某种病毒DNA序列是否在患者的DNA序列中出现过,如果出现过,则此人感染了该病毒,否则没有感染。
例如:假设病毒的DNA序列为ba,患者1的DNA序列为 aaabbba,则感染,患者2的DNA序列为 babbba,则未感染。
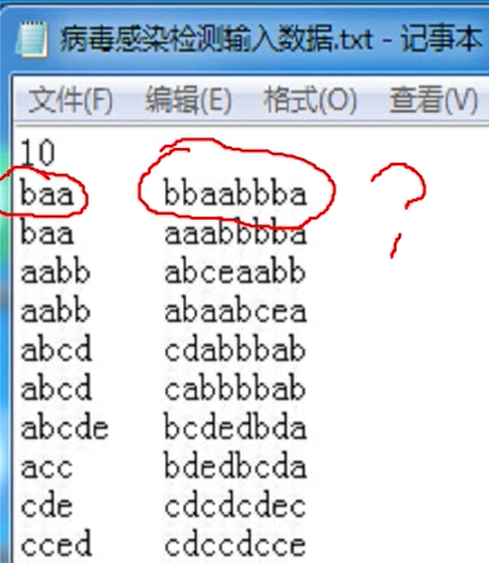
(注意,人的DNA序列是线性的,而病毒的DNA序列是环状的)所以认为aaabbba为感染
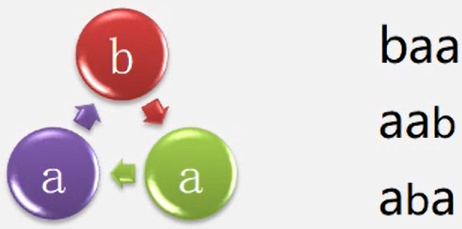
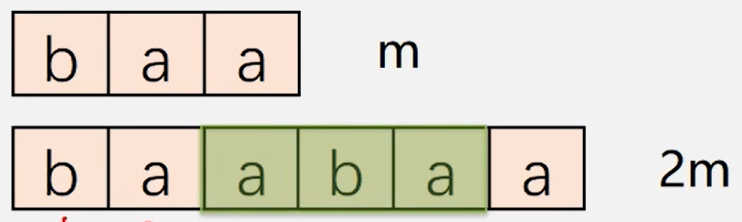
【案例实现】
●对于每一个待检测的任务,假设病毒DNA序列的长度是m因为病毒DNA序列是环状的,为了线性取到每个可行的长度为m的模式串可将存储病毒DNA序列的字符串长度扩大为2m,将病毒DNA序列连续存储两次。
●然后循环m次,依次取得每个长度为m的环状字符串,将此字符串作为模式串,将人的DNA序列作为主串调用B算法进行模式匹配
●只要匹配成功,即可中止循环,表明该人感染了对应的病毒;否则,循环次结束循环时,可通过BF算法的返回值判断该人是否感染了对应的病毒。
串的类型定义


串的存储结构
串中元素逻辑关系与线性表的相同,串可以采用与线性表相同的存储结构。
串的顺序存储结构
#define MAXLEN 255
typedef struct{
char ch[MAXLEN+1]; //存储串的一维数组,这里加一是为了让0号位置为空,方便实现其余算法
int length; //串的当前长度
}SString;
public class SString {
final int MAXSIZE = 255;
char[] data;
int lenth;
SString(){
data = new char[MAXSIZE];
lenth = 0;
}
}
串的链式存储结构
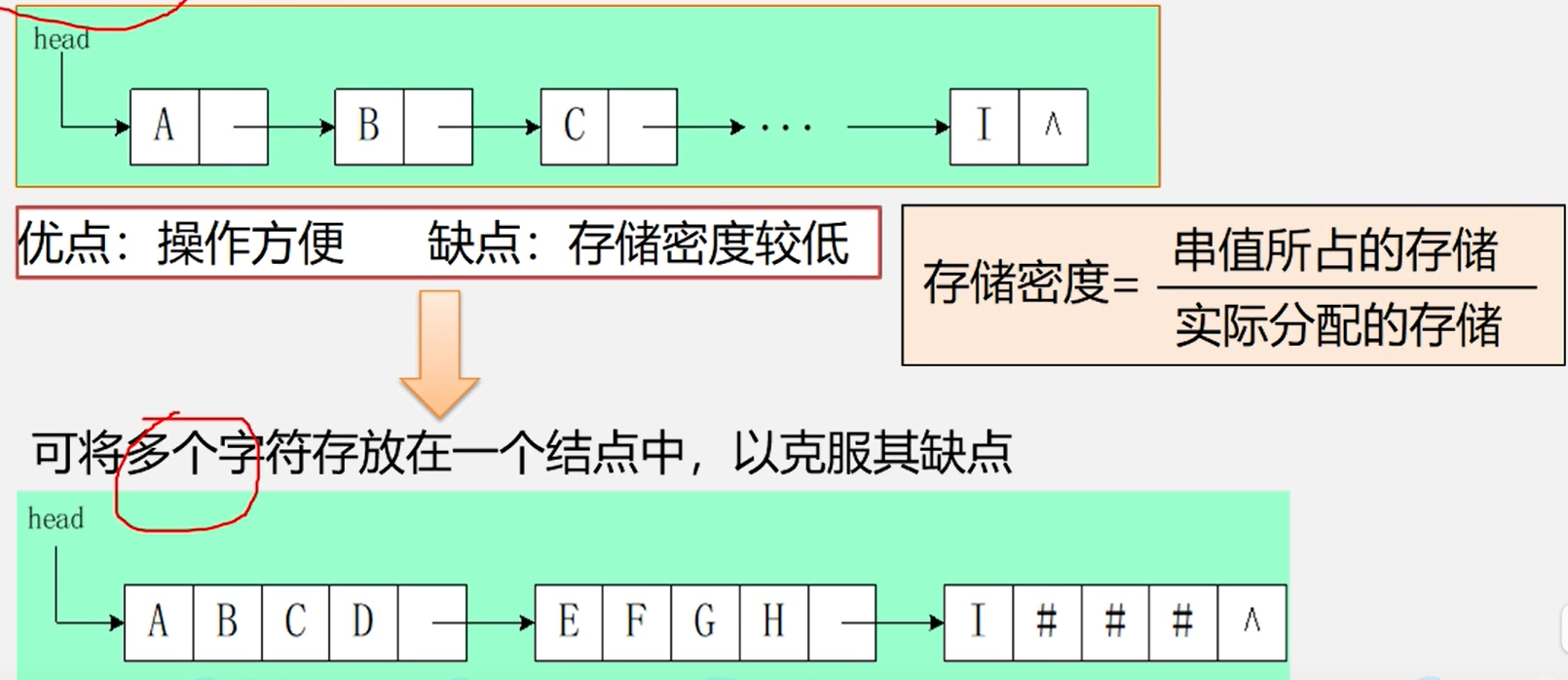
#define CHUNKSIZE 80 //块的大小可由用户定义
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct{
Chunk *head,*tail; //串的头指针和尾指针
int curlen; //串的当前长度
}LString; //字符串的块链结构
串的操作
串的模式匹配算法
算法目的:
确定主串中所含子串(模式串)第一次出现的位置(定位)
算法应用:
搜索引擎、拼写检査、语言翻译、数据压缩
算法种类:
- BF算法( Brute- Force,又称古典的、经典的、朴素的、穷举的)
- KMP算法(特点:速度快)
BF算法
Brute- Force简称为BF算法,亦称简单匹配算法。采用穷举法的思路。

算法的思路是从S的每一个字符开始依次与T的字符进行匹配。
例如,设目标串S="aaab”,模式串T=“aab′。
S的长度为n(n=6),T的长度为m(m=4)
BF算法的匹配过程如下:
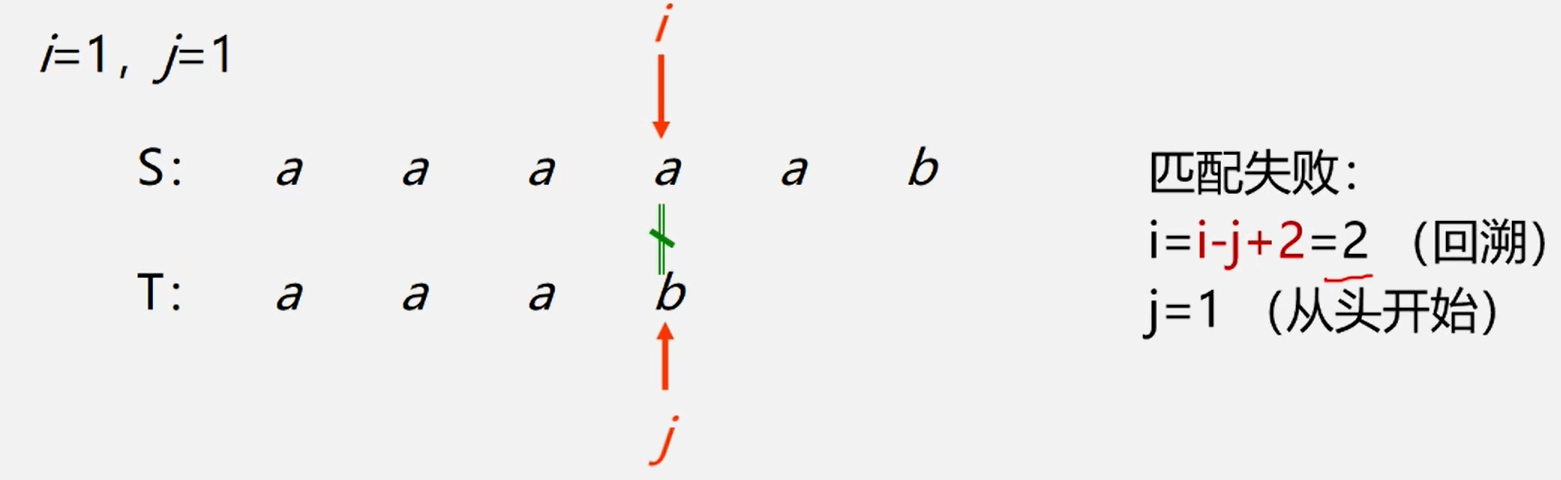
- 将主串的第pos个字符和模式串的第一个字符比较,
- 若相等,继续逐个比较后续字符;
- 若不等,从主串的下一字符起,重新与模式串的第一个字符比较。
- 直到主串的一个连续子串字符序列与模式串相等。返回值为S中与T匹配的子序列第一个字符的膀号即匹配成功
- 否则,匹配失败,返回值0
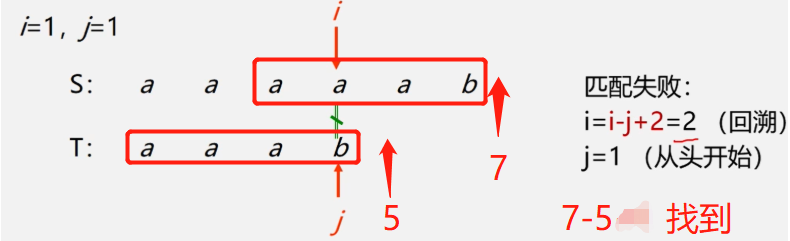

/**
* @Description: BF匹配算法
* @Param: 字串
* @return: 子串在正文串中的开始下标,没有返回-1
* @Author:
* @Date:
*/
int indexBF(SString t){
int i = 1; //主串的下标 S
int j = 1; //子串的下标 T
while (i <= lenth && j <= t.lenth){
if (data[i] == t.data[j]){ i++;j++; } //主串和子串一次匹配下一个字符
else {
i = i - j + 2; //主串子串回溯,重新开始下一次匹配
j = 1;
}
}
//判断是否找到 如果找到 子串的下标应该大于子串的长度 , 目标下标为 主串的下标减去子串的长度
System.out.println(i+"--"+j);
System.out.println(i);
if(j > t.lenth) {return i - t.lenth;}
else return -1;
}
时间复杂度
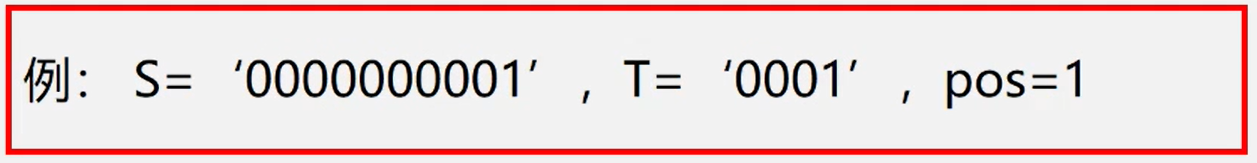
若n为主串长度,m为子串长度,最坏情况是
√主串前面n-m个位置都部分匹配到子串的最后一位,即这n-m位各比较了m次
√最后m位也各比较了1次总次数为:(n-m)*m+m=(n-m+1)m若m<<n,则算法复杂度o(nm)
总次数为:(n-m)*m+m=(n-m+1)*m若m<<n,则算法复杂度o(n7m
KMP( Knuth Morris pratt)算法
很好的文章:
如何更好地理解和掌握 KMP 算法? - 阮行止的回答 - 知乎 https://www.zhihu.com/question/21923021/answer/1032665486
如何更好地理解和掌握 KMP 算法? - 海纳的回答 - 知乎 https://www.zhihu.com/question/21923021/answer/281346746
KMP算法是 D.E. Knuth、J.H,Morris和V.R>Pratt共同提出的,简称KMP算法该算法较BF算法有较大改
进,其中的算法思想是跳过不可能成功的字符串比较。
利用已经部分匹配的结果而加快模式串的滑动速度
且主串S的指针i 不必回溯!可提速到O(n+m)!
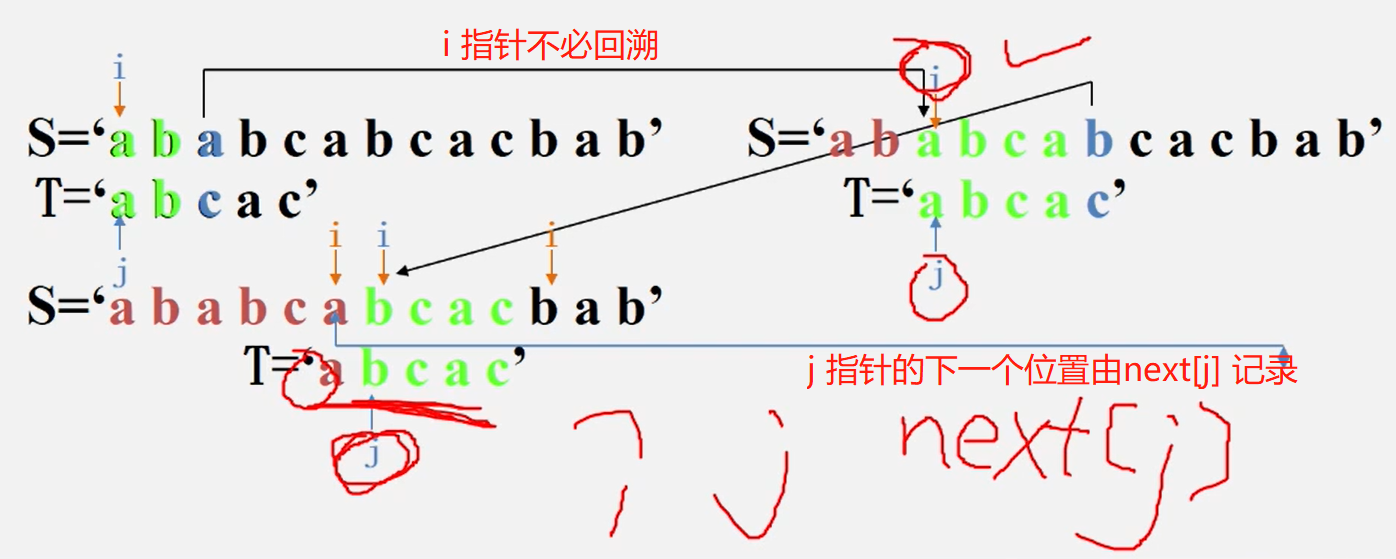
带着“跳过不可能成功的尝试”的思想,我们来看next数组。
在KMP算法中 ,j 指针的位置由 next[j] 记录表决定
next数组是对于模式串而言的。P 的 next 数组定义为:next[i] 表示 P[0] ~ P[i] 这一个子串,使得 前k个字符恰等于后k个字符 的最大的k. 特别地,k不能取i+1(因为这个子串一共才 i+1 个字符,自己肯定与自己相等,就没有意义了)。因此说,next数组为我们如何回溯提供了依据。也就是说对每个子字符串 [0...i],算出其「相匹配的真前缀与真后缀中,最长的字符串的长度」
为此,定义 next[j] 函数,表明当模式中第 j 个字符与主串中相应字 "失配″ 时,在模式中需重新和主串中该字符进行比较的字符的位置。

next[j] 的计算方式:
在从头开始 k - 1个子串 有几个等于 j前面的 k -1 个子串 ,如果没有得1 ,如果有得 最长相等子串的长度 + 1
例如:j = 7 时 ,从头开始的子串中只有 ab 等于j 前面的 k - 1 个子串 ,长度为2 ,得 2+1=3

元素相等时与BF算法相同,元素不等时,j 等于 next[j] ,就是上面我们算出来得数值

/**
* @Description: KPM 算法
* @Param:
* @return:
* @Author:
* @Date:
*/
int indexKMP(SString t){
int i = 1;
int j = 1;
int[] next = SString.getKMPNext(t);
while (i < lenth+1 && j < t.lenth+1){
if (j == 0 || data[i] == t.data[j]){//j == 0 也就是j回到了0位置
i++;
j++;
}else {
j = next[j];
}
}
if(j > t.lenth) {return i - t.lenth;}
else return -1;
}
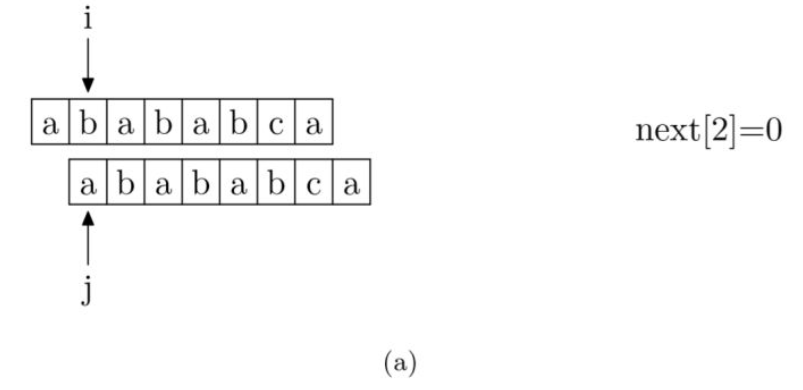
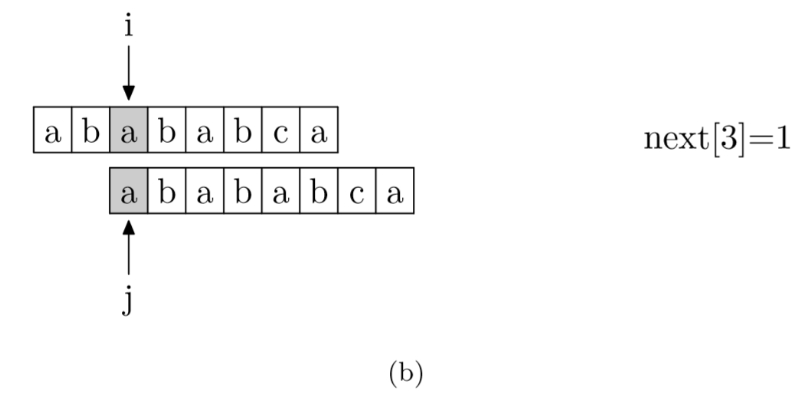
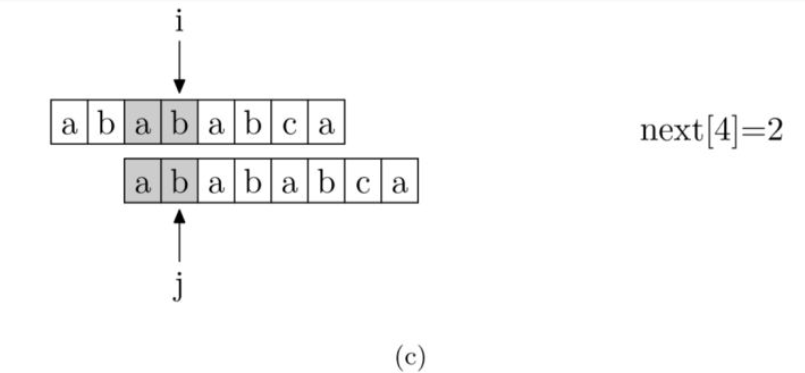
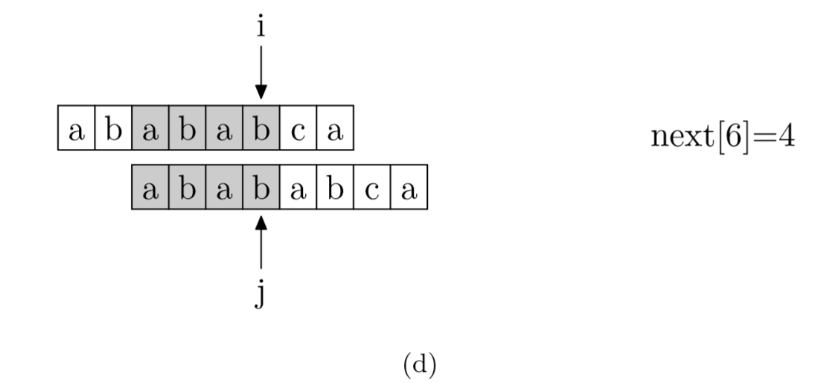
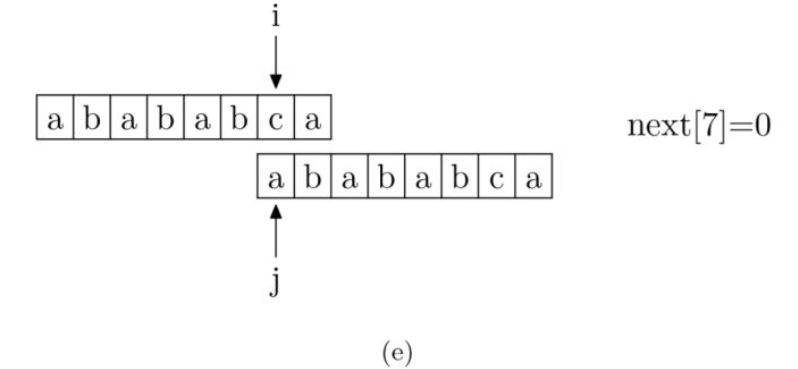
求模式串的next[j] 算法**
现在,我们再看一下如何编程快速求得next数组。其实,求next数组的过程完全可以看成字符串匹配的过程,即以模式字符串为主字符串,以模式字符串的前缀为目标字符串,一旦字符串匹配成功,那么当前的next值就是匹配成功的字符串的长度。
具体来说,就是从模式字符串的第一位(注意,不包括第0位)开始对自身进行匹配运算。 在任一位置,能匹配的最长长度就是当前位置的next值。如下图所示。
void getNext(char * p, int * next)
{
next[0] = -1;
int i = 0, j = -1;
while (i < strlen(p))
{
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
j = next[j];
}
}
/**
* @Description: 求next
* @Param:
* @return:
* @Author:
* @Date:
*/
public static int[] getKMPNext(SString str){
int[] next = new int[str.lenth+1];
int i = 1;
int j = 0;
while (i < str.lenth){
if (j == 0 || str.data[i] == str.data[j]){ //j == 0 也就是j回到了0位置
i++;
j++;
next[i] = j;
}else {
j = next[j];
}
}
return next;
}
由于我们的字符数组是从1开始的,0位置什么都没有存,next[1] 位置默认 0 ,

next 函数的改进
对于相同的字符,跟它一样的字符没有匹配成功,那么next[j] 也不会匹配成功。
我们使用nextval[];用来修正next
根据next值求nextval值的方法
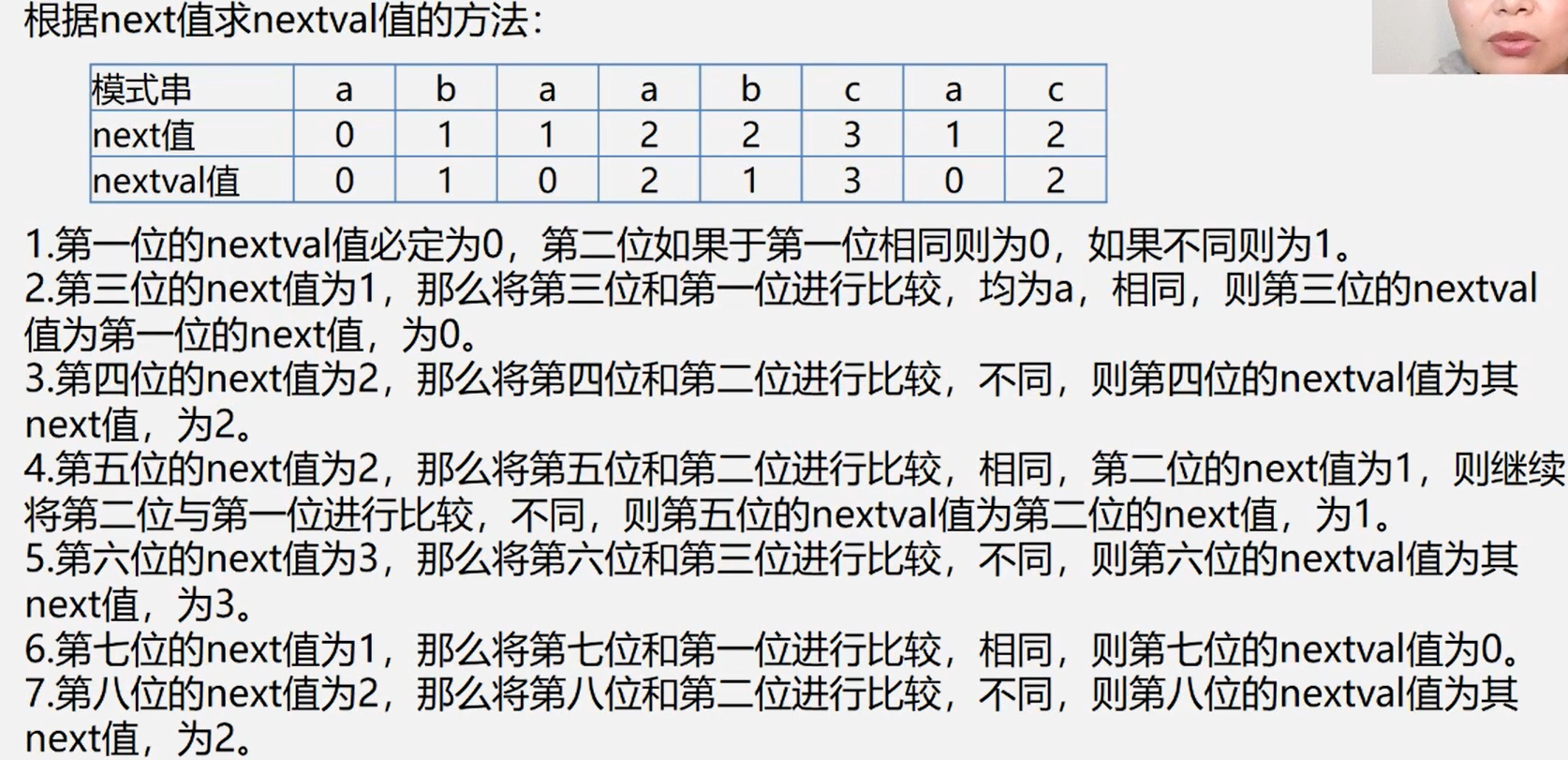
总结规律:
nextval[] 的值根据 next[] 的值获得,
第一位的nextval 值为0,第二位的值如果和第一位相同则 nextval 为0,如果不同则为1.
其余位 将自己的串 与 next[自己的next] 的串相比 ,如果不同则 nextval 等于 自己的next值,如果相同有两种情况:1、相比串的next值是0 那么自己的nextval 值为0 ,2、如果不是0,继续比较,知道有上述两种情况。
完整代码
public class SString {
final int MAXSIZE = 255;
char[] data;
int lenth;
SString(){
data = new char[MAXSIZE];
lenth = 0;
}
void add(char elem){
data[lenth+1] = elem;
lenth++;
}
char get(int index){return data[index];}
/**
* @Description: BF匹配算法
* @Param: 字串
* @return: 子串在正文串中的开始下标,没有返回-1
* @Author:
* @Date:
*/
int indexBF(SString t){
int i = 1; //主串的下标 S
int j = 1; //子串的下标 T
while (i <= lenth && j <= t.lenth){
if (data[i] == t.data[j]){ i++;j++; } //主串和子串一次匹配下一个字符
else {
i = i - j + 2; //主串子串回溯,重新开始下一次匹配
j = 1;
}
}
//判断是否找到 如果找到 子串的下标应该大于子串的长度 , 目标下标为 主串的下标减去子串的长度
System.out.println(i+"--"+j);
System.out.println(i);
if(j > t.lenth) {return i - t.lenth;}
else return -1;
}
/**
* @Description: KPM 算法
* @Param:
* @return:
* @Author:
* @Date:
*/
int indexKMP(SString t){
int i = 1;
int j = 1;
int[] next = SString.getKMPNext(t);
while (i < lenth+1 && j < t.lenth+1){
if (j == 0 || data[i] == t.data[j]){//j == 0 也就是j回到了0位置
i++;
j++;
}else {
j = next[j];
}
}
if(j > t.lenth) {return i - t.lenth;}
else return -1;
}
/**
* @Description: 求next
* @Param:
* @return:
* @Author:
* @Date:
*/
public static int[] getKMPNext(SString str){
int[] next = new int[str.lenth+1];
int i = 1;
int j = 0;
while (i < str.lenth){
if (j == 0 || str.data[i] == str.data[j]){ //j == 0 也就是j回到了0位置
i++;
j++;
next[i] = j;
}else {
j = next[j];
}
}
return next;
}
public static void main(String[] args) {
SString s = new SString();
s.add('a');
s.add('b');
s.add('c');
s.add('a');
s.add('a');
s.add('b');
s.add('b');
s.add('c');
s.add('a');
s.add('b');
s.add('c');
s.add('a');
s.add('a');
s.add('b');
s.add('d');
s.add('a');
s.add('b');
System.out.println(SString.getKMPNext(s));
}
数组
数组:按一定格式列起来的,具有相同类型的数据元素的集合。
一 维数组:若线性表中的数据元素为非结构的简单元素,则称为一维数组。
维数组的逻辑结构:线性结构。定长的线性表。
声明格式:数据类型 变量名称[长度];
例:int num[5] = {0 , 1, 2,3,4}
二维数组:若一维数组中的数据元素又是一维数组结构,则称为二维数组。
二维数组的逻辑结构:
- 非线性结构 每一个数据元素既在一个行表中,又在一个列表中。
- 线性结构 该线性表的每个数据元素也是一个定长的线性表
声明格式:数据类型 变量名称 [行数] [列数]
例:int nun [5] [8]
在C语言中,一个二维数组类型也可以定义为一维数组类型
(其分量类型为一维数组类型),即
typedef elemtype array2[m] [n]
三维数组:若二维数组中的元素又是一个—维数组,则称作三维数组。
n维数组:若n-1维数组中的元素又是一个一维数组结构,则称作n维数组。
结论:线性表结构是数组结构的一个特例而数组结构又是线性表结构的扩展。
数组特点:结构固定——定义后,维数和维界不再改变。
数组基本操作:除了结构的初始化和销毁之外只有取元素和修改元素值的操作。
数组的抽象数据类型
n维数组的抽象数据类型


基本操作

数组的顺序存储
数组特点:结构固定——维数和维界不变。
数组基本操作:初始化、销毁、取元素、修改元素值
所以:一般都是采用顺序存储结构来表示数组。
注意:数组可以是多维的,但存储数据元素的内存单元地址是一维的,因此,在存储数组结构之前,需要解决将多维关系映射到一维关系的问题。
一维数组的位置内存计算

二维数组存储方式

两种顺序存储方式:
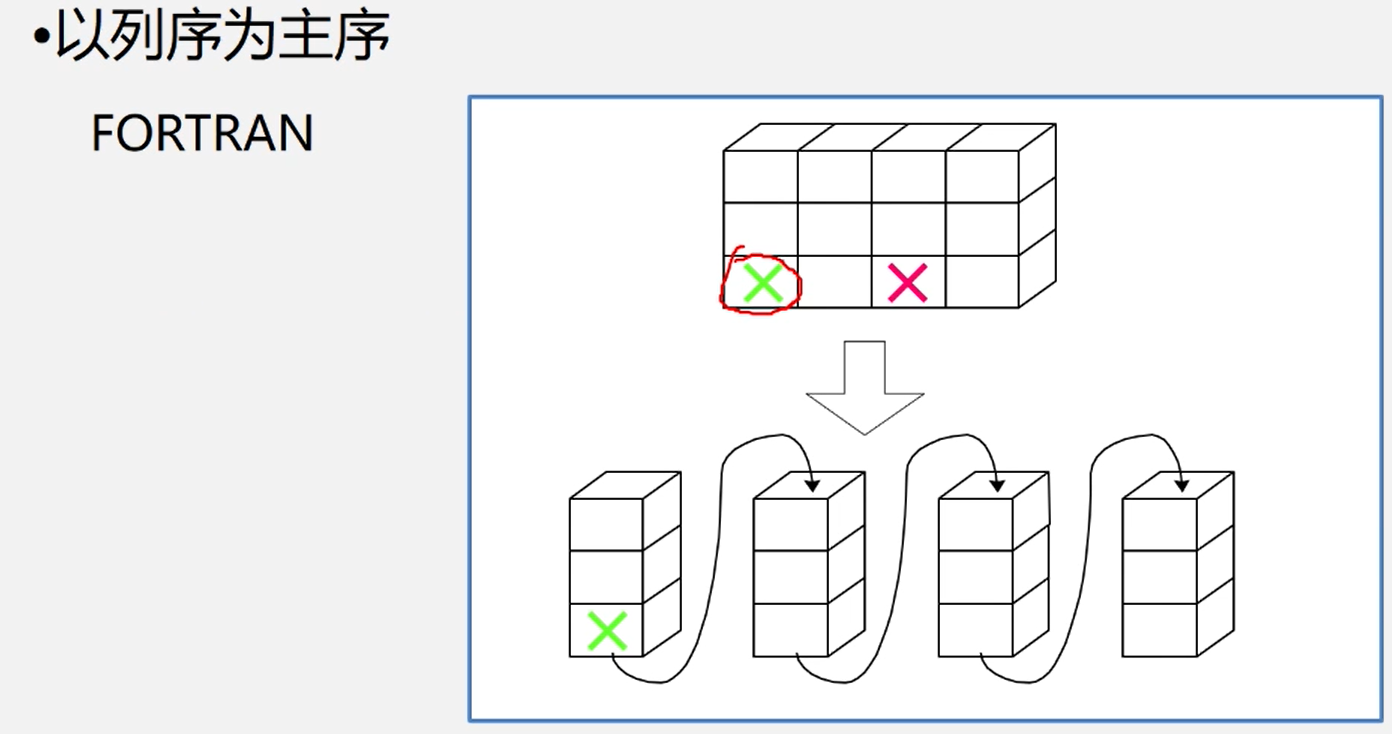
- 以行序为主序(低下标优先)BASIC、 COBOL和 PASCA、java
- 以列序为主序(高下标优先) FORTRAN
存储单元是一维结构,而数组是个多维结构,则用一组连续存储单元存放数组的数据元素就有个次序约定问题。
计算元素位置的思想就是计算元素前面有多少元素,根据一个元素占用的空间和基地址来计算元素的位置


计算二维数组元素的存储位置


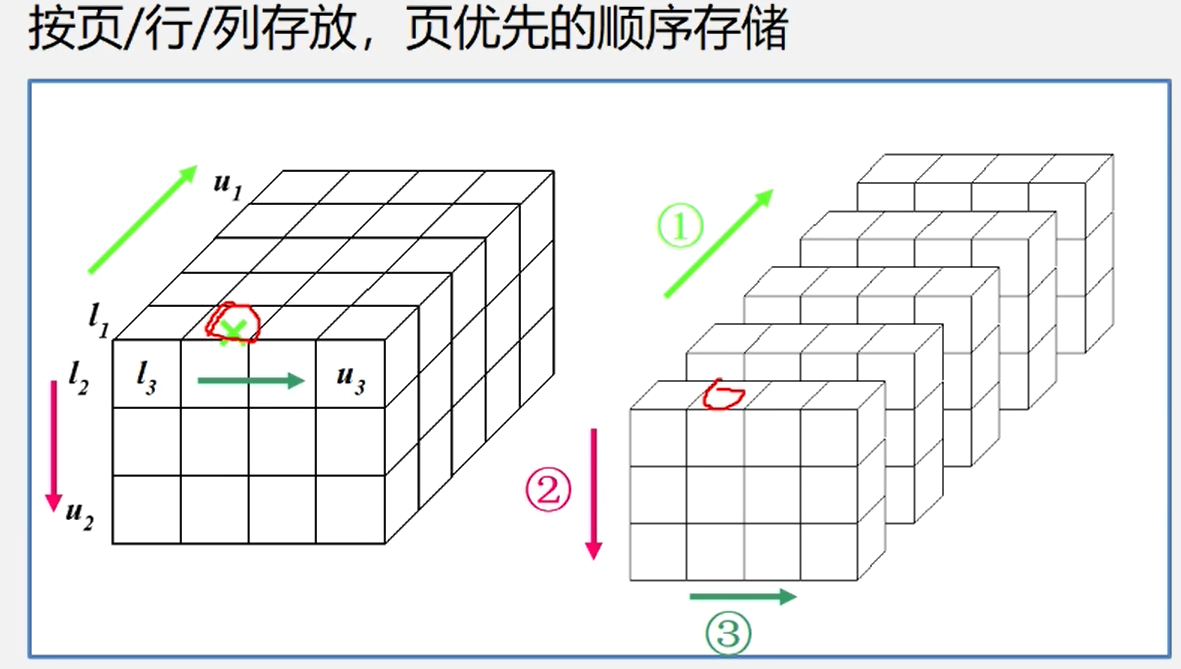
三维数组的存储方式

n维数组

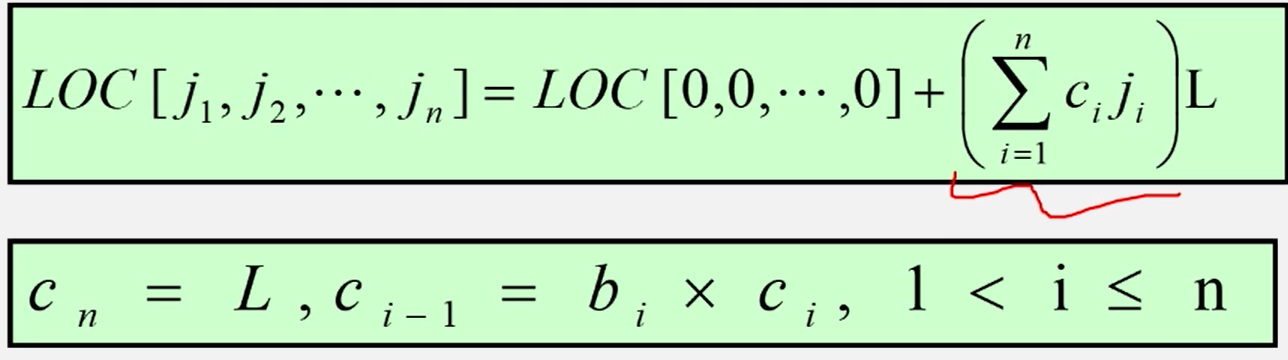
特殊矩阵的压缩存储
矩阵:一个由m×n个元素排成的m行n列的表。
矩阵的常规存储:
将矩阵描述为一个二维数组。
矩阵的常规存储的特点:
可以对其元素进行随机存取;
矩阵运算非常简单;存储的密度为1
不适宜常规存储的矩阵:值相同的元素很多且呈某种规律分布;零元素多。

矩阵的压缩存储:为多个相同的非零元素只分配一个存储空间;对元素不分配空间。
1.什么是压缩存储?
若多个数据元素的值都相同,则只分配一个元素值的存储空间,且零元素不占存储空间。
2.什么样的矩阵能够压缩?
一些特殊矩阵,如:对称矩阵,对角矩阵,三角矩阵,稀疏矩阵等。
3.什么叫稀疏矩阵?
矩阵中非零元素的个数较少(一般小于5%)
对称矩阵的压缩存储
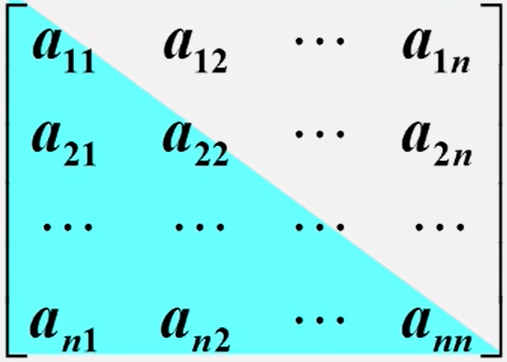
特点:在nxn的矩阵a中,满足如下性质:

存储方法:只存储下(或者上)三角(包括主对角线)的数据元素。共占用n(n+1)2个元素空间。
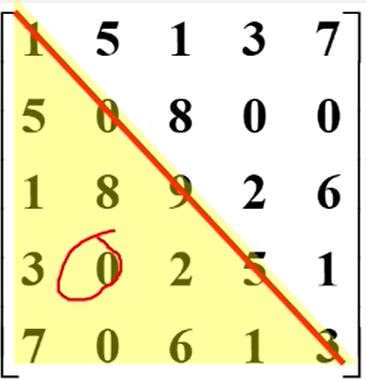
对称矩阵的存储结构:
对称矩阵上下三角中的元素数均为
n(n+1)/2
可以以行序为主序将元素存放在个—维数组
sa[n(n+1)/2 ]中。
例如:以行序为主序存储下三角

三角矩阵的压缩存储
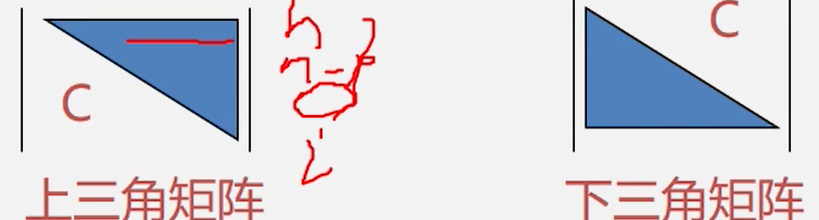
三角矩阵特点: 对角线以下(或者以上)的数据元素(不包括对角线)全部为常数C。

对角矩阵(带状矩阵)
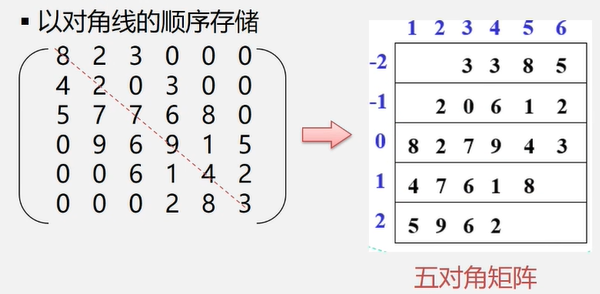
特点:在nxn的方阵中,所有非零元素都集中在以主对角线为中心的带状区域中,区域外的值全为0,则称为对角矩阵。常见的有三对角矩阵、五对角矩阵、七对角矩阵等。

存储方法
以对角线的顺序存储
稀疏矩阵的压缩存储
特点:零元素很多,非零元素很少。
稀疏矩阵:设在m×n的矩阵中有t个非零元素
令 δ = t /(m×n)
当δ≤0.05时称为稀疏矩阵。
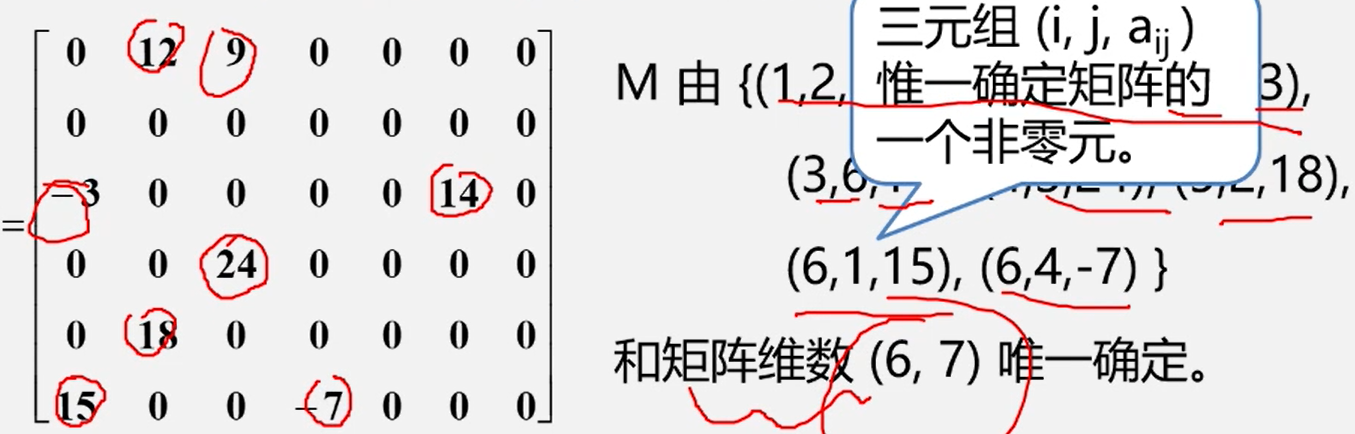
压缩存储原则:存各非零元的值、行列位置和矩阵的行列数。
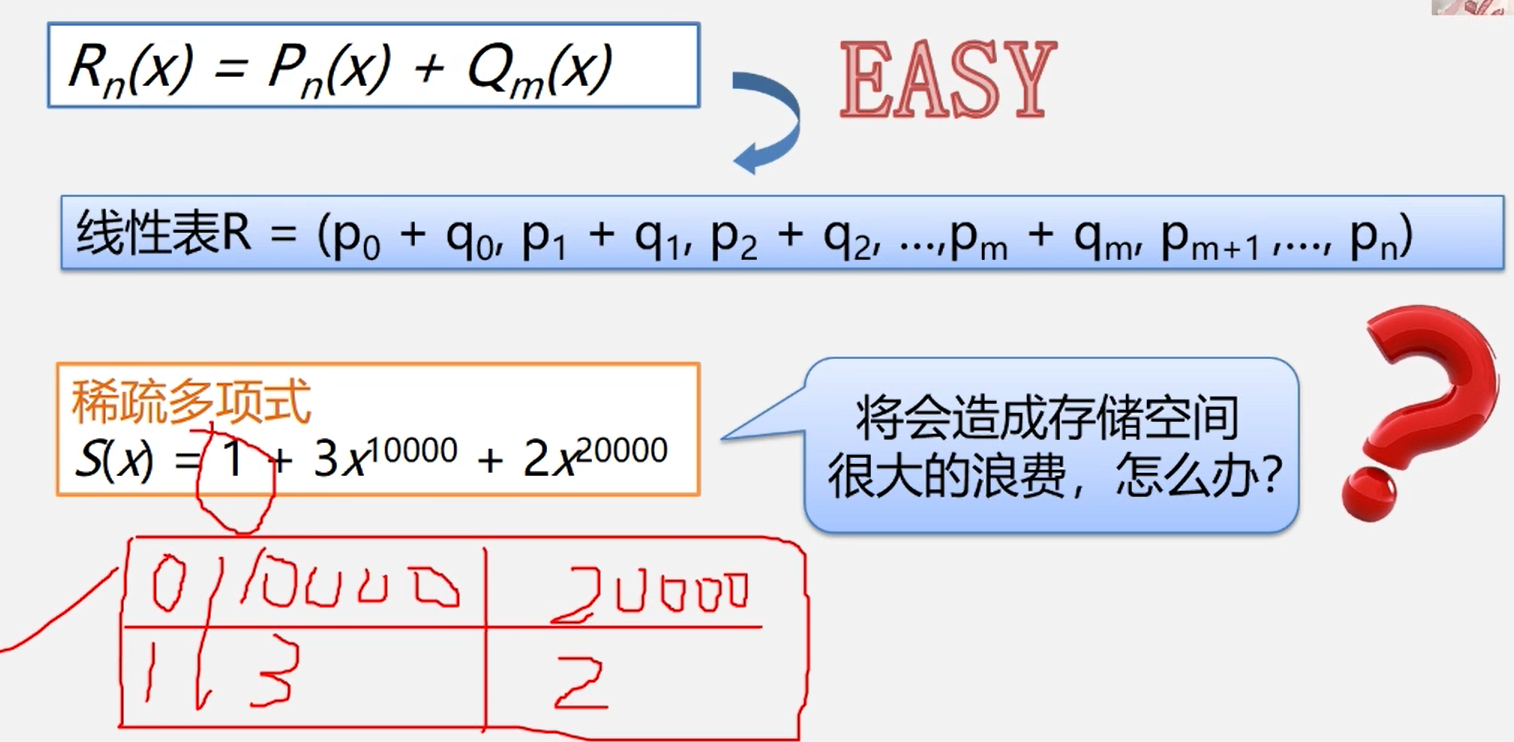
三元组的不同表示方法可决定稀疏矩阵不同的压缩存储方法。
三元组顺序表
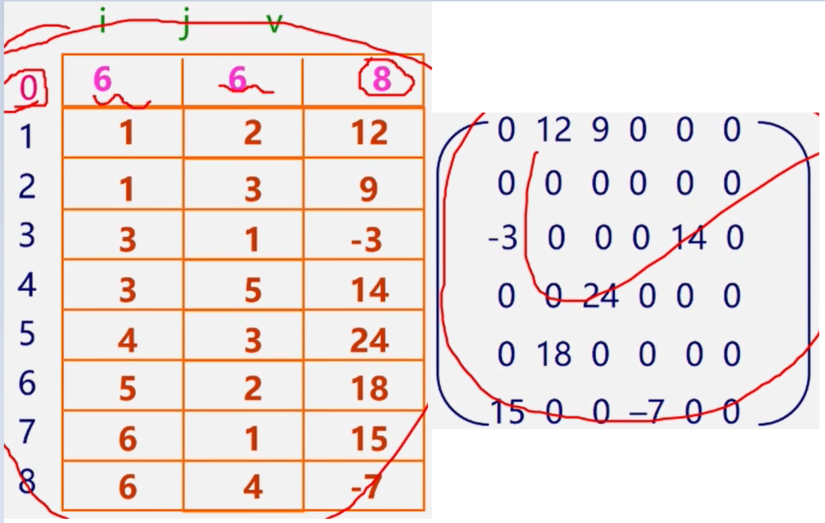
注意:为更可靠描述,通常再加一个总体”信息:即总行数、总列数、非零元素总个数
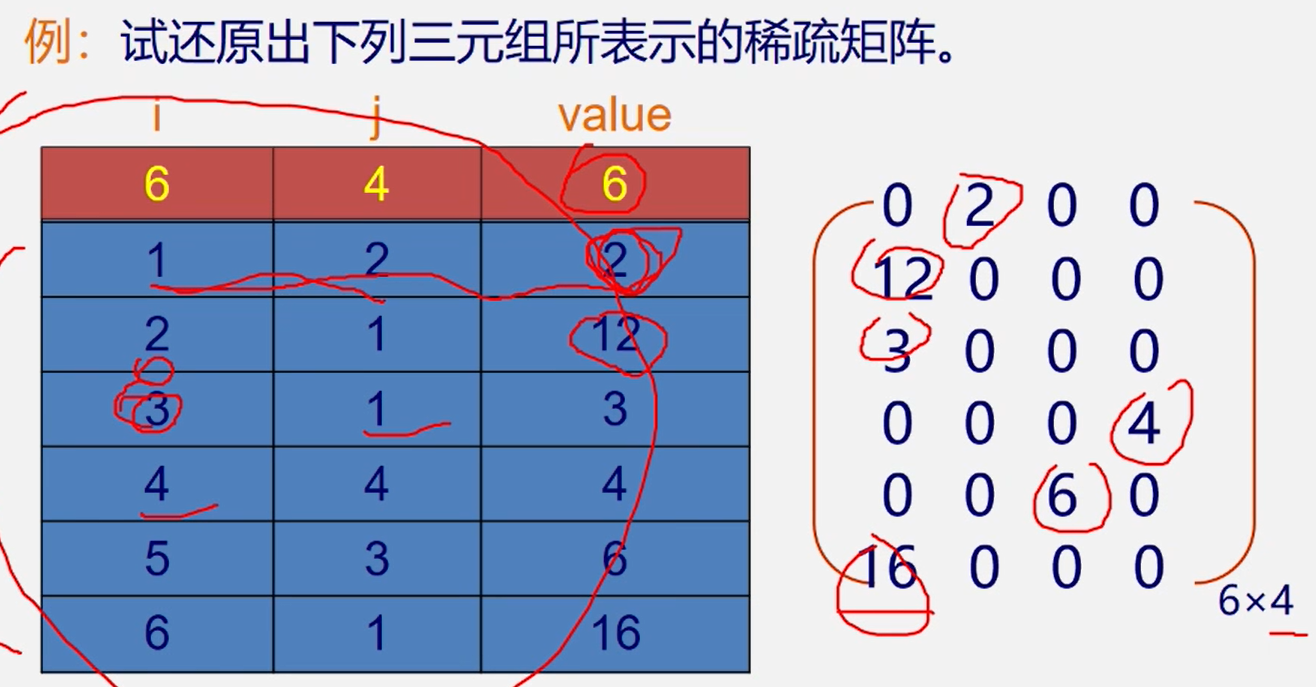
三元组顺序表又称有序的双下标法.
三元组顺序表的优点:非零元在表中按行序有序存储,因此便于进行依行顺序处理的矩阵运算。
三元组顺序表的缺点:不能随机存取若按行号存取某一行中的非零元,则需从头开始进行查找。
十字链表
●优点:它能够灵活地插入因运算而产生的新的非零元素。删除因运算而产生的新的零元素,实现矩阵的各种运算。
●在十字链表中,矩阵的每一个非零元素用一个结点表示,该结点除了(row,col, value)以外,还要有两个域right:用于链接同一行中的下一个非零元素; down:用以链接同一列中的下一个非零元素。
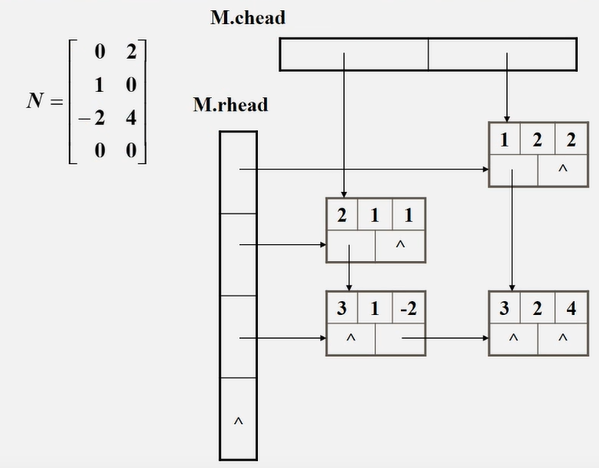
●十字链表中结点的结构示意图
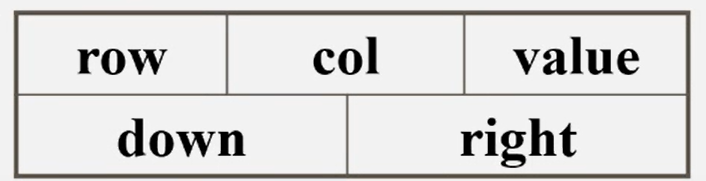
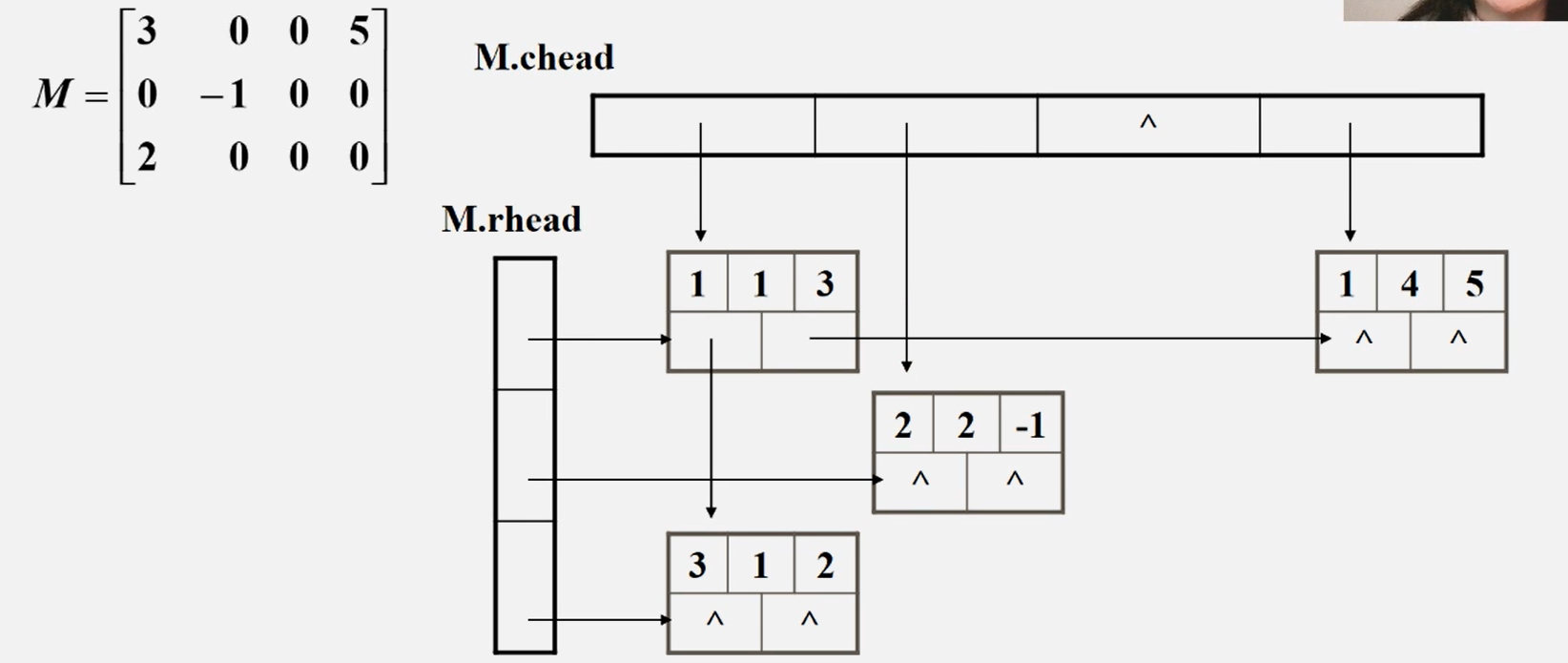
数据节点按照格式存储,还需有行的头节点和列的头节点,头节点记录当前行/列的非零节点
广义表

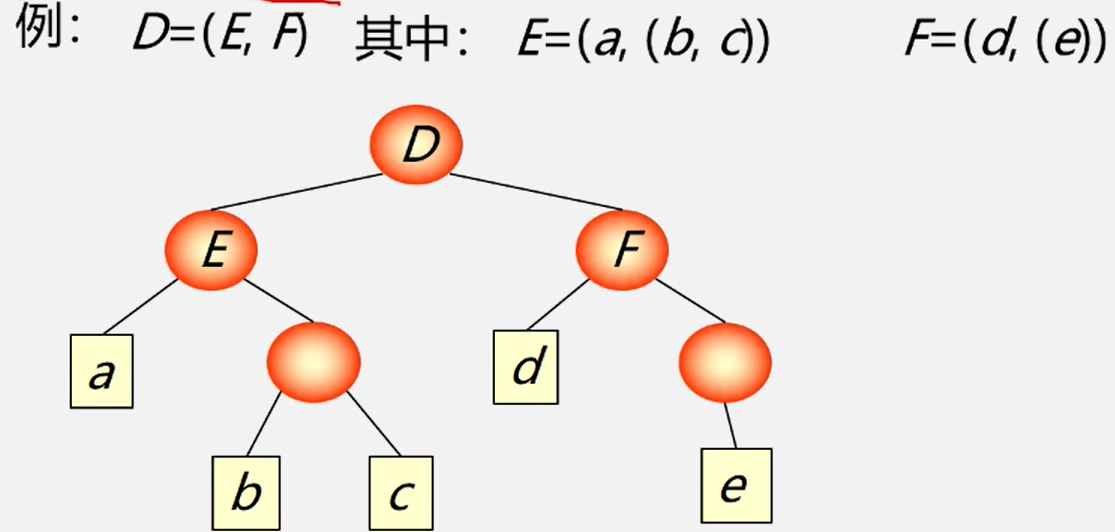
例:中国举办的国际足球邀責赛,赛队名单可表示如下:
(阿根廷,巴西,德国,法国 , () , 西班牙 , 意大利,英国,(国家队,山东鲁能,广州恒大) )
在这个表中,弑利亚以队应排在法国队后面,但未能参加,成为空表。
国家队,山东鲁能,广州恒大均作为东道主的参赛队参加,构成一个小的线性表,成为原线性表的一个数据元素。
这种拓宽了的线性表就是广义表。
义表通常记作:LS = ( a1 , a2 , ... , an)
其中:LS为表名,n为表的长度,每一个ai为表的元素。
习惯上,一般用大写字母表示广义表,小写字母表示原子。
表头:若LS非空(n≥1),则其第一个元素a1就是表头记作 head(LS) = a1 .
注:表头可以是原子,也可以是子表
表尾:除表头之外的其它元素组成的表。
记作tail(LS) =(a2 , ..., an)
注:表尾不是最后一个元素,而是一个子表。

性质
(1)广义表中的数据元素有相对次序;一个直接前驱和一个直接后继
(2)广义表的长度定义为最外层所包含元素的个数;
如:C =(a , ( b , c ) ) 是长度为2的广义表。
(3)广义表的深度定义为该广义表展开后所含括号的重数;
A =( b ,c ) 的深度为1,B = ( A ,d ) 的深度为2,C =( f , B , h ) 的深度为3。
注意:“原子”的深度为0;“空表”的深度为1
(4)广义表可以为其他广义表共享;
如:广义表B就共享表A。 A = () B = (())
在B中不必列出A的值,而是通过名称来引用,B=(A)。
(5)广义表可以是一个递归的表。如:F = ( a , F) = ( a , ( a , (a ,...)))
注意:递归表的深度是无穷值,长度是有限值。
(6)广义表是多层次结构,广义表的元素可以是单元素,也可以是子表,而子表的元素还可以是子表,可以用图形象地表示。
广义表与线性表的区别?
广义表可以看成是线性表的推广,线性表是广义表的特例。
广义表的结构相当灵活,在某种前提下,它可以兼容线性表、数组、树和有向图等各种常用的数据结构。
当二维数组的每行(或每列)作为子表处理时,二维数组即为一个广义表。
另外,树和有向图也可以用广义表来表示。
由于广义表不仅集中了线性表、数组、树和有向图等常见数据结构的特点,而且可有效地利用存储空间,因此在计算机的许多应用领域都有成功使用广义表的实例。
广义表的基本运算
(1)求表头 GetHead(L):非空广义表的第一个元素,可以是也可以是一个子表
(2)求表尾 Get Tail(L):非空广义表除去表头元素以外其它元素所构成的表。表尾一定是一个表
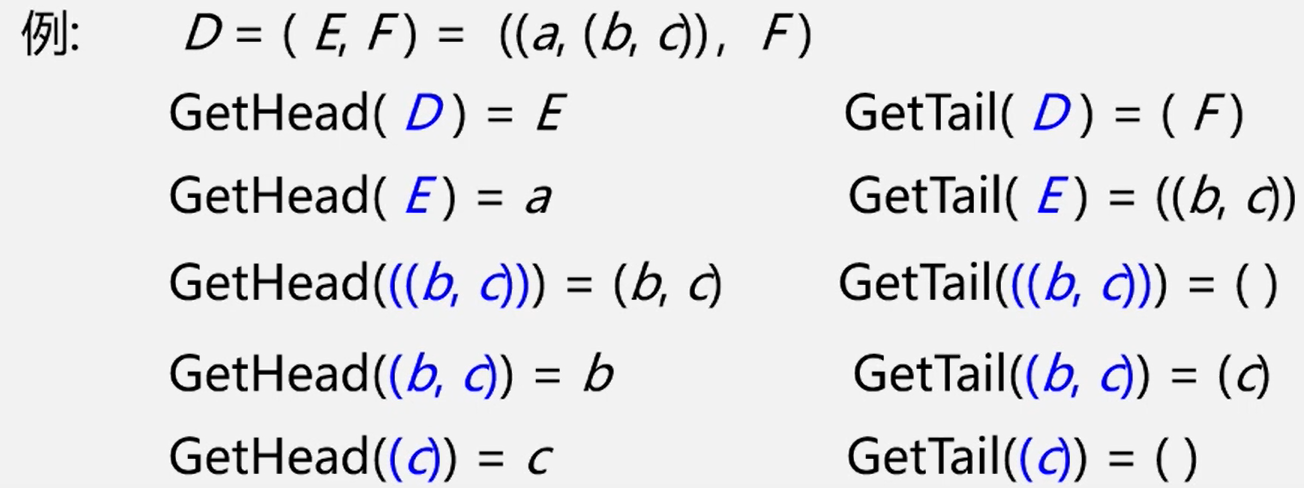
非线性结构
树型结构
树形结构又称为非线性结构:特点是节点之间有分支,具有层级关系
例:
-
自然界
- 树
-
人类社会
- 家谱
- 行政组织机构
-
计算机领域
- 编译:用树表示源程序的语法结构
- 数据库系统:用树组织信息
- 算法分析:用树描述执行过程
-
文件系统
树的定义
树的定义:
树( Tree )是n(n≥0)个结点的有限集
若n=0,称为空树;若n>0,则它满足如下两个条件
(1)有且仅有一个特定的称为根(Root)的结点
(2)其余结点可分为m(m≥0)个互不相交的有限集T1,T2,T3,…, Tm,其中每一个集合本身又是一棵树,并称为根的子树( Subtree)。显然,树的定义是一个递归的定义。
树是n个结点的有限集。
树的其它表示方式
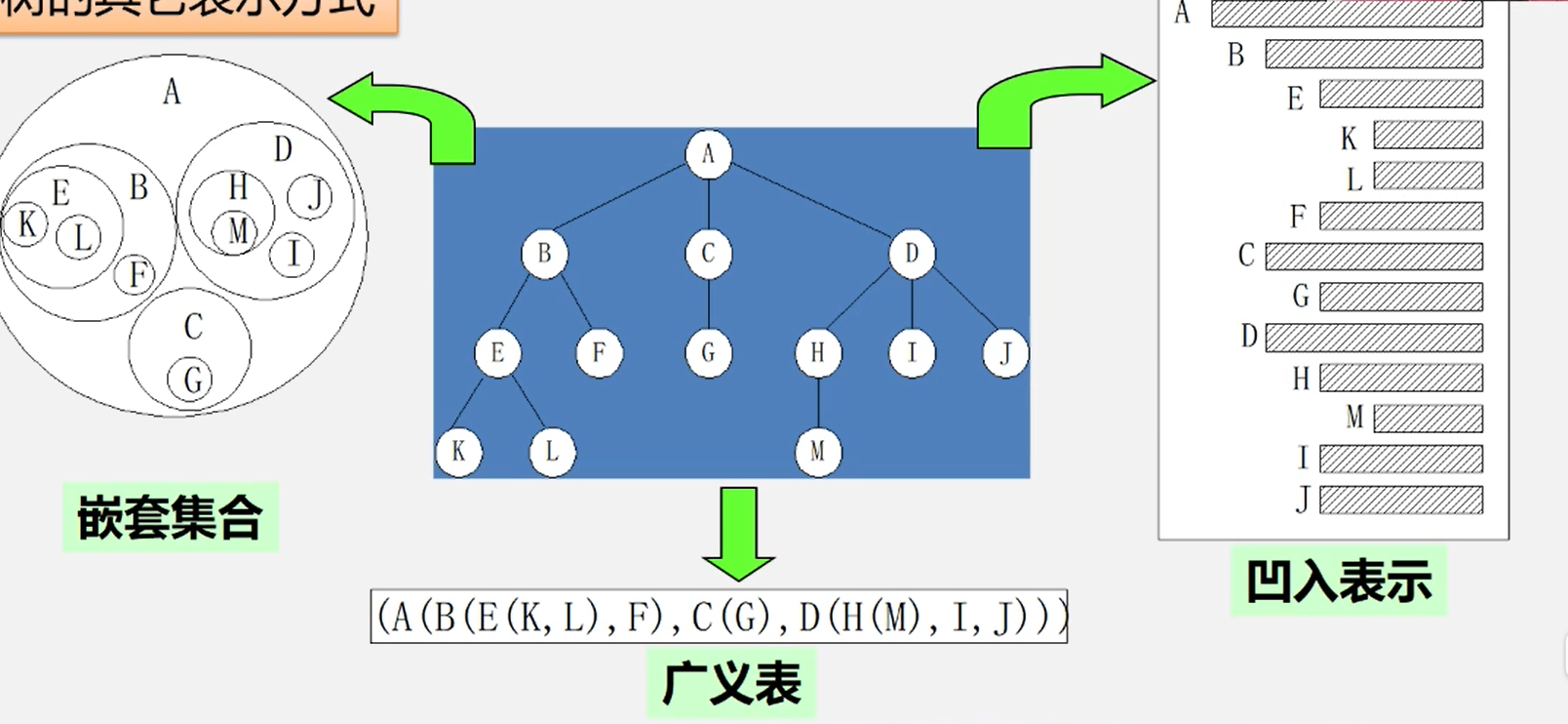
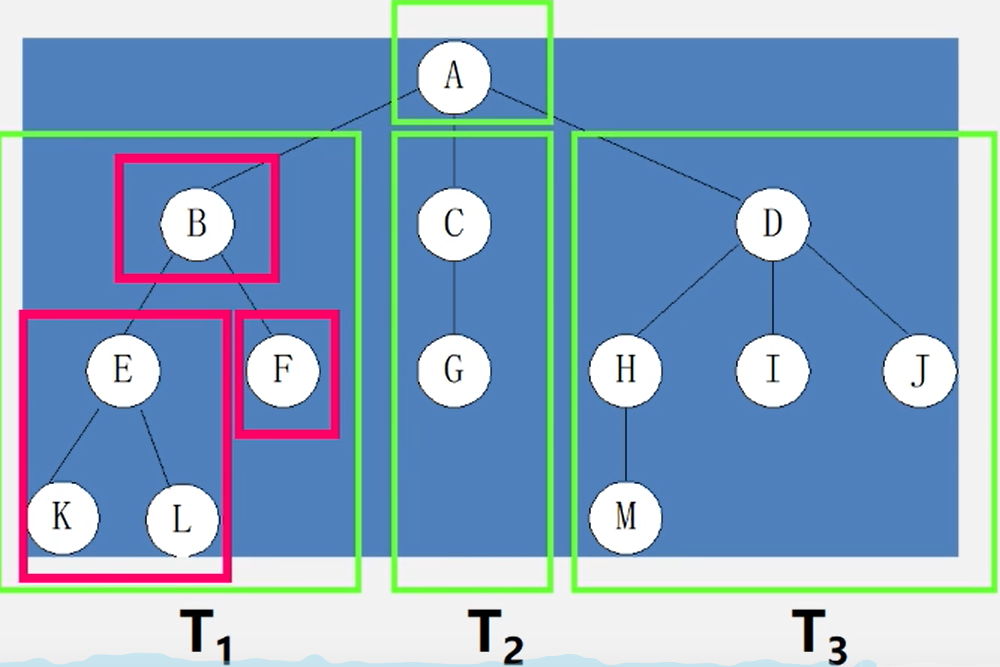
树的基本术语
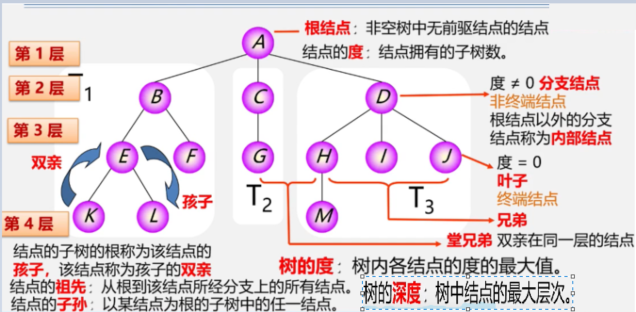
根节点:非空树中无前驱结点的结点。图中A结点为根节点
结点的度结点拥有的子树数。也就是结点有几个后继树,那么这个树叫做结点的度。图中A结点的度为b 、 c 、d 树
树的度:树内各结点的度的最大值。图中A树的度为3,B树的度是2,c树的度是1,D树的度是3
叶子结点/终端结点:没有后继结点的结点成为叶子结点,也就是度 = 0 。图中 K L F G M I J 为叶子结点。
分支结点:也就是非终端结点,度 ≠ 0 ,根结点以外的分支结点称为内部结点.也就是除根节点外有后继结点的结点。图中B C D E H 为内部结点。
双亲/孩子:结点的子树的根称为该结点的孩子,该结点称为孩子的双亲.图中A结点的孩子是B C D,BCD的双亲是A。
兄弟结点:一些结点有共同的双亲,称这些结点为兄弟结点。图中 H I J 的双亲是D,我们把H I J 称为兄弟结点。
堂兄弟:双亲在同一层的结点。根结点在第一层,根节点的孩子结点在第二层,以此类推。在图中K L M 的双亲E H 都在第三层,那么K L M 结点就是堂兄弟结点。
结点的祖先: 从根到该结点所经过分支上的所有结点。图中从A结点到M结点要经过 A D H 结点,那么我们把 A D H 称为M的祖先。
结点的子孙: 以某结点为根的子树中的任一结点。图中B结点的子孙是 E F K L 结点。
树的深度/高度:树中结点的最大层次。图中A树的层数/高度为4
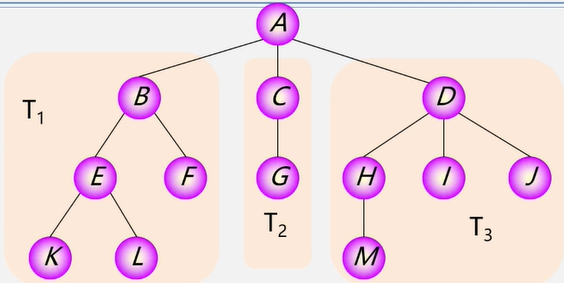
有序树:树中结点的各子树从左至右有次序(最左边的为第一个孩子)。
无序树:树中结点的各子树无次序。
森林:是m(m ≥ 0)棵互不相交的树的集合。
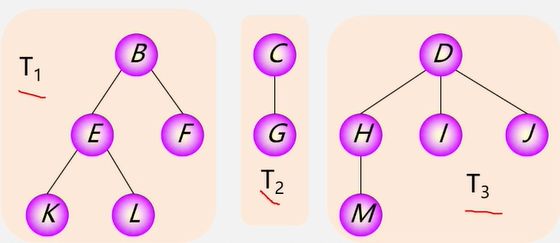 把根结点删除树就变成了森林
把根结点删除树就变成了森林
一棵树可以看成是一个特殊的森林。
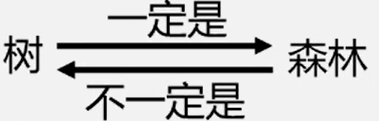
树结构和线性结构比较

二叉树的定义
为何要重点研究每结点最多只有两个“叉”的树?
-
二叉树的结构最简单,规律性最强
-
可以证明,所有树都能转为唯一对应的二叉树,不失一般性。
普通树(多叉树)若不转化为二叉树,则运算很难实现
二叉树在树结构的应用中起着非常重要的作用,因为对二叉的许多操作算法简单,而任何树都可以与二叉树相
互转换,这样就解决了树的存储结构及其运算中存在的复杂性。
什么是二叉树:
二叉树是 n ( n ≥ 0 ) 个结点的有限集,它或者是空集( n = 0 ),或者由一个根结点及两棵互不相交的分别称作这个根的左子树和右子树的二叉树组成。
特点
- 每个结点最多有俩孩子(二叉树中不存在度大于2的结点)
- 子树有左有之分,其次序不能颠倒
- 二叉树可以是空集合,根可以有空的左子树或空的右子树
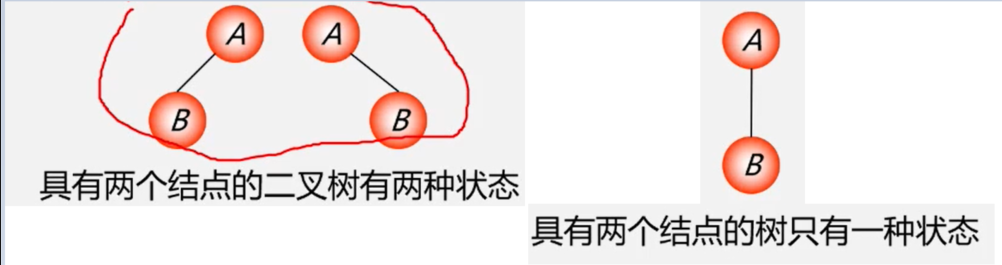
注意: 二叉树不是树的特殊情况,它们是两个概念。
二叉树结点的子树要区分左子树和右子树,即使只有一棵子树也要区分,说明它是左子树,还是右子树。
树当结点只有一个孩子时,就无须区分它是左还是右的次序。因此者是不同的。这是二叉树与树的最主要的差别
也就是二叉树每个结点位置或者说次序都是固定的,可以是空,但是不可以说它没有位置,而树的结点位置是相对于别的结点来说的,没有别的结点时,它就无所谓左右了
思考:具有3个结点的二叉树可能有几种不同形态?普通树呢?
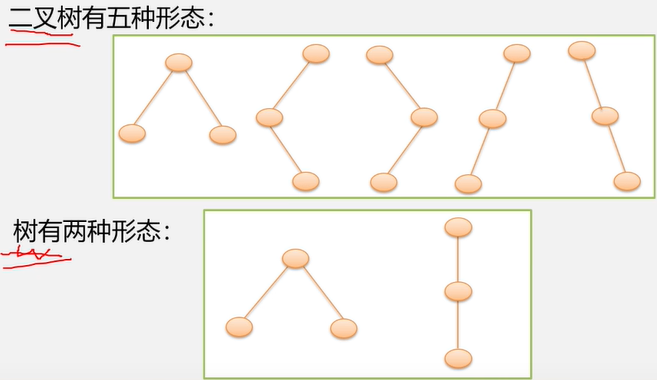
二叉树的5种基本形态

注:虽然二叉树与树概念不同,但有关树的基本术语对二又树都适用
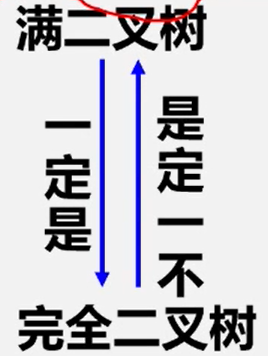
两种特殊形式的二叉树
为何要研究这两种特殊形式?
因为它们在顺序存储方式下可以复原!
满二叉树

特点:
- 每一层上的结点数都是最大结点数(即每层都满)
- 叶子节点全部在最底层
满二叉树在同样深度的二叉树中结点个数最多
满二叉树在同样深度的二叉树中叶子结点个数最多
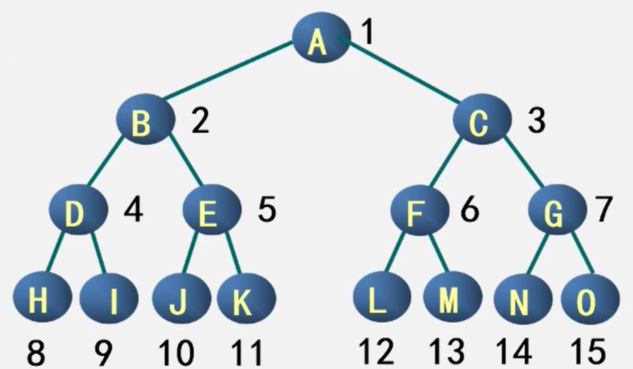
对满二叉树结点位置进行编号:
-
编号规则:从根结点开始,
自上而下,自左而右。 -
每结点位置都有元素。
思考:下图中的二叉树是满二叉树吗? 不满足满二叉树的性质。不是满二叉树。。
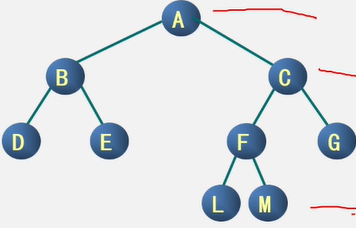
完全二叉树
深度为 k 的具有 n 个结点的二叉树,当且仅当其每一个结点都与深度为 k 的满二叉树中编号为 1 ~ n 的结点对应时,称之为完全二叉树。
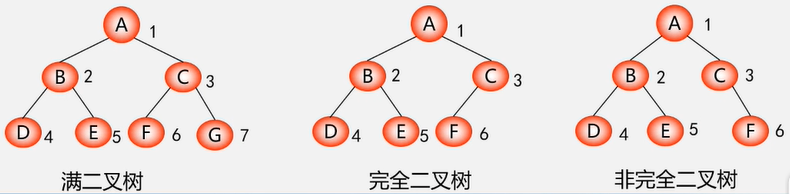
判断一下树是不是完全二叉树?
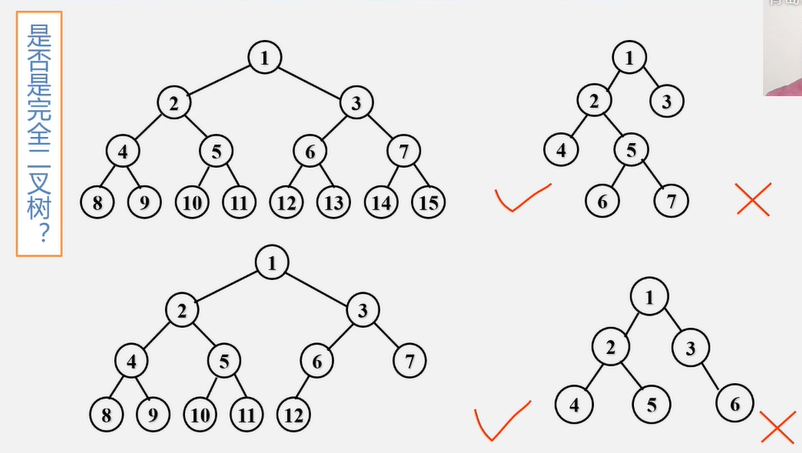
注:在满二叉树中,从最后一个结点开始,连续去掉任意个结点,即是一棵完全二叉树 一定是连续的去掉!!!
特点:
1.叶子只可能分布在层次最大的两层上。
2.对任一结点,如果其右子树的最大层次为i,则其左子树的最大层次必为i或i+1。
线索二叉树
问题:为什么要研究线索二叉树?
当用二叉链表作为二叉树的存储结构时,可以很方便地找到某个结点的左右孩子;但般情况下,无法直接找到该结点在某种遍历序列中的前驱和后继结点
提出的问题:如何寻找特定遍历序列中二叉树结点的前驱和后继???
解决的方法:
1、通过遍历寻找—费时间
2、再增设前驱、后继指针域——增加了存储负担。
3、利用二叉链表中的空指针域。
利用二叉链表中的空指针域:
如果某个结点的左孩子为空,则将空的左孩子指针域改为指向其前驱;如果某结点的右孩子为空,则将空的右孩子指针域改为指向其后继。——————这种改变指向的指针称为“线索”
左边为空指向遍历顺序的前驱,右边为空指向遍历顺序的后继
加上了线索的二叉树称为线索二叉树( Threaded Binary Tree)
对二叉树按某种遍历次序使其变为线索二叉树的过程叫线索化
新的问题,指针增加后并不知道指针之乡的是他的孩子的指针还是指向前驱或者后继的指针。
为区分 lrchid和 rchild指针到底是指向孩子的指针,还是指向前驱或后继的指针,对二叉链表中每个结点增设两个标志域ltag和rtag,并约定:
ltag=0 lchild指向该结点的左孩子
tag=1 lchild指向该结点的前驱
rtag=0 rchild指向该结点的右孩子
tag=1 rchild指向该结点的后继
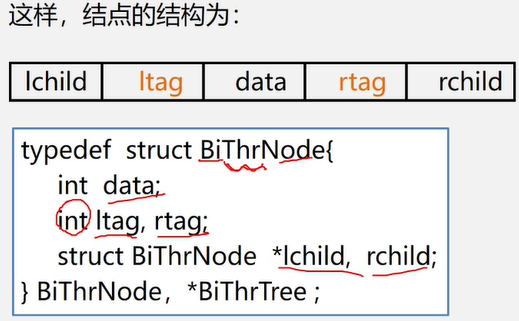
class BiThrNode{
char data;
int ltag;
int rtag;
BiNode leftChild; //左孩子
BiNode rigthChild; //右孩子
}
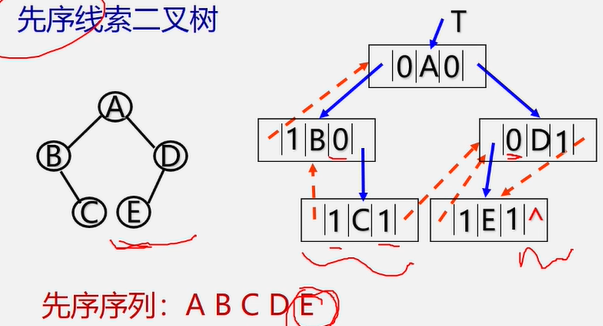
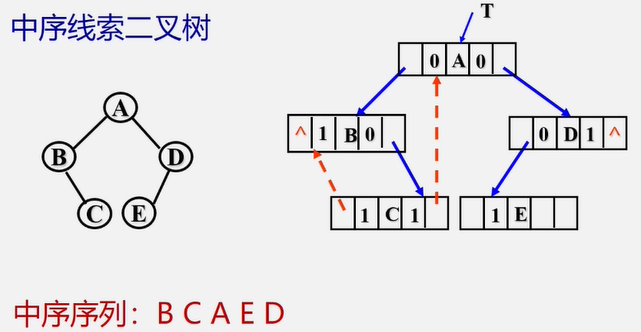
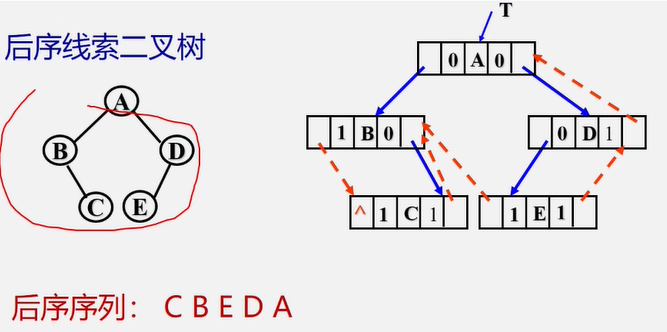
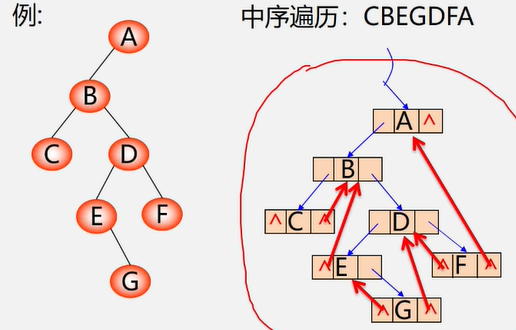
练习:画出一下二叉树对应的中序线索二叉树。
该二叉树中序遍历结果为:H,D,L,B,E,A,F,C,G
增加了头节点的线索二叉树
发现有两个指针指向空。
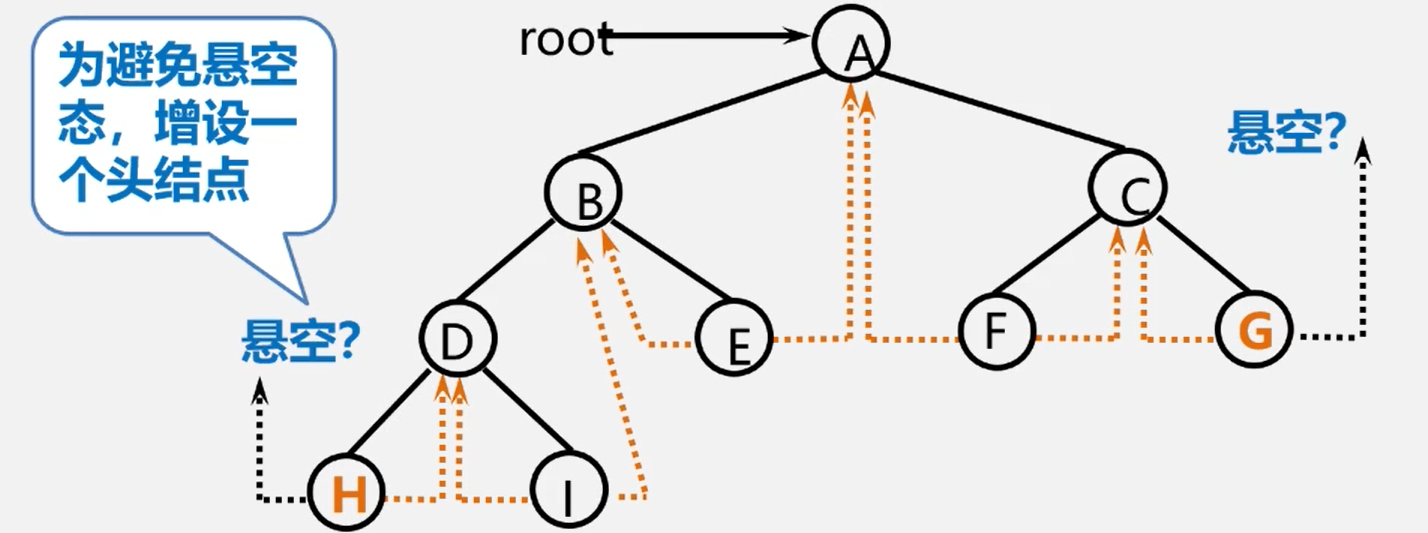
增设了一个头结点:
ltag=0, lchild指向根结点,
rtag=1, rchild指向遍历序列中最后一个结点
遍历序列中第一个结点的 lchild 域和最后一个结点的 rchild 域都指向头结点
案例引入
案例1、数据压缩问题
将数据文件转换成由0、1组成的二进制串,称之为编码。
案例2、利用二叉树求解表达式的值
以二叉树表示表达式的递归定义如下
(1)若表达式为数或简单变量,则相应二叉树中仅有个根结点,其数据域存放该表达式信息;
(2)若表达式为“第一操作数 运算符 第二操作数” 的形式,则相应的二叉树中以左子树表示第一操作数,右子树表示第二操作数,根结点的数据域存放运算符(若为一元运算符,则左子树为空),其中,操作数本身又为表达式。

树和二叉树的抽象数据类型定义
由于树和二叉树非常相似,这里只讲二叉树的抽象数据类型定义。


二叉树的性质
性质1、第 i 层最大结点个数


第 i 层上至少有1个结点
性质2、深度为K的二叉树最多结点数

深度为K 时 至少有K 个结点。
性质3、叶子数与度为2结点数关系
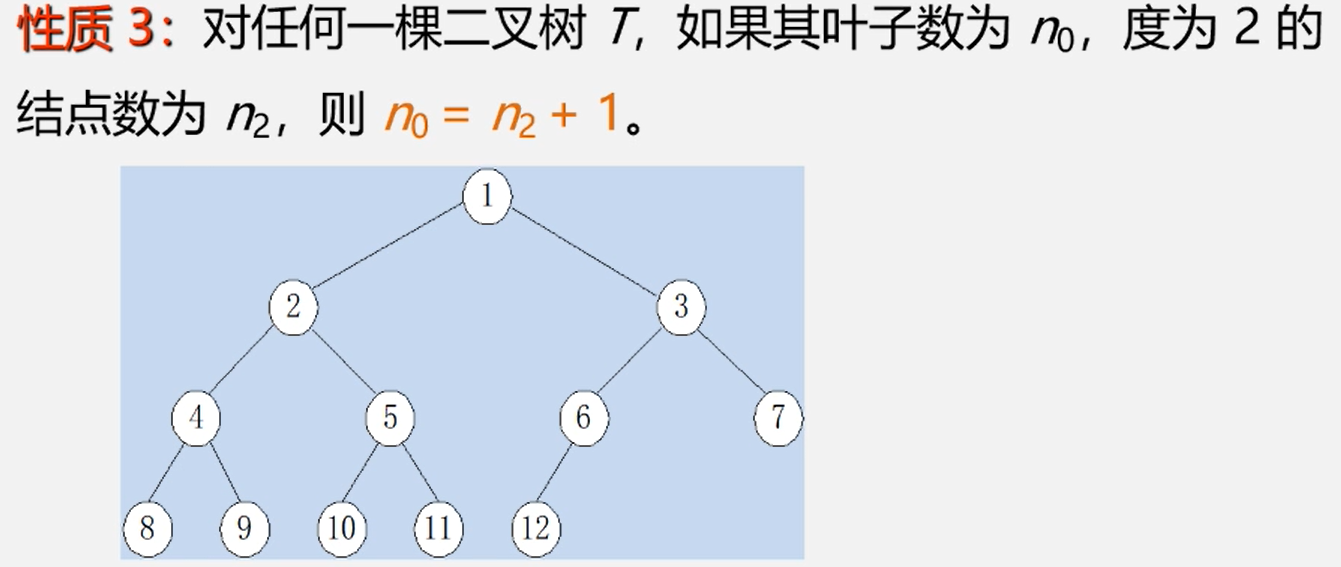
推导:
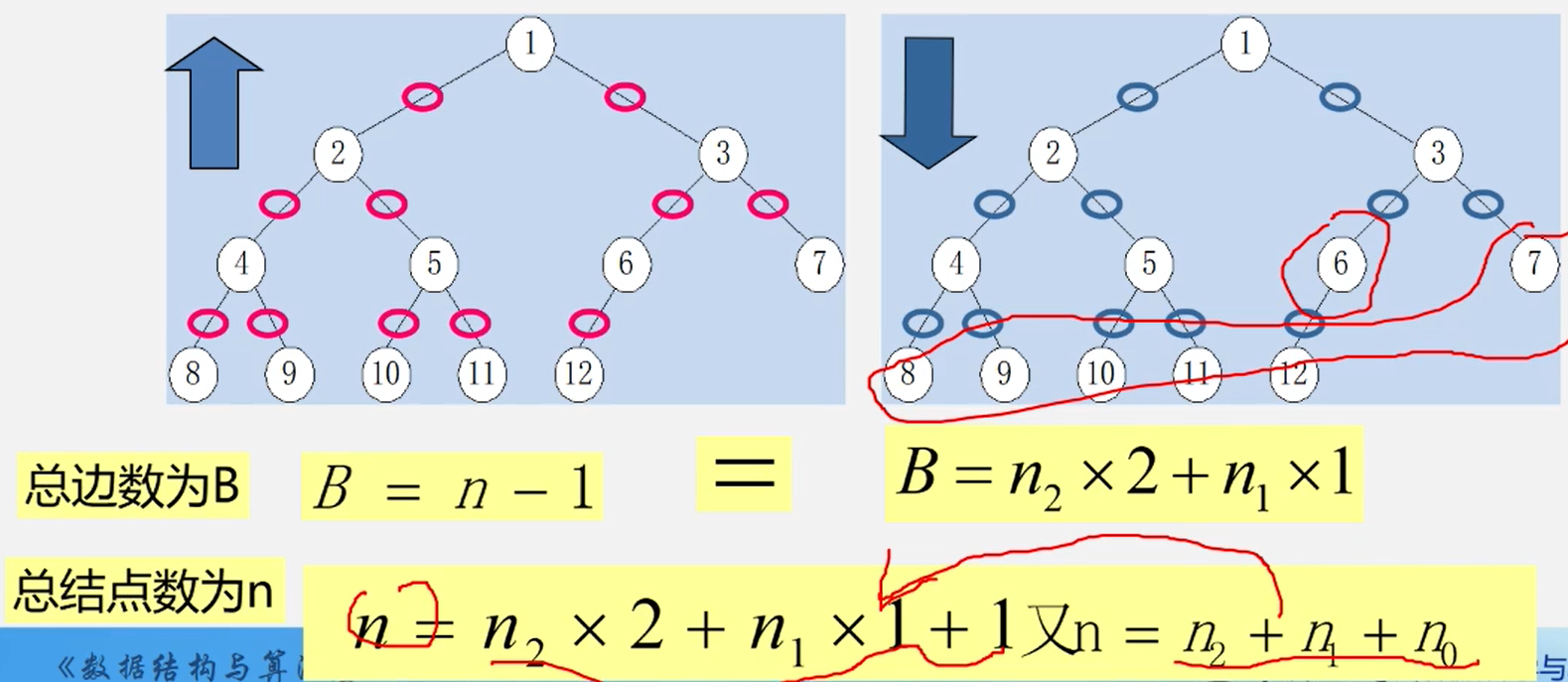
性质4、完全二叉树的结点数和深度关系
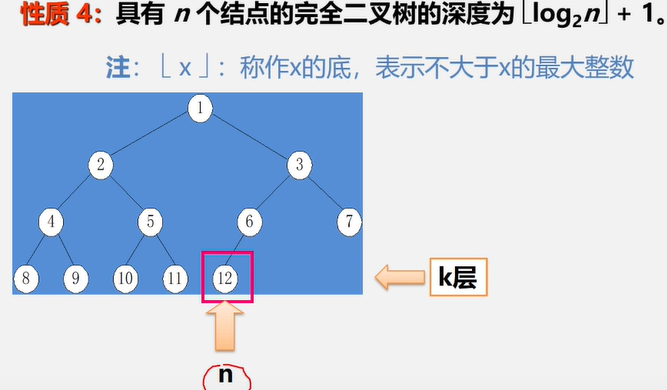
例如上图树中结点数为12,以2为底 12 的对数 是 3.x ~ 4 之间,最大整数为 3 ,根据公式 3 + 1 = 4 那么树的深度为4
证明过程:

性质5、完全二叉树中双亲结点编号与孩子结点编号之间的关系

1、如果 i = 2 那么 i 的双亲结点编号为 即 2 / 2 = 1 所以双亲结点的编号是1
即 2 / 2 = 1 所以双亲结点的编号是1
2、如果 i = 7 , 那么 2 * 7 > 12 则编号为7 的结点为叶子结点,没有左孩子,
如果 i = 6 , 那么 2 * 6 > 12 不成立 则 编号为6的结点的左孩子为 2 * 6 = 12 , 所以编号为6的左孩子编号为 12
3、如果 i = 6 , 那么 2 * 6 + 1 > 12 成立 则 编号为6的结点的没有右孩子。
如果 i =4 , 那么 2 * 4 + 1 > 12 不成立 则 编号为4的结点的右孩子是 2 * 4 + 1 = 9, 所以编号为4的右孩子编号 为9
证明过程(归纳法)

二叉树的存储结构
- 顺序存储结构
- 链式存储结构
- 二叉链表
- 三叉链表
二叉树的顺序存储结构
实现:按满二叉树的结点层次编号,依次存放二叉树中的数据元素。
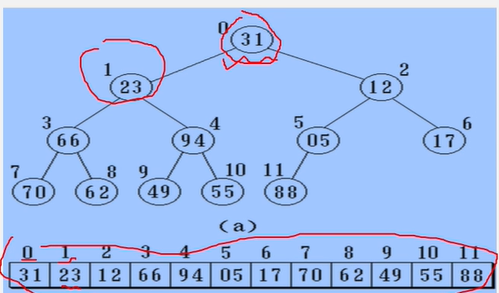
//二叉树的顺序存储表示
#defind MAXSIZE 100
Typedef TElemType SqBiTree[MAXSIZE]
SqBitree bt;
有空结点的二叉树存储方式

【例】二叉树结点数值采用顺序存储结构,如图所示。画出二叉树表示
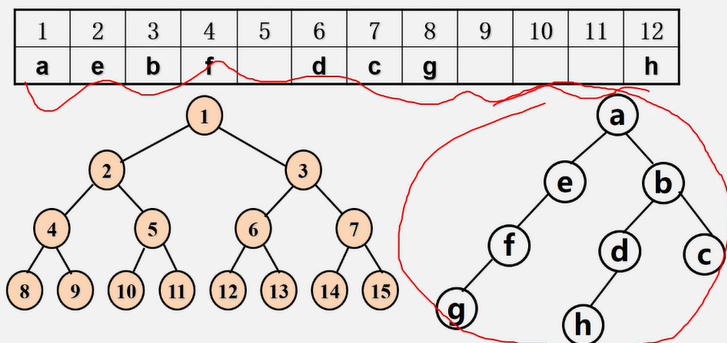
顺序存储的缺点:
最坏情况:深度为k的且只有k个结点的单支树需要长度为 2的K次方 -1 的一维数组。


顺序存储的特点:
结点间关系蕴含在其存储位置中浪费空间,适于存满二叉树和完全二叉树
二叉树的链式存储结构
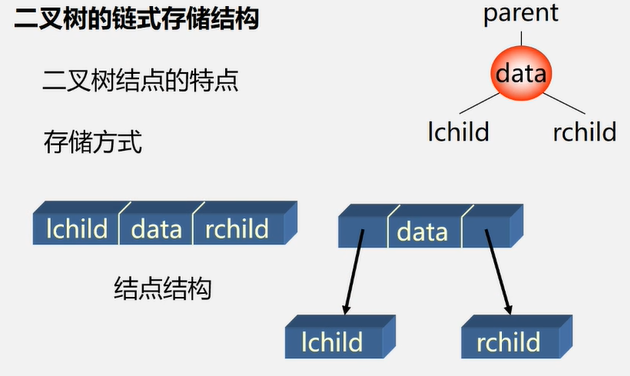
//二叉链表存储结构
typedef struct BiNode{
TElemType data;
struct BiNode *lchild , *rchild;//左右孩子指针
}BiNode,*BiTree;
public class BiTree {
class BiNode{
char data;
BiNode leftChild;
BiNode rigthChild;
}
BiNode root;
}

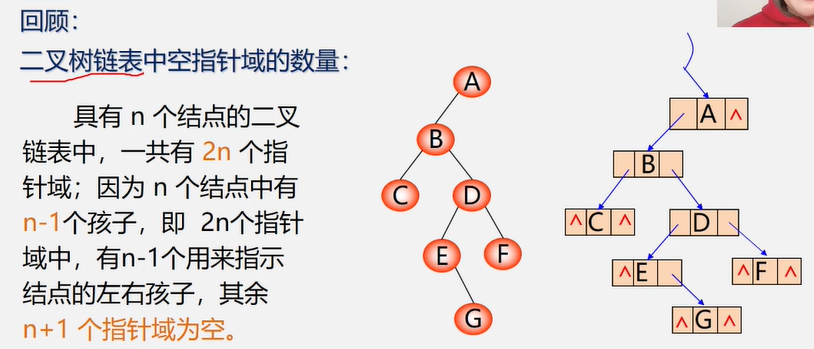
【思考】在n个结点的二叉链表中,有多少个空指针域
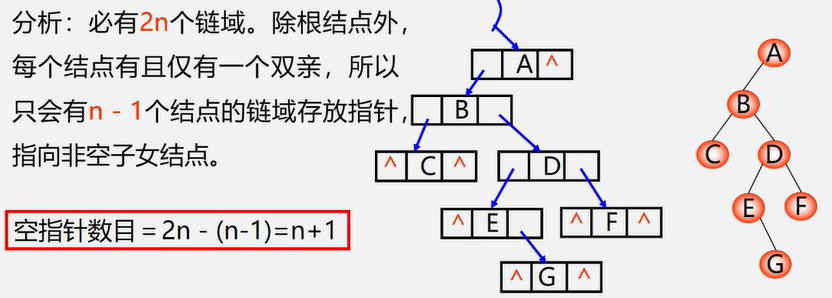
三叉链表
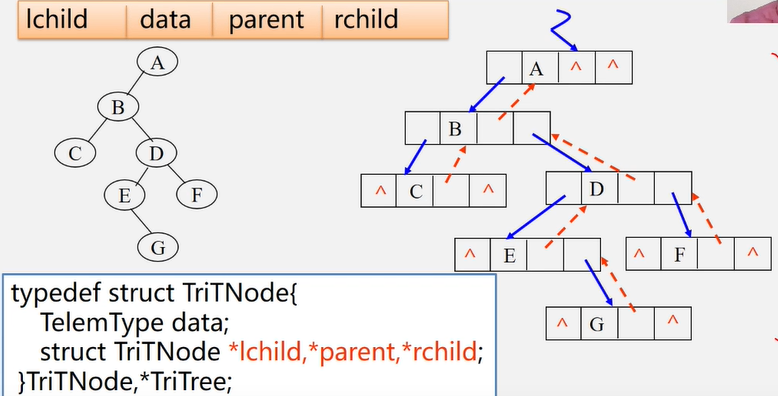
typedef struct TriTNode{
TelemType datal;
struct TriTNode *lchild,*parent,*rchild;
}TriTNode,*TriTree
遍历二叉树和线索二叉树
遍定定义:顺着某一条搜索路径巡访二叉树中的结点,使得每个结点均被访问一次,而且仅被访问一次(又称周游)。
“访问”的含义很广,可以是对结点作各种处理,如:输出结点的信息、修改结点的数据值等,但要求这种访问不破坏原来的数据结构。
遍历目的:得到树中所有结点的一个线性排列
遍历用途:它是树结构插入、删除、修改、查找和排序运算的前提,是二又树一切运算的基础和核心
遍历方法
依次遍历二叉树中的三个组成部分,便是遍历了整个二叉树
假设:L:遍历左子树,D访问根结点,R遍历右子树。则遍历整个二叉树方案共有
DLR、LDR、 LRD ,DRL、RDL、RLD六种。我们重点研究前三种。


算法描述:

由二叉树的递归定义可知,遍历左子树和遍历右子树可如同遍历二叉树一样“递归”进行
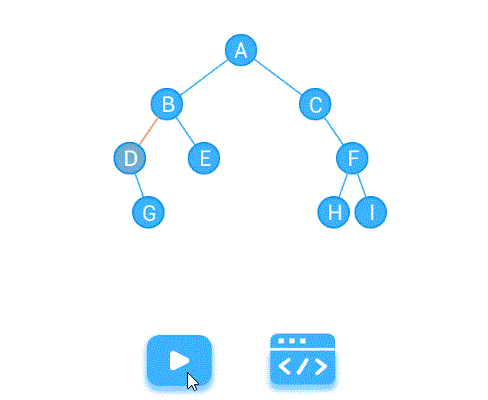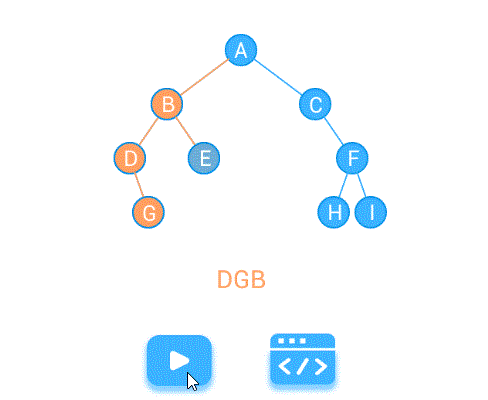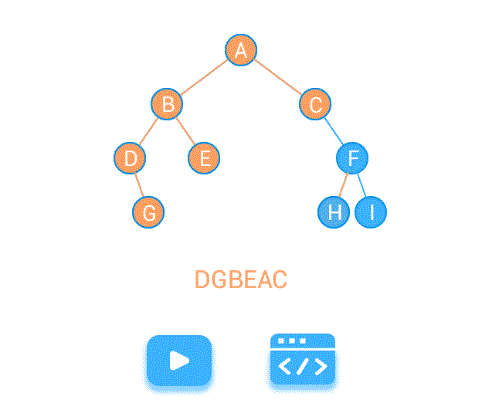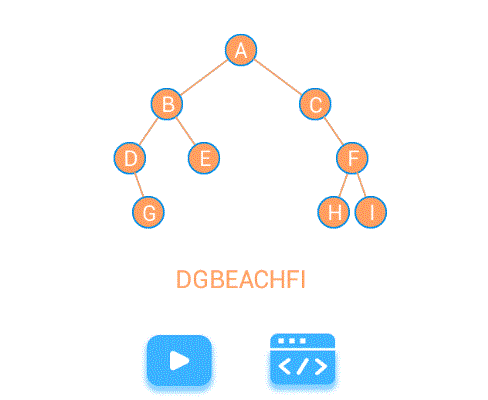
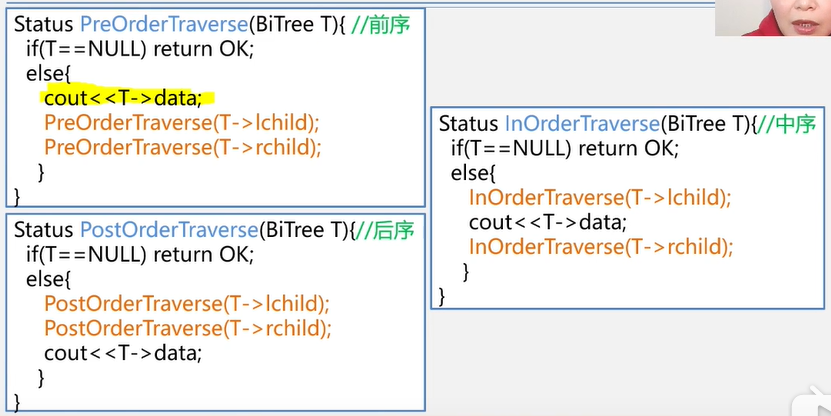
先序遍历 DLR
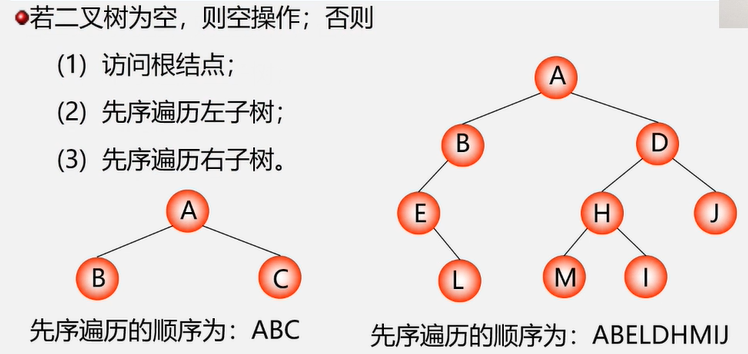
先序遍历递归实现
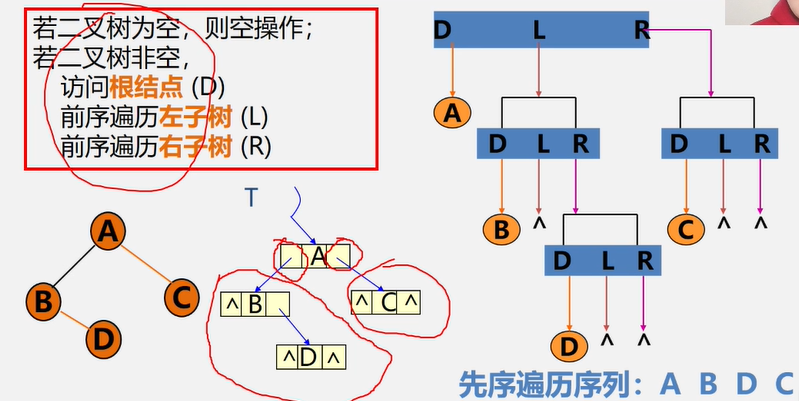
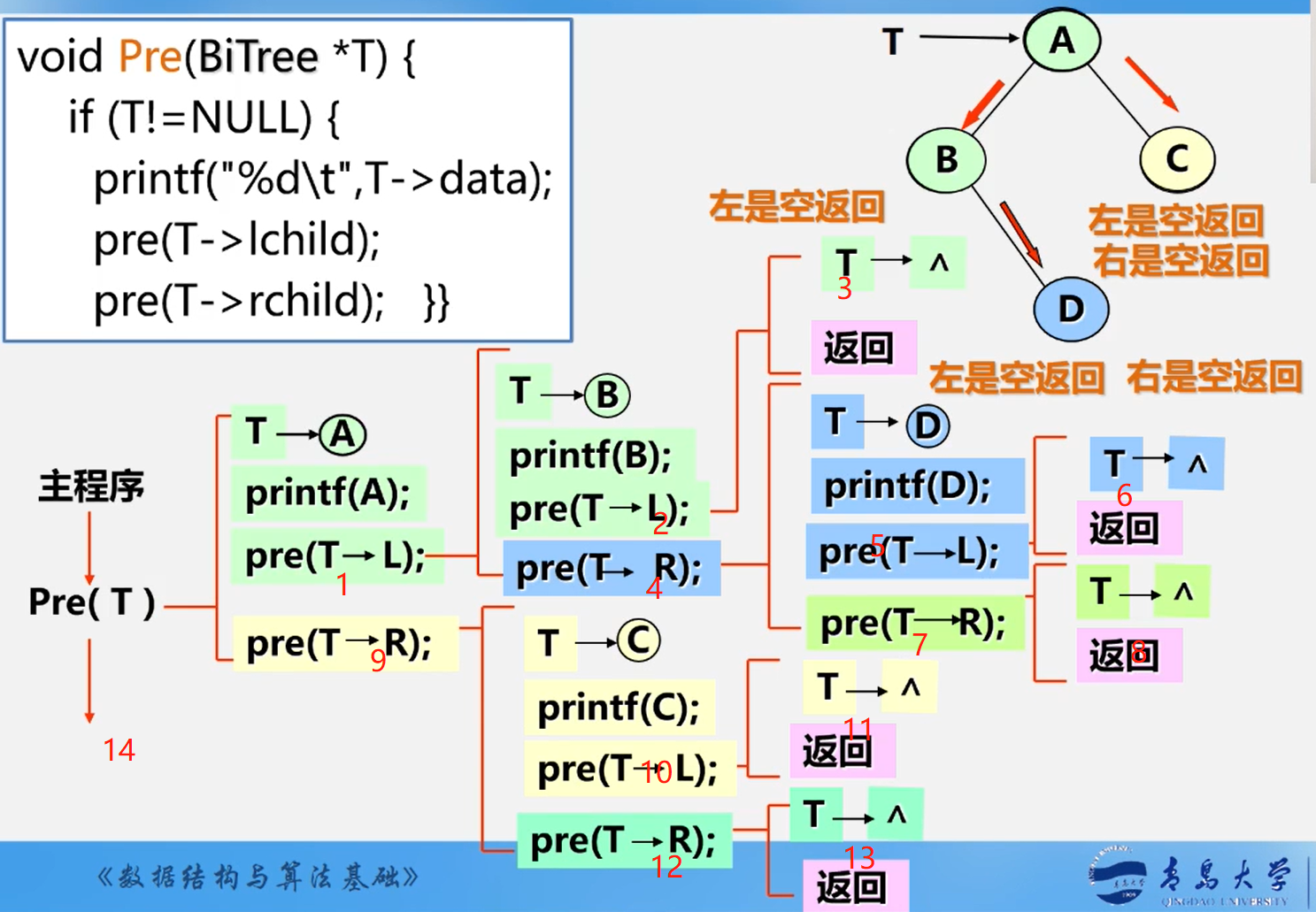


//先序遍历
public static void preOrderTraverse (BiNode node){
if (node == null) return;
System.out.println(node.data); //输出根节点数据
preOrderTraverse(node.leftChild); //遍历左子树
preOrderTraverse(node.rigthChild); //遍历右子树
}
中序遍历LDR
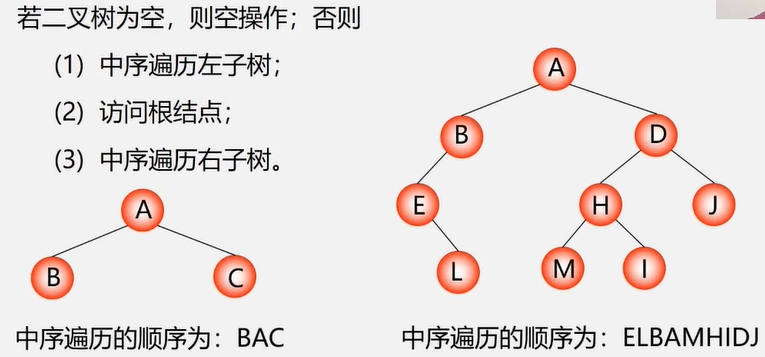
中序遍历递归实现:


//中序遍历遍历
public static void inOrderTraverse (BiNode node){
if (node == null) return;
inOrderTraverse(node.leftChild); //遍历左子树
System.out.println(node.data); //输出根节点数据
inOrderTraverse(node.rigthChild); //遍历右子树
}
中序遍历非递归实现
二叉树中序遍历的非递归算法的关键:在中序遍历过某结点的整个左子树后,如何找到该结点的根以及右子树。
基本思想
(1)建立一个栈
(2)根结点进栈,遍历左子树
(3)根结点出栈,输出根结点,遍历右子树。
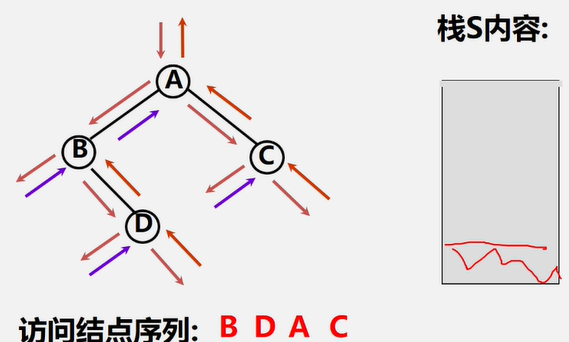

//中序遍历非递归
public static void inOrderTraverseStack(BiNode node){
BiNode tempNode = node;
Stack<BiNode> stack = new Stack<>();
//如果node不为空或者栈不为空
while (tempNode != null || !stack.empty()){
if (tempNode != null){
stack.push(tempNode);
tempNode = tempNode.leftChild;
}else {
BiNode pop = stack.pop();
System.out.println(pop.data);
tempNode = tempNode.rigthChild;
}
}
}
后序遍历LRD
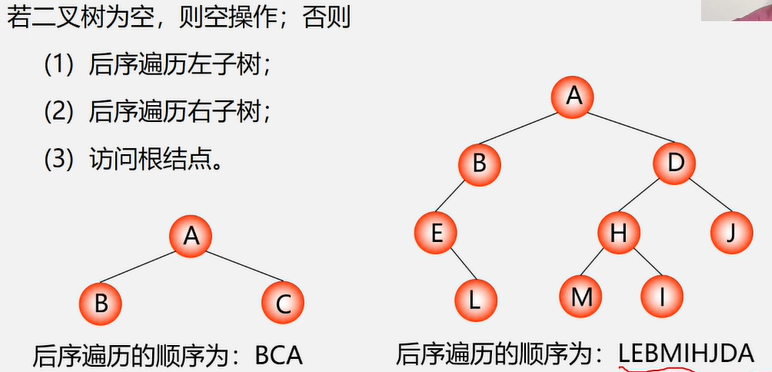
后序遍历递归实现


//后序遍历
public static void postOrderTraverse (BiNode node){
if (node == null) return;
inOrderTraverse(node.leftChild); //遍历左子树
inOrderTraverse(node.rigthChild); //遍历右子树
System.out.println(node.data); //输出根节点数据
}
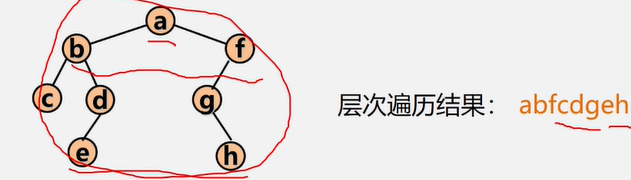
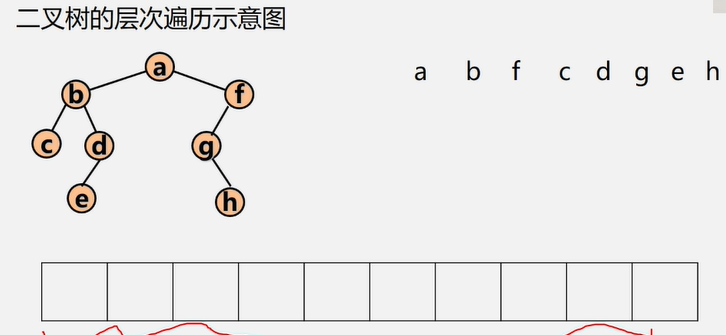
二叉树的层次遍历
对于一颗二叉树,从根结点开始,按从上到下、从左到右的顺序访问每一个结点。
每一个结点仅仅访问一次。
算法设计思路:
使用一个队列
将根结点进队;
队不空时循环:从队列中出列一个结点*p,访问它;
若它有左孩子结点,将左孩子结点进队; 若它有右孩子结点,将右孩子结点进队。


//层次遍历算法
public static void levelOrder(BiNode node){
if (node == null) return; //如果为空直接退出
BiNode currentNode;
Queue<BiNode> queue = new ArrayDeque<>(); //初始化队列
queue.add(node); //将根节点入队
while (!queue.isEmpty()){ //如果当前队列不为空
currentNode = queue.peek(); //出队
System.out.println(currentNode.data); //输出出对元素
if (currentNode.leftChild != null) queue.add(currentNode.leftChild); //有左孩子入队
if (currentNode.rigthChild != null) queue.add(currentNode.rigthChild); //有有孩子入队
queue.poll();
}
}
遍历算法的分析
如果去掉输出语句,从递归的角度看,三种算法是完全相同的,或说这三种算法的访问路径是相同的,只是访问结点的时机不同
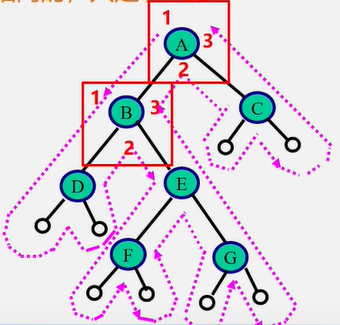
从虚线的出发点到终点的路径上,每个结点经过3次。
第1次经过时访问=先序遍历
第2次经过时访问=中序遍历
第3次经过时访问=后序遍历
时间效率:O( n ) // 每个结点只访问一次
空间效率:O( n ) //栈占用的最大辅助空间
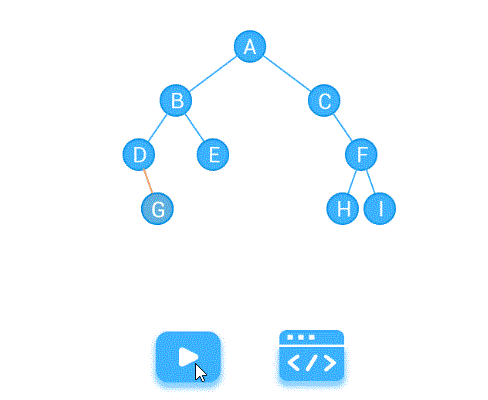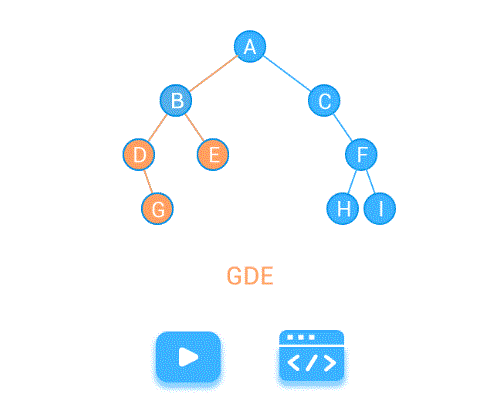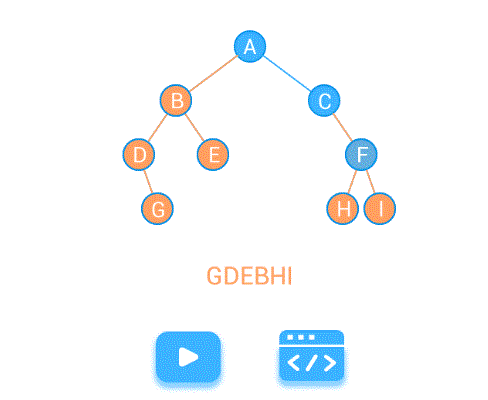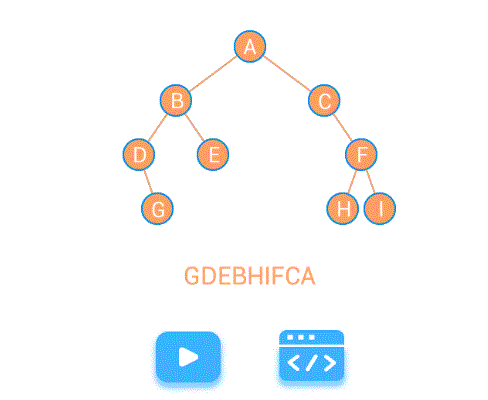
例题:二叉树的遍历顺序
1、写出下图二叉树的各种遍历顺序

先序遍历:a b d g c e h f
中序遍历:d g b a e h c f
后序遍历:g d b h e f c a
2、写出下图所示二叉树的先序、中序和后序遍历顺序。
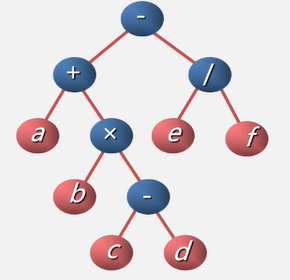
先序遍历:- + a x b - c d / e f (表达式的前缀表示(波兰式))
中序遍历: a + b x c - d - e / f (表达式的中缀表示)
后序遍历 : a b c d - x + e f / - (表达式的后缀表示(逆波兰式))
根据遍历序列确定二叉树
- 若二叉树中各结点的值均不相同,则二叉树结点的先序序列、中序遍历和后序遍历都是唯一的。
- 由二叉树的先序序列和中序序列,或由二叉树的后序序列和中序序列可以确定唯——棵二叉树
分析:由先序序列确定根;由中序序列确定左右子树。
例题:已知先序和中序序列求二叉树
步骤:
1、由先序知根为A,则由中序知左子树为 CDBFE,右子树为HGJ

2、再分别在左、右子树的序列中找出根、左子树序列、右子树序列
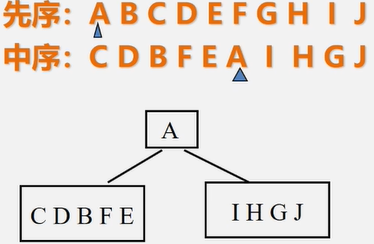
3、以此类推,直到得到二叉树
例题:已知中序和后序序列求二叉树
实例分析:
已知一棵二叉树的中序序列:BDCEAFHG
后序序列:DECBHGFA,请画出这棵二叉树
后序遍历,根结点必在后序序列尾部 , 先确定根节点再确定结点左右位置,以此递推

二叉树的建立
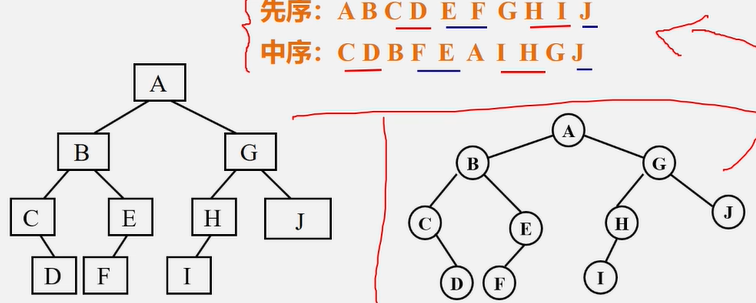
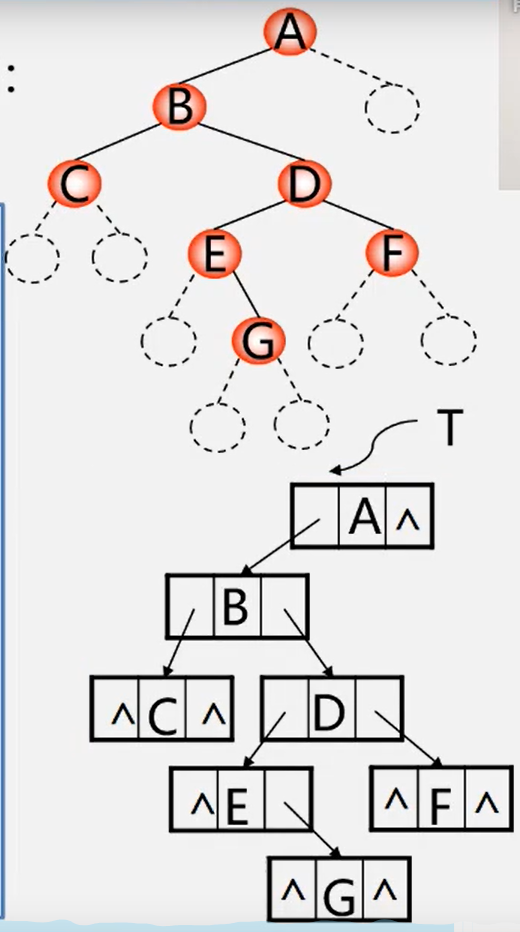
按先序遍历序列建立二叉树的二叉链表
例:已知先序序列为:ABCDEGF
(1)从键盘输入二叉树的结点信息,建立二叉树的存储结构;
(2)在建立二叉树的过程中按照二叉树先序方式建立;
只知道先序序列构建的二叉树不唯一


复制二叉树
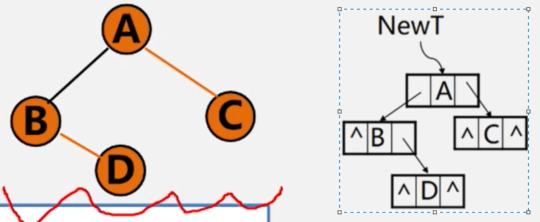
如果是空树,归结束;
否则,申请新结点空间,复制根结点递归复制左子树,递归复制右子树

//复制树
public BiNode copy(BiNode node){
if (node == null) return null;
BiNode biNode = new BiNode();
biNode.data = node.data;
biNode.leftChild = copy(node.leftChild);
biNode.rigthChild = copy(node.rigthChild);
return biNode;
}
计算二叉树的深度
如果是空树,则深度为0否则,递归计算左子树的深度记为m,递归计算右子树的深度记为m,二叉树的深度则为m与n的较大者加

//树的深度
int depth(BiNode node){
if (node == null) return 0;
int m = depth(node.leftChild);
int n = depth(node.rigthChild);
if (m > n) {
return m+1;
}else {
return n + 1;
}
}
计算二叉树的节点数
如果是空树,则结点个数为0;否则,结点个数为左子树的结点个数+右子树的结点个数再+1。

//计算树的结点数
int nodeCount(BiNode node){
if (node == null) return 0;
return nodeCount(node.leftChild) + nodeCount(node.rigthChild) + 1;
}
计算二叉树的叶子结点数
如果是空树,则叶子结点个数为0否则,为左子树的叶子结点个数+右子树的叶子结点个数。

//计算叶子结点数
int leafCount(BiNode node){
if (node == null) return 0;
if (node.leftChild == null && node.rigthChild == null) {
return 1;
}else {
return leafCount(node.leftChild) + leafCount(node.rigthChild);
}
}
树和森林

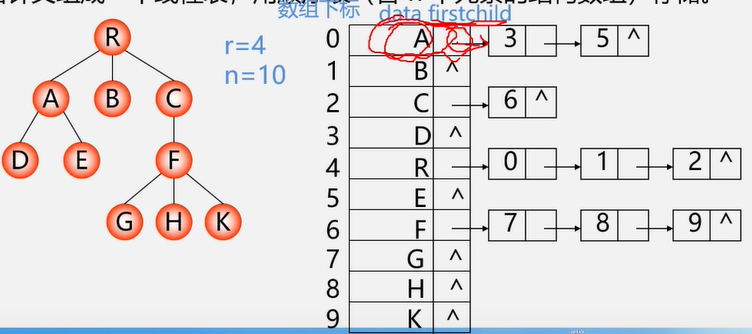
树的存储结构
双亲表示法
实现:定义结构数组存放树的结点,每个结点含两个域
数据域:存放结点本身信息。
双亲域:指示本结点的双亲结点在数组中的位置。

我们还应该另外存储 r 和 n 数据 r 是 树结构的根结点,n是结点个数
特点:找双亲容易,找孩子难。
如果我们经常找一个结点的双亲那么用这个存储结构
//c语言描述
typedef struct PTNode{
TElemType data;
int parent; //双亲位置
}PTNode;
//树结构
#define MAX_TREE_SIZE 100
typedef styuct {
PTNode nodes[MAX_TREE_SIZE];
int r; //根节点位置
int n; //结点个数
}PTree;
public class Ptree {
class PTNode{
char data;
int parent;
}
static final int MAX_TREESIZE = 100;
PTNode[] nodes;
int r;
int n;
}
孩子链表
把每个结点的孩子结点排列起来,看成是一个线性表,用单链表存储则 n 个结点有 n 个孩子链表(叶子的孩子链表为空表)。而 n 个头指针又组成一个线性表,用顺序表(含 n 个元素的结构数组)存储。
特点:找孩子容易,找双亲难

public class CTree {
//定义孩子结点结构
class CTNode{
int child; //孩子结点的下标
CTNode next; //下一个孩子结点
}
class CTBox{
char data; //存储的数据
CTNode firstChild; //第一个孩子结点
}
static final int MAX_TREESIZE = 100;
CTBox[] nodes;
int r; //根节点下标
int n; //结点数
}
带双亲的孩子链表

public class CTree {
//定义孩子结点结构
class CTNode{
int child; //孩子结点的下标
CTNode next; //下一个孩子结点
}
class CTBox{
char data; //存储的数据
CTNode firstChild; //第一个孩子结点
int parent; //双亲位置
}
static final int MAX_TREESIZE = 100;
CTBox[] nodes;
int r; //根节点下标
int n; //结点数
}
孩子兄弟表示法(二叉树表示法,二叉链表表示法)
实现:用二叉链表作树的存储结构,链表中每个结点的两个指针域分别指向其第一个孩子结点和下一个兄弟结点.

public class CSTree {
class CSNode{
char data;
CSNode fristChild; //第一个孩子结点
CSNode nextSibling; //下一个兄弟结点
}
}
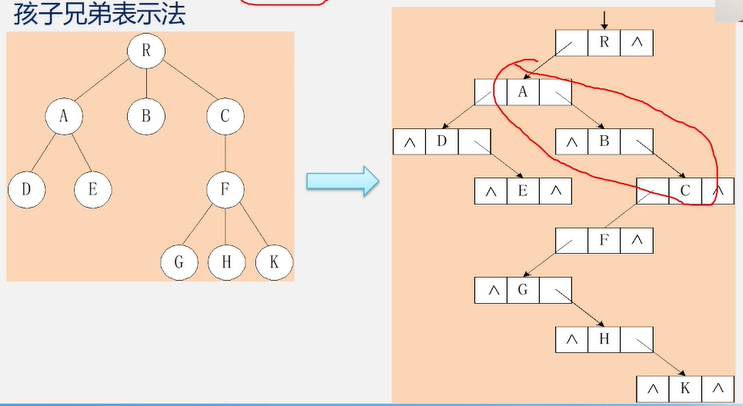
左指针第一个孩子结点;右指针下一个兄弟结点,简称左孩子右兄弟。
这种存储结构适合找孩子结点和兄弟结点,不适合找双亲结点,但是可以在节点中加入双亲结点的指针,以空间换时间。
树与二叉树的转换
将树转化为二叉树进行处理,利用二叉树的算法来实现对树的操作。
由于树和二叉树都可以用二叉链表作存储结构,则以二叉链表作媒介可以导出树与二叉树之间的一个对应关系。
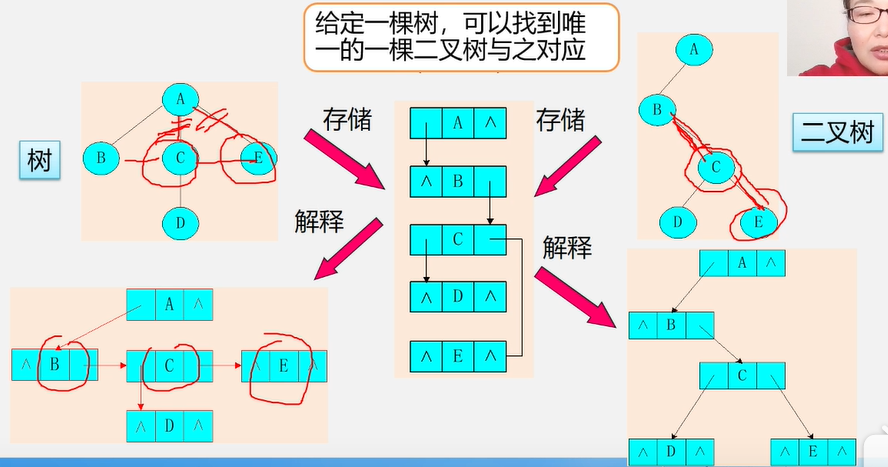
将树转换成二叉树
1、加线:在兄弟之间加一连线
2、抹线:对每个结点,除了其左孩子外,去除其与其余孩子之间的关系
3、旋转:以树的根结点为轴心,将整树顺时针转45°

例子:将树转换成二叉树

将二叉树转换成树
1、加线:若p结点是双亲结点的左孩子,则将p的右孩子,右孩子的右孩子……沿分支找到的所有右孩子,都与p的双亲用线连起来
2、抹线:抹掉原二叉树中双亲与右孩子之间的连线
3、调整:将结点按层次排列,形成树结构

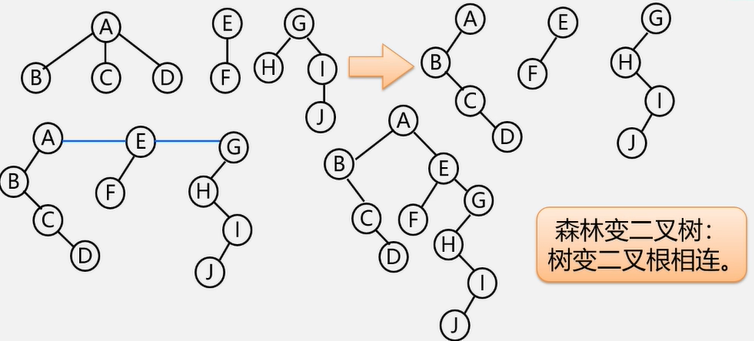
森林与二叉树的转换
森林转换成二叉树:
①将各棵树分别转换成二叉树
②将每棵树的根结点用线相连
③以第一棵树根结点为二叉树的根,再以根结点为轴心,顺时针旋转,构成二叉树型结构

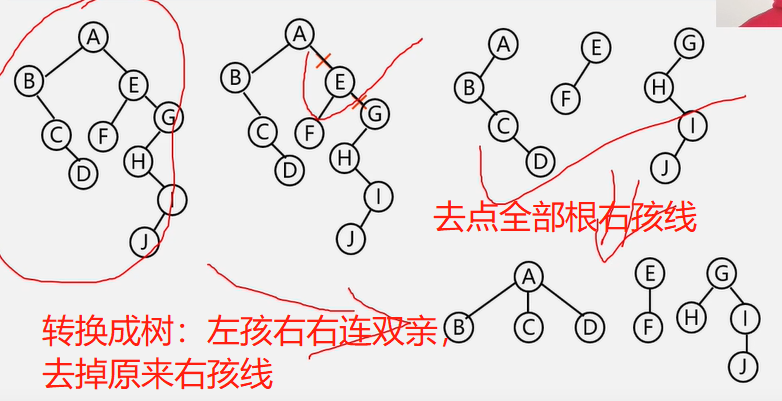
二叉树转换成森林:
①抹线:将二叉树中根结点与其右孩子连线,及沿右分支搜索到的所有右孩子间连线全部抹掉,使之变成孤立的二叉树
②还原:将孤立的二叉树还原成树

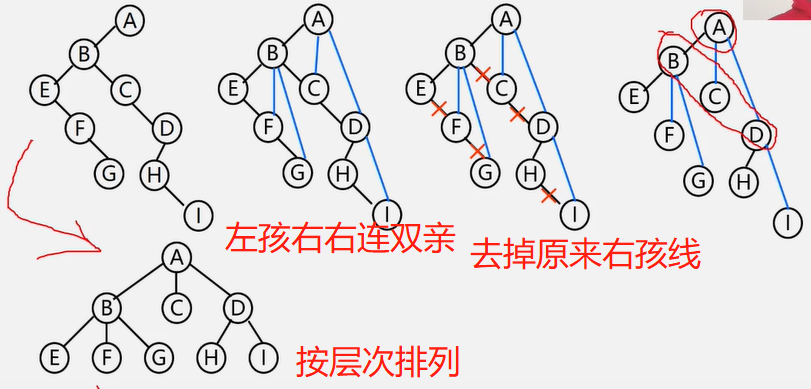
树的遍历(三种形式)
先根(次序)遍历:若树不空,则先访问根结点,然后依次先根遍历各棵子树。
后根(次序)遍历:若树不空,则先依次后根遍历各棵子树,然后访问根结点。
按层次遍历:若树不空,则自上而下自左至右访问树中每个结点。
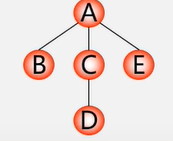 先根遍历:A B C D E。后根遍历:B D C E A 层次遍历: A B C E D
先根遍历:A B C D E。后根遍历:B D C E A 层次遍历: A B C E D
森林的遍历
将森林看作由三部分构成
1、森林中第—棵树的根结点
2、森林中第一棵树的子树森林
3、森林中其它树构成的森林。
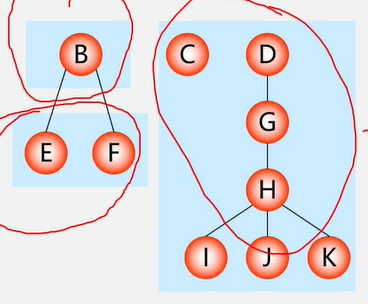
先序遍历:
若森林不空,则
1、访问森林中第一棵树的结点;
2、先序遍历森林中第一棵树的子树森林;
3、先序遍历森林中(除第一棵树之外)其余树构成的森林。
即:依次从左至右对森林中的每一棵树进行先根遍历。
中序遍历:
若森林不空,
1、中序遍历森林中第一棵树的子树森林;
2、访问森林中策一棵树的根结点;
3、中序遍历森林中(除第一棵树之外)其余树构成的森林。
即:依次从左至右对森林中的每棵树进行后根遍历。
例子:
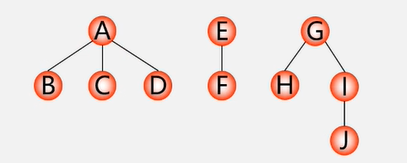
先序遍历:A B C D E F G H I J
中序遍历:B C D A F E H J I G
哈夫曼树及其应用

基本概念
【例】编程:将学生的百分制成绩转换为五分制成绩
<60:E | 60-69:D | 70-79:C | 80-89:B | 90-100:A
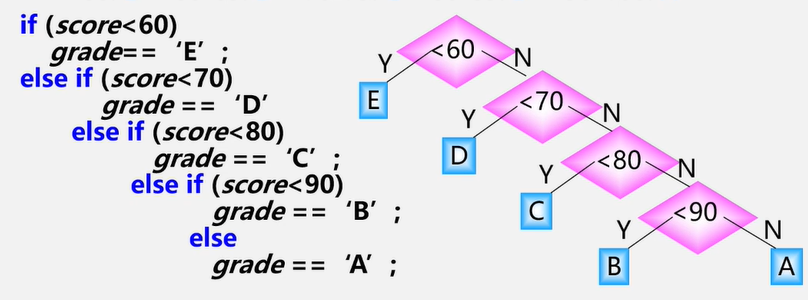
判断树:用于描述分类过程的二叉树
如果每次的输入量很大,则应考虑程序的操作时间。
若学生的成绩数据共10000个:
则5%的数据需1次比较,15%的数据需2次比较,40%的数据需3次比较,40%的数据需4次比较,因此10000个数据比较的次数为:10000(1×5%+2×15%+3×40%+4×10%)=31500次
能否进一步优化?
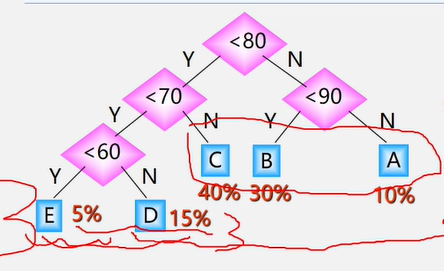
10000(3×20%+2×80%)=22000次
显然:两种判别树的效率是不一样的。
问题:能不能找到种效率最高的判别树呢?
这就是哈夫曼树:哈夫曼树(最优二叉树)
相关术语
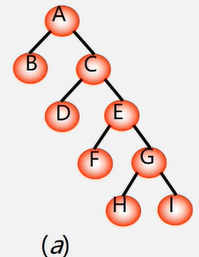
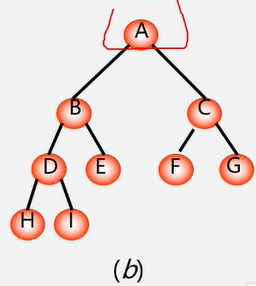
路径:从树中一个结点到另一个结点之间的分支构成这两个结点间的路径。
图中从a结点到d结点间经过a的右分支和c的左分支,所以经过两个路径。
结点的路径长度:两结点间路径上的分支数。
( a )从A到B,C,D,E,F,G ,H,T的路径长度分别为1,1,2,2,3,3,4,4。
(b)从A到B,C,DE,FG H,I的路径长度分别为1,1,2,2,2,2,3,3。
树的路径长度:从树根到每一个结点的路径长度之和。记作:TL
TL(a) = 0+1+1+2+2+3+3+4+4=20
TL(b)=0+1+1+2+2+2+2+3+3=16
结点数目相同的二叉树中,完全二叉树是路径长度最短的二叉树。
权 (weight):将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积。
树的带权路径长度:树中所有叶子结点的带权路径长度之和
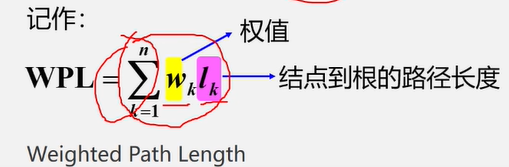
例:有4个结点a,b,c,d,权值分别为7,5,2,4,构造以此4个结点为叶子结点的二叉树
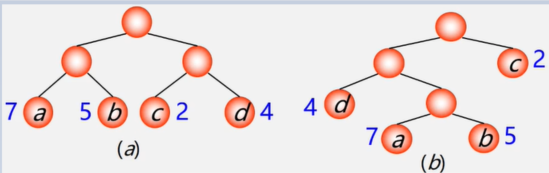
带权路径长度是:
(a)WPL=7×2+5×2+2×2+4x2=36
(b)WPL=7×3+5×3+2×1+4×2=46
结论在叶子结点相同,权值相同的两颗不同树的带权路径长度不同
哈夫曼树:最优树——带权路径长度(WPL)最短的树
注:‘带权路径长度最短”是在“度相同″的树中比较而得的结果,因此有最优二叉树、最优三叉树之称等等。
哈夫曼树:最优二叉树——带权路径长度(WPL)最短的二叉树
因为构造这种树的算法是由哈夫曼教授于1952年提出的,所以被称为哈夫曼树,相应的算法称为哈夫曼算法。
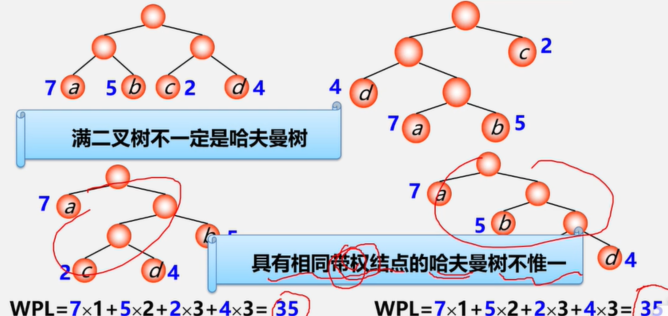
结论:满二叉树不一定是哈夫曼树,具有相同带权结点的哈夫曼树不唯一。
哈夫曼树的构造算法

哈夫曼树中权越大的叶子离根越近————》贪心算法:构造哈夫曼树时首先选择权值小的叶子结点。
哈夫曼算法(构造哈夫曼树的方法)
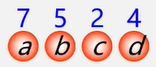
(1)根据η个给定的权值{W1,W2,…,Wn}构成 n 棵二叉树的森林F={T1 , T2,…Tn,其中T只有一个带权为Wi的根结点。
构造森林全是根
(2)在F中选取两棵根结点的权值最小的树作为左右子树,构造一棵新的二叉树,且设置新的二叉树的根结点的权值为其左右子树上根结点的权值之和。
选用两小造新树

(3)在F中删除这两棵树,同时将新得到的二叉树加入森林中
删除两小添新人

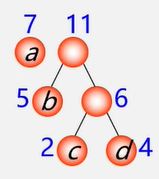
(4)重复(2)和(3),直到森林中只有一棵树为止,这棵树即为哈夫曼树。
重复2、3剩单根
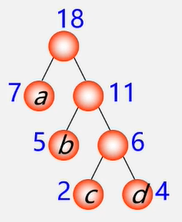
哈夫曼算法口诀:
1、构造森林全是根;
2、选用两小造新树;
3、删除两小添新人;
4、重复2、3剩单根。
例:有4个结点a、b、c、d,权值分别为7,5,2,4,构造哈夫曼树。
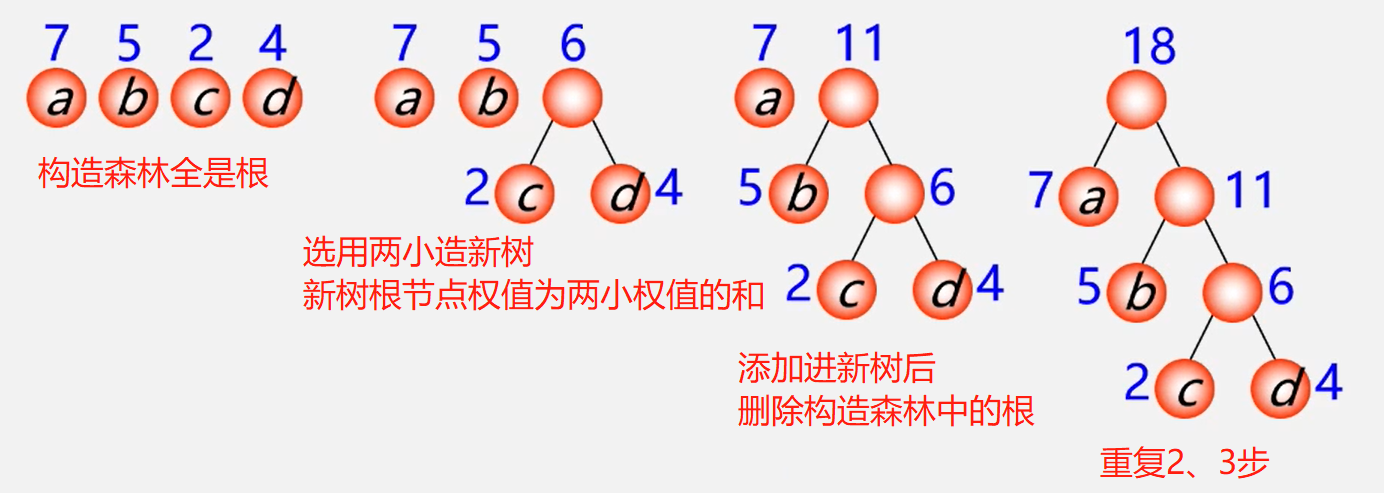
哈夫曼树的特点:
哈夫曼树的结点度数为0或2,没有度为1的结点。
包含 n 棵树的森林要经过 n-1 次合并才能形成哈夫曼树。共产生n-1个新结点
包含 n 个叶子结点的哈夫曼树中共有2n-1个结点。
例:有5个结点a,bc,d,e,权值分别为7,5,5,2,4,构造哈夫曼树。
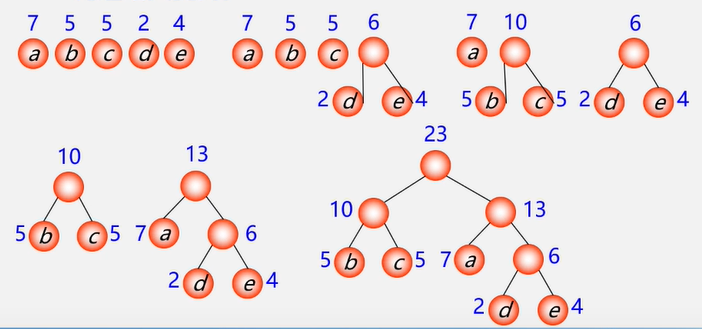
总结:
- 在哈夫曼算法中,初始时有 n 棵二叉树,要经过n-1次合并最终形成哈夫曼树。
- 经过 n-1 次合并产生 n-1 个新结点,且这 n-1 个新结点都是具有两个孩子的分支结点。
- 可见:哈夫曼树中共有n+n-1 = 2n-1个结点,且其所有的分支结点的度均不为1。要么为2 要么为0
哈夫曼树构造算法的实现
采用顺序存储结构——一维结构数组

public class HuffmanTree {
class HTNode{
int weight; //权重
int parent; //双亲结点下标
int lch; //左孩子下标
int rch; //右孩子下标
}
HTNode[] nodes;
HuffmanTree(int size){
nodes = new HTNode[2*size-1];
}
}
例:有n = 8 ,权值为W = {7 , 19 , 2 , 6 , 32 , 3 , 21 , 10} ,构造哈夫曼树
1、构造森林全是根 2、选择两小造新树(插入新生成的结点,设置两小的双亲下标,设置新结点的左右孩子下标)
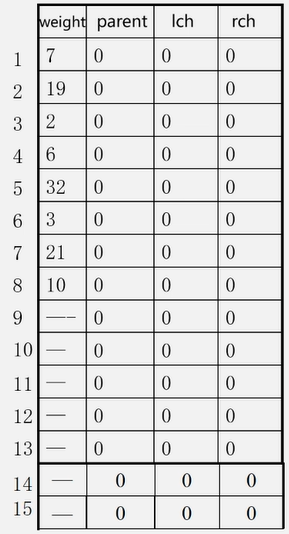
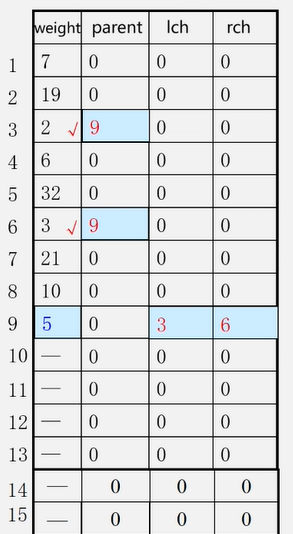
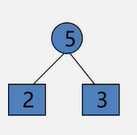
3、添新人
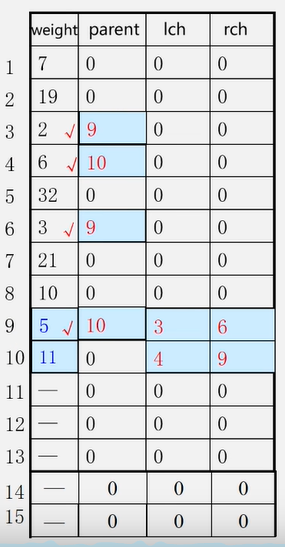
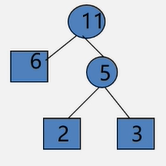
4、重复2 3

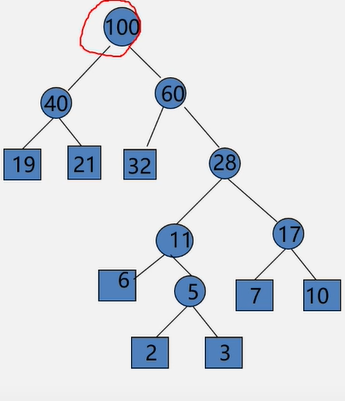
1、初始化HT[ 1…2n-1] :Ich=rch= parent=0; (左右孩子及双亲结点值0)
2、输入初始n 个叶子结点:置HT[1……n]的 weight值
3、进行以下n-1次合并,依次产生n-1个结点HT[i] ,i=n+1...2n-1
a)在HT[1...i-1] 选两个未被选过(从 parent==0的结点中选) 的weight最小的两个结点HT[s1]和HT[s2] , s1、s2为两个最小结点下标;
b) 修改HT[s1] 和 HT[s2] , 的parent值 , HT[s1].parent = i ; HT[s2].parent = i;
c)修改新产生的HT[i]
HT[i].weight = HT[s1].weight + HT[s2].weight;
HT[i].lch = s1; HT[i].ch;


public class HuffmanTree {
class HTNode{
int weight; //权重
int parent; //双亲结点下标
int lch; //左孩子下标
int rch; //右孩子下标
}
HTNode[] nodes;
// 创建哈夫曼树算法
void createHuffmanTree(int[] n){
int m = 2*n.length; //2 * 8 = 16
nodes = new HTNode[m];// index 0 - 15 共16个元素 0位置元素不用 1-15 15个元素
for (int i = 1; i < m; i++) { //将2n-1个元素的双亲结点左孩子右孩子设置为0
HTNode node = new HTNode();
node.lch = 0;
node.rch = 0;
node.parent = 0;
nodes[i] = node;
}
//输入前n个元素的weight 值
for (int i = 1; i < n.length+1; i++) {
nodes[i].weight = n[i-1];
}
//System.out.println(this.toString());
//select(nodes , 8);
for (int i = n.length+1; i <m ; i++) {
int[] select = select(nodes, i-1); //获得最小的两个元素
HTNode node = new HTNode(); //创建新结点
nodes[select[0]].parent = i; //设置左右孩子的双亲下标
nodes[select[1]].parent = i;
node.lch = select[0]; //设置新结点的左右孩子下标
node.rch = select[1];
node.weight = nodes[select[0]].weight + nodes[select[1]].weight; //新结点的权重等于左右孩子权重的和
nodes[i] = node;
//System.out.println(i-1);
}
}
//找到数组中权重最小的两个数的下标 [0] 是第一小的 [1] 是第二小的
int[] select (HTNode[] arr , int index){
int m1 ,m2 ;//存储两个最小值的下标
LinkedList<Integer> arrParents = new LinkedList<>();
//获得parent值为0的下标集合
int maxIndex = 1;
for (int i = 1; i <= index; i++) {
if (arr[i].parent == 0) arrParents.add(i);
if (arr[i].weight > arr[maxIndex].weight) maxIndex = i;
}
//找到weight最小的两个元素下标
m1=maxIndex;
m2=maxIndex;
for(int i=0;i<arrParents.size();i++){
if(arr[arrParents.get(i)].weight < arr[m1].weight){
m2=m1;
m1=arrParents.get(i);
}else if(arr[arrParents.get(i)].weight < arr[m2].weight){
m2=arrParents.get(i);
}
}
int[] ints = new int[2];
ints[0] = m1;
ints[1] = m2;
System.out.println(m1 +"::" + m2);
return ints;
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
for (int i = 1; i < nodes.length; i++) {
sb.append("index:"+i+" weight:"+nodes[i].weight
+" parent:"+nodes[i].parent
+" lch:"+nodes[i].lch
+" rch:"+nodes[i].rch+"\r\n");
}
return sb.toString();
}
public static void main(String[] args) {
int[] data = new int[8];
data[0] = 7;
data[1] = 19;
data[2] = 2;
data[3] = 6;
data[4] = 32;
data[5] = 3;
data[6] = 21;
data[7] = 10;
HuffmanTree huffmanTree = new HuffmanTree();
huffmanTree.createHuffmanTree(data);
System.out.println(huffmanTree.toString());
}
}
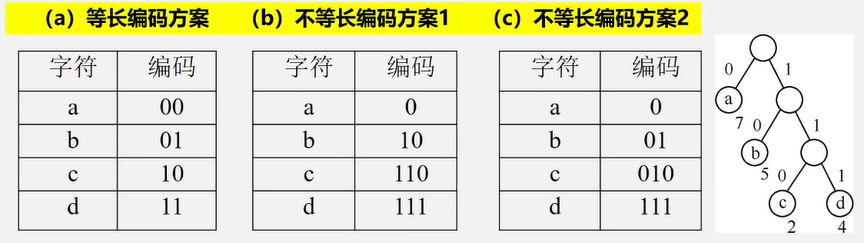
哈夫曼编码
例子:远程通讯
在远程通讯中,要将待传字符转换成由二进制的字符串
设要传送的字符为ABACCDA
若编码为:
A——00
B——01
C——10
D——11
则ABACCDA编码为00010010101100
若将编码设计为长度不等的二进制编码,即让待传字符串中出现次数较多的字符采用尽可能的编码,则转换的二进制字符串便可能减少
设要传送的字符为ABACCDA
A——0
B——00
C——1
D——01
则ABACCDA编码为000011010 , 但是0000的解码产生的字符有多种组合方式

所以要设计长度不能的编码方式时,一定不能有重码,设计的码一定不是其他码的前缀
关键:要设计长度不等的编码,则必须使任一字符的编码都不是另个字符的编码的前缀——这种编码也被称为前缀编码
哈夫曼编码
什么样的前缀码能使得电文总长最短? ——哈夫曼编码
构造方法:
1、统计字符集中每个字符在电文中岀现的平均概率(概率越大,要求编码越短)
2、利用哈夫曼树的特点:权越大的叶子离根越近;将每个字符的概率值作为权值,构造哈夫曼树。则概率越大的结点,路径越短。
3、在哈夫曼树的每个分支上标上0或1:
结点的左分支标0,右分支标1
把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码。
【例】要传输的字符集D={C,A,S,T,;}
字符出现频率W={2,4,2,3,3},
1、 使用出现频率作为权值构建哈夫曼树 2、左分支标记0,右分支标记1
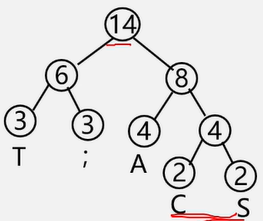
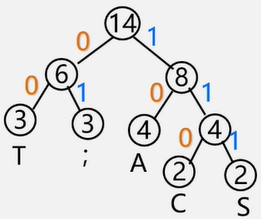
3、把从根到每个叶子的路径上的标号连接起来,作为该叶子代表的字符的编码。这个编码就叫做哈夫曼编码
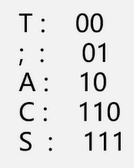
例:电文是{CAS;CAT; SAT;AT} 那么编码为11010111011101000011111000011000
反之若编码是 1101000 那么电文是C A T , 发现编码里的所有码都没有歧义
两个问题:
1.为什么哈夫曼编码能够保证是前缀编码?
因为没有一片树叶是另一片树叶的祖先,所以每个叶结点的编码就不可能是其它叶结点编码的前缀
2.为什么哈夫曼编码能够保证字符编码总长最短?
因为哈夫曼树的带权路径长度最短,故字符编码的总长最短。
两个性质:
1、哈夫曼编码是前缀码
2、哈夫曼编码是最优前缀码
例子:设计哈夫曼编码
设组成电文的字符集D及其概率分布W为:
D={ A, B, C, D,E, F, G}
W={0.40 0.30 0.15 0.05 0.04 0.03 0.03 }
设计哈夫曼编码。
1、构造哈夫曼树
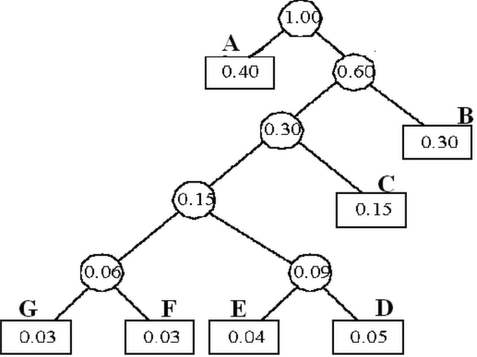
2、左分支标0,右分支标1 3、从根到叶子结点路径为编码


哈夫曼编码的算法实现
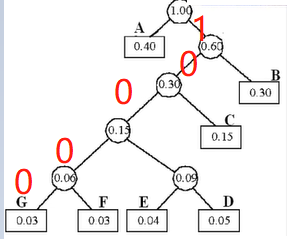
使用算法实现时从根节点找叶子结点困难,推荐使用从叶子结点到根节点的方式

此表特点,叶子结点无左右孩子,根节点无双亲
算法思路:
例G结点的编码值,
根据G 的parent下标找到双亲结点,根据双亲结点的左右孩子下标判断结点在左孩子还是有孩子,左孩子标注0,右孩子标注1。我们从叶子结点到根节点得到的序列是 00001 由于哈夫曼编码是从根节点到叶子结点,所有序列要反转为10000,重复此步骤得到其余结点的编码
HC[i] 放置叶子节点的哈夫曼编码
cd[start] 放置遍历时的结点哈夫曼编码,其数组大小为 n ,其中第n位不用 , 使用其0 - n-1位
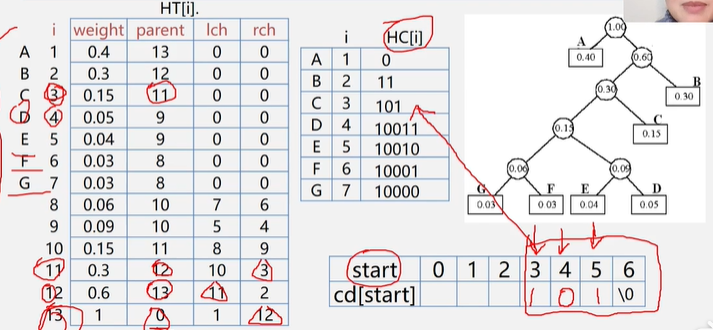

public class HuffmanTree {
class HTNode{
//int weight; //权重
double weight;
char data;
int parent; //双亲结点下标
int lch; //左孩子下标
int rch; //右孩子下标
}
HTNode[] nodes;
// 创建哈夫曼树算法
//void createHuffmanTree(int[] n){
void createHuffmanTree(double[] n){
int m = 2*n.length; //2 * 8 = 16
nodes = new HTNode[m];// index 0 - 15 共16个元素 0位置元素不用 1-15 15个元素
for (int i = 1; i < m; i++) { //将2n-1个元素的双亲结点左孩子右孩子设置为0
HTNode node = new HTNode();
node.lch = 0;
node.rch = 0;
node.parent = 0;
nodes[i] = node;
}
//输入前n个元素的weight 值
for (int i = 1; i < n.length+1; i++) {
nodes[i].weight = n[i-1];
}
for (int i = n.length+1; i <m ; i++) {
int[] select = select(nodes, i-1); //获得最小的两个元素
HTNode node = new HTNode(); //创建新结点
nodes[select[0]].parent = i; //设置左右孩子的双亲下标
nodes[select[1]].parent = i;
node.lch = select[0]; //设置新结点的左右孩子下标
node.rch = select[1];
node.weight = nodes[select[0]].weight + nodes[select[1]].weight; //新结点的权重等于左右孩子权重的和
nodes[i] = node;
//System.out.println(i-1);
}
}
//找到数组中权重最小的两个数的下标 [0] 是第一小的 [1] 是第二小的
int[] select (HTNode[] arr , int index){
int m1 ,m2 ;//存储两个最小值的下标
LinkedList<Integer> arrParents = new LinkedList<>();
//获得parent值为0的下标集合
int maxIndex = 1;
for (int i = 1; i <= index; i++) {
if (arr[i].parent == 0) arrParents.add(i);
if (arr[i].weight > arr[maxIndex].weight) maxIndex = i;
}
//找到weight最小的两个元素下标
m1=maxIndex;
m2=maxIndex;
for(int i=0;i<arrParents.size();i++){
if(arr[arrParents.get(i)].weight < arr[m1].weight){
m2=m1;
m1=arrParents.get(i);
}else if(arr[arrParents.get(i)].weight < arr[m2].weight){
m2=arrParents.get(i);
}
}
int[] ints = new int[2];
ints[0] = m1;
ints[1] = m2;
//System.out.println(m1 +"::" + m2);
return ints;
}
//保存成员下标及code
class HC{
int index;
char[] code;
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
sb.append("index:"+index+"--code:"+Arrays.toString(code));
return sb.toString();
}
}
//创建哈夫曼编码
void cleatHuffmanCode(int n ){
//0号位置不用 使用1-7
HC[] hc = new HC[n+1];
//保存临时code
char[] tempCode = new char[n];
tempCode[n-1] = '-'; //临时code最后一位设置为-号
//逐个字符求编码
for (int i = 1; i <= n; i++) { //逐个字符求哈夫曼编码
HTNode tempNode = nodes[i]; //获得当前结点
int index = n-2; //临时code下标
int j = i;
while (tempNode.parent != 0){ //从叶子结点向上回溯,直到根节点
if (nodes[tempNode.parent].lch == j){ //判断结点在其双亲结点的左侧还是右侧
tempCode[index] = '0'; //左孩子生成0
}else {
tempCode[index] = '1'; //右孩子生成1
}
j = tempNode.parent; index--; //继续向上回溯
tempNode = nodes[tempNode.parent]; //获取当前结点的双亲结点
}
//将得到的临时编码复制到hc中
HC hc1 = new HC();
hc1.code = splitTempCode(tempCode);
hc1.index = i;
hc[i] = hc1;
}
//System.out.println(Arrays.toString(hc));
}
//拷贝
char[] splitTempCode(char[] data){
// System.out.println(Arrays.toString(data));
// System.out.println(index);
// System.out.println(data.length);
//判断data 有值元素个数
int index = 0;
for (int i = 0 ; i <= data.length-2 ;i++){
if (data[i] != '\u0000'){
index = i;
break;
}
}
char[] chars = new char[data.length - 1 - index];
for (int i = 0; i < chars.length; i++) {
chars[i] = data[index];
index++;
}
return chars;
}
@Override
public String toString() {
StringBuffer sb = new StringBuffer();
for (int i = 1; i < nodes.length; i++) {
sb.append("index:"+i+" weight:"+nodes[i].weight
+" parent:"+nodes[i].parent
+" lch:"+nodes[i].lch
+" rch:"+nodes[i].rch+"\r\n");
}
return sb.toString();
}
public static void main(String[] args) {
/*int[] data = new int[8];
data[0] = 7;
data[1] = 19;
data[2] = 2;
data[3] = 6;
data[4] = 32;
data[5] = 3;
data[6] = 21;
data[7] = 10;
HuffmanTree huffmanTree = new HuffmanTree();
huffmanTree.createHuffmanTree(data);
System.out.println(huffmanTree.toString());*/
double[] data = new double[7];
data[0] = 0.4;
data[1] = 0.3;
data[2] = 0.15;
data[3] = 0.05;
data[4] = 0.04;
data[5] = 0.03;
data[6] = 0.03;
//System.out.println(data.length);
HuffmanTree huffmanTree = new HuffmanTree();
huffmanTree.createHuffmanTree(data); //构建哈夫曼树
//System.out.println(huffmanTree.toString());
huffmanTree.cleatHuffmanCode(data.length); //创建哈夫曼编码
}
文件的编码与解码
明文:
A computer program is a sequence of instructions written to perform a specified task with a computer. The program has an executable form that the computer can use directly to execute the instructions. Computer source code is often written by computer programmers. Source code may be converted into an executable file by a compiler and later executed by a central processing unit
378个字符,存储ASC码,每个字符8位,378*8bit=3024bit

1.编码
①输入各字符及其权值
②构造哈夫曼树—HT[i]
③进行哈夫曼编码——HC[i]
④查HC[i],得到各字符的哈夫曼编码
2.解码
①构造哈夫曼树
②依次读入二进制码
③读入0,则走向左孩子;读入1,则走向右孩子
④一旦到达某叶子时,即可译出字符
⑤然后再从根出发继续译码,指导结束
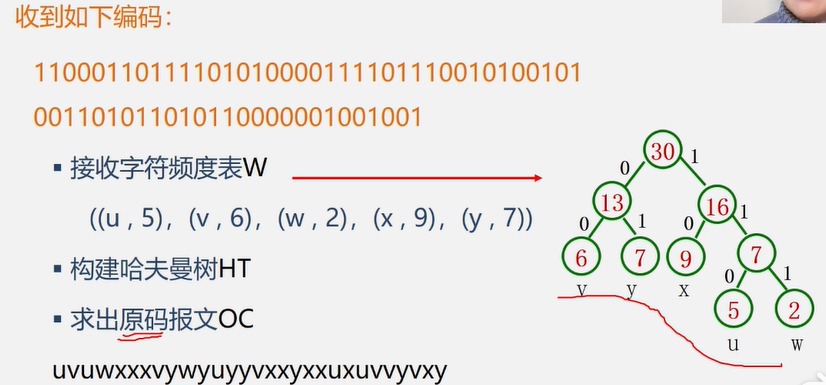
案例分析与实现
图
6.1图的定义和基本术语

vertex 顶点
edge 边
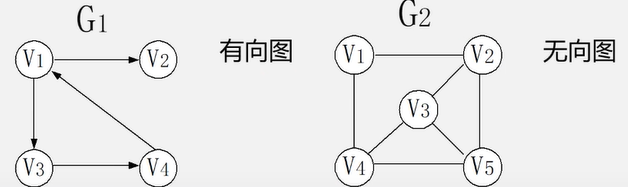
无向图:每条边都是无方向的
有向图:每条边都是有方向的
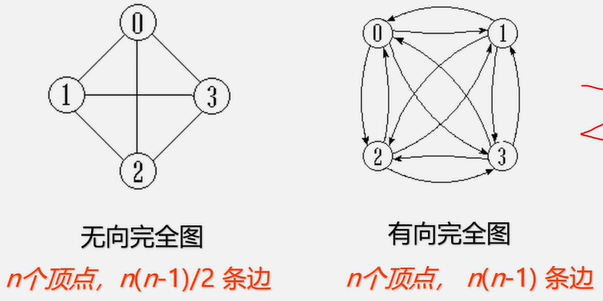
完全图:任意两个点都有一条边相连
稀疏图:有很少边或弧的图(e< n log n)
稠密图:有较多边或弧的图。
网 :边/弧带权的图
邻接:有边/弧相连的两个顶点之间的关系。
存在(Vi , Vj ),则称 Vi 和 Vj 互为邻接点;
存在< Vi , Vj >,则称Vi邻接到 VJ ,Vj 邻接于 Vi
关联(依附):边/弧与顶点之间的关系。存在(Vi , Vj)/ <Vi , Vj>,则称该边/弧关联于Vi和Vj
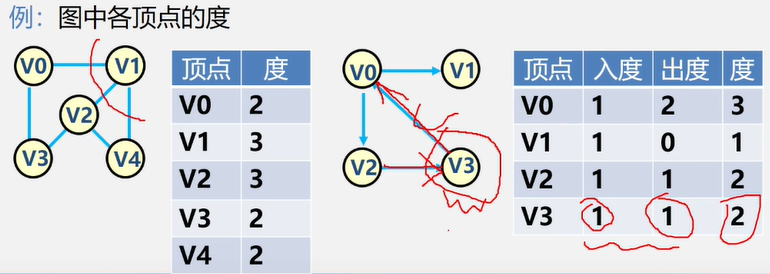
顶点的度:与该顶点相关联的边的数目,记为TD(v)
在有向图中,顶点的度等于该顶点的入度与出度之和。
顶点v的入度是以ⅴ为终点的有向边的条数记作ID(v)
顶点v的出度是以为始点的有向边的条数,记作OD(v)
问:当有向图中仅1个顶点的入度为0其余顶点的入度均为1,此时是何形状?
、
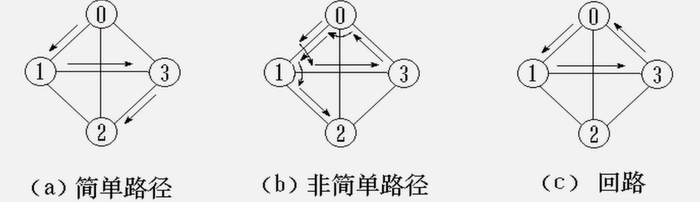
路径:接续的边构成的顶点序列。
路径长度:路径上边或弧的数目 / 权值 之和。
回路(环):第一个顶点和最后一个顶点相同的路径。
简单路径:除路径起点和终点可以相同外,其余路径顶点均不相冋的路径。
简单回路(简单环):除路径起点和终点相冋外,其余顶点均不相同的路径。
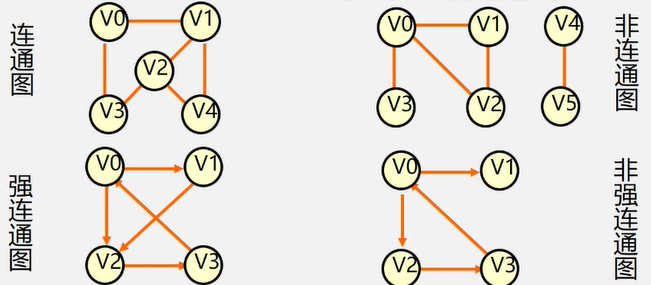
连通图(强连通图):
在无(有)向图G=(V , {E})中,若对任何两个顶点v、u都存在从ν到u的路径,则称G是连通图(强连通图)。
权与网:图中边或弧所具有的相关数称为权。表明从一个顶点到另一个页点的距离或耗费。
带权的图称为网。
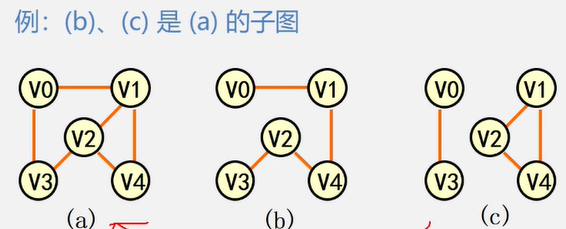
子图:设有两个图G=(V,{E})、G1=(V1 , {E1}),若V1 ⊆ V , E1 ⊆ E则称G1是G的子图。
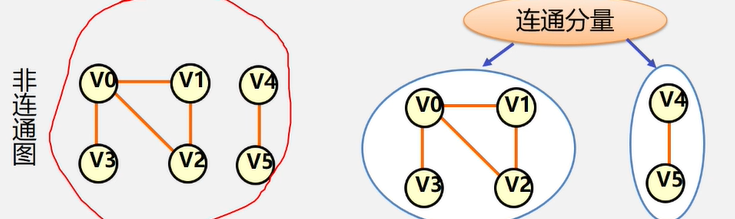
连通分量(强连通分量)
- 无向图G的`极大连通子图称为G的连通分量。
极大连通子图意思是:该子图是G连通子图,将G的任何不在该子图中的顶点加入子图不再连通
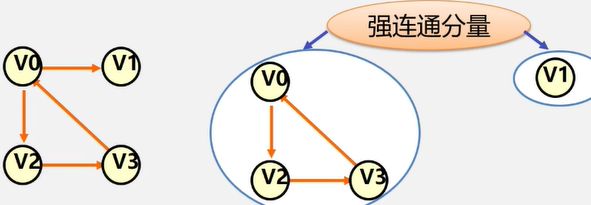
极小连通子图:该子图是G的连通子图,在该子图中删除任何一条边子图不再连通
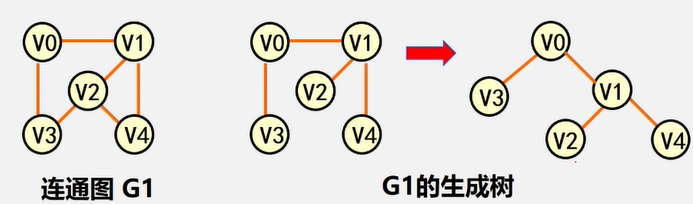
生成树:包含无向图G所有顶点的极小连通子图。
生成森林:对非连通图,由各个连通分量的生成树的集合。
6.2案例引入
案例6.1:六度空间理论


6.3图的类型定义



6.4图的存储结构

图没有顺序存储结构,但可以借助二维数组来表示元素间的关系,这种表示法叫做数组表示法(邻接矩阵)
链式存储结构:多重链表
- 邻接表
- 邻接多重表
- 十字链表
重点介绍:邻接矩阵(数组)表示法,邻接表(链式)表示法
邻接矩阵(数组)表示法
建立一个顶点表(记录各个顶点信息)和一个邻接矩阵(表示各个顶点之间关系)

图的邻接矩阵大小为 n * n

无向图的邻接矩阵表示法
有边记作1 , 无边记作0,自己和自己不邻接

分析1:无向图的邻接矩阵是对称的;对角线元素为0
问题:如果我们知道邻接矩阵,如何计算一个顶点的度?
分析2:顶点 i 的度 = 第 i 行(列) 中1的个数;
特别:完全图的邻接矩阵中,对角元素为0,其余1
有向图的邻接矩阵表示法
由自身发出到其他顶点的弧记作1 , 没有记作0 , 有多少条弧 矩阵中就有多少个1
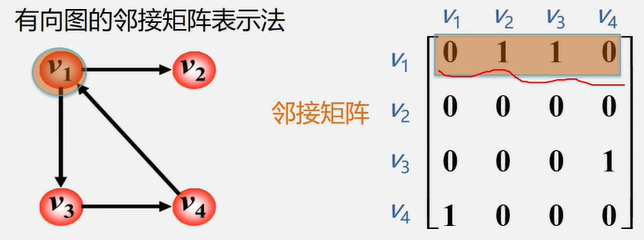
注:在有向图的邻接矩阵中
第 i 行含义:以结点 Vi 为尾的弧(即出度边)
第 i 列含义:以结点 Vi 为头的弧(即入度边)。
分析1:有向图的邻接矩阵可能是不对称的。
分析2:顶点的出度=第 i 行元素之和。顶点的入度=第i列元素之和。顶点的度 = 第 i 行元素之和 + 第列元素之和
网(即有权图)的邻接矩阵表示法

有弧记录弧的权值 , 无弧记作 ∞

邻接矩阵的建立
邻接矩阵的存储表示:用两个数组分别存储顶点表和邻接矩阵

public class AMGraph {
//表示极大值
static final int MAXINT = Integer.MAX_VALUE;
//最大顶点数
static final int MVNum = 100;
char[] vexs; //顶点表
int[][] arcs; //邻接矩阵
int vexmun; //图的当前定点数
int arcnnum; //图的当前边数
AMGraph(){
vexs = new char[MVNum];
arcs = new int[MVNum][MVNum];
vexmun = 0;
arcnnum = 0;
}
}
采用邻接矩阵表示法创建无向网

【算法思想】
(1)输入总顶点数和总边数。
(2)依次输入点的信息存入顶点表中。
(3)初始化邻接矩阵,使每个权值初始化为极大值。
(4)构造邻接矩阵。



//TODO
邻接矩阵的优缺点


邻接矩阵的优点:
- 直观、简单、好理解
- 方便检查任意一对顶点间是否存在边
- 方便找任一顶点的所有“邻接点”(有边直接相连的顶点)
- 方便计算任一顶点的“度”(从该点发出的边数为“出度”,指向该点的边数为“入度“)
- 无向图:对应行(或列)非0元素的个数
- 有向图:对应行非0元素的个数是“出度”;对应列非0元素的个数是“入度”
邻接矩阵的缺点:
- 不便于增加和删除顶点
- 浪费空间——存稀疏图(点很多而边很少)有大量无效元素
- 对稠密图(特别是完全图)还是很合算的
- 浪费时间——统计稀硫图中共有多少条边
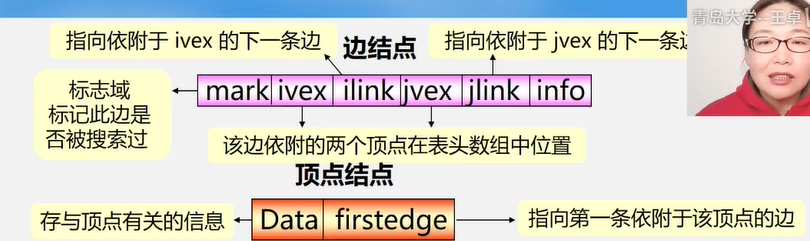
邻接表表示法(链式)
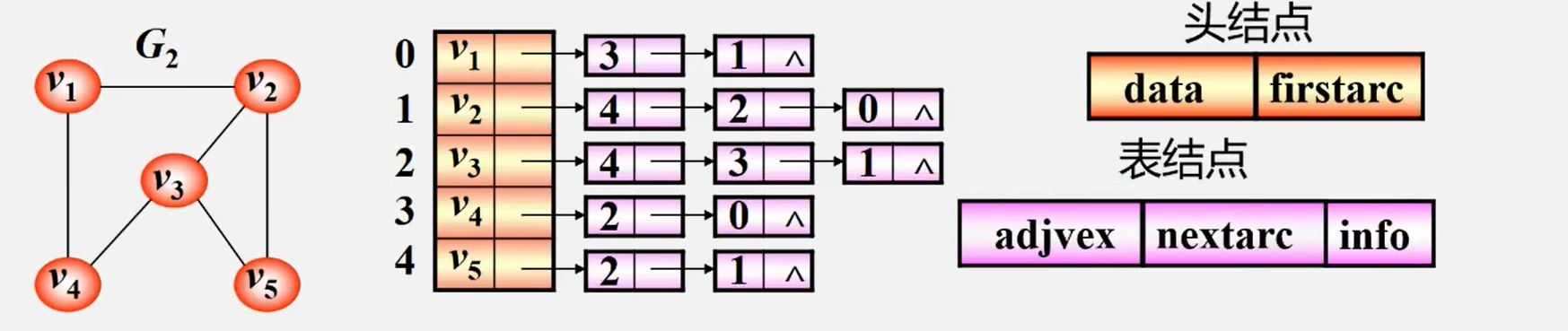
adjvex:邻接点域,存放与邻接的顶点在表头数组中的位置。
nextarc:链域,指示下一条边或弧
info:存放网图中的权值或其他信息
顶点:
按编号顺序将顶点数据存储在一维数组中
关联同一顶点的边(以顶点为尾的弧)用线性链表存储。
无向图的邻接表表示法
特点:
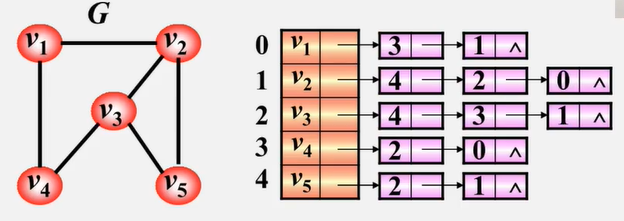
- 邻接表不唯一(v1有到v4的边 有到v2的边,链表中边的顺序不唯一)
- 若
无向图中有n个顶点、e条边,则其邻接表需n个头结点和2e个表结点。适宜存储稀疏图。 - 无向图中顶点 Vi 的
度为第 i 个单链表中的结点数
有向图的邻接表表示法

特点:
- 顶点 Vi 的出度为第 i 个单链表中的结点个数。
- 顶点 Vi 的入度为整个单链表中邻接点域值是 i-1 的结点个数
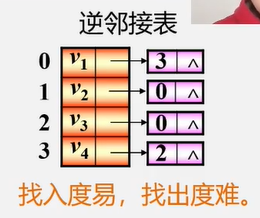
可以将出度表换为入度表
- 顶点 Vi 的入度为第i个单链表中的结点个数。
- 顶点 Vi 的出度为整个单链表中邻接点域值是 i-1 的结点个数。
根据业务需要来选择邻接表还是逆邻接表
练习:
已知某网的邻接(出边)表,请画出该网络。
当邻接表的存储结构形成后,图便唯一确定!

邻接表的建立
 假如有这样的图如何建立他的邻接表?
假如有这样的图如何建立他的邻接表?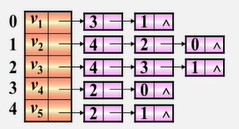

结构定义


public class ALGraph {
class VNode{
char data; //顶点信息
ArcNode firstArc; //指向第一条依附该顶点的边的指针
}
//边结点
class ArcNode{
int adjvex; //该边所指向的顶点位置
ArcNode nextArc; //指向下一条边的指针
int otherInfo; //和边相关的其他信息,例如权值
}
VNode[] nodes; //顶点列表
int vexNum; //当前定点数
int arcNum; //当前弧数
}
操作说明

算法思想
(1)输入总顶点数和总边数。
(2)建立顶点表
依次输入顶点的信息存入顶点表中使每个表头结点的指针域初始化为NULL
(3)创建邻接
表依次输入每条边依附的两个顶点
确定两个顶点的序号 i 和 j ,建立边结点
将此边结点分别插入到 Vi 和 Vj 对应的两个边链表的头部(头插法)
邻接表表示法创建无向网


//TODO
邻接表特点

1、方便找任一顶点的所有“邻接点”
2、节约稀疏图的空间
需要N个头指针+2E个结点(每个结点至少2个域)
3、方便计算任一顶点的“度”?
对无向图:是的
对有向图:只能计算出度;需要构造逆邻接表”(存指向自己的边)来方便计算度
4、不方便检查任意一对顶点间是否存在边
邻接矩阵与邻接表表示法的关系
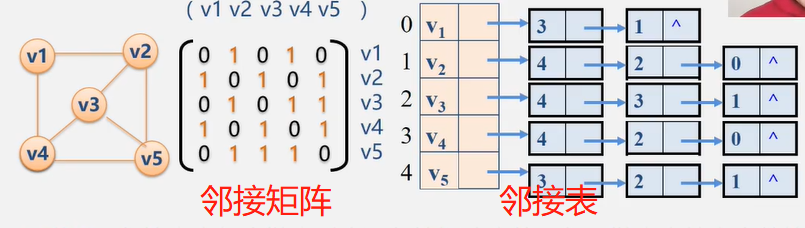
1、联系:邻接表中每个链表对应于邻接矩阵中的一行,链表中结点个数等于一行中非零元素的个数
2、区别
①对于任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一致),但邻接表不唯一(链接次序与顶点编号无关)。
②邻接矩阵的空间复杂度为O(n*n)而邻接表的空间复杂度为O(n+e)。
3、用途:邻接矩阵多用于稠密图;而邻接表多用稀疏图。
邻接表的改进——十字链表、邻接多重表

十字链表
十字链表( Orthogonal List),是有向图的另一种链式存储结构我们也可以把它看成是将有向图的邻接表和逆邻接表结合起来形成的一种链表。
有向图中的每一条弧对应十字链表中的一个弧结点,同时有向图中的每个顶点在十字链表中对应有一个结点,叫做顶点结点。


firstin:第一条入边
firstout:第一条出边
tailvex:弧尾顶点位置
headvex:弧头位置
hink:弧头相同的下一条弧
tink:弧尾相同的下一条弧
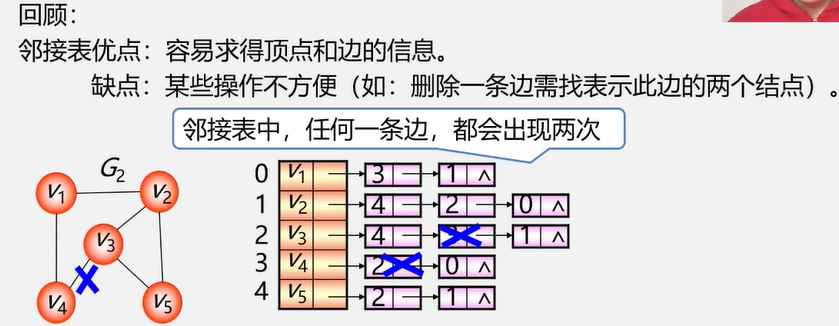
邻接多重表
解决无向图每条边都要存两边的问题
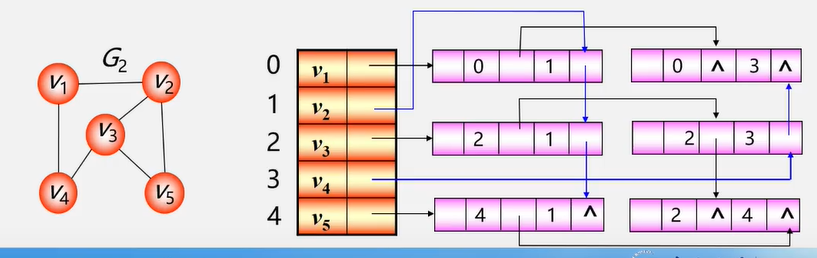
6.5图的遍历
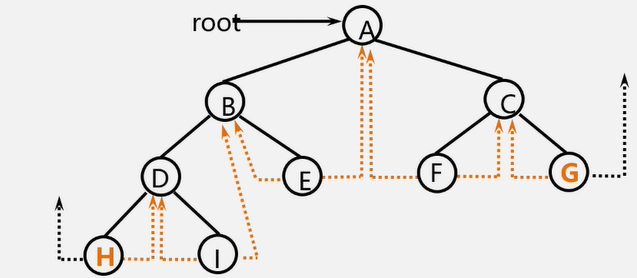
遍历定义:从已给的连通图中某一顶点出发,沿着一些边访遍图中所有的顶点,且使每个顶点仅被访问一次,就叫做图的遍历,它是图的基本运算。
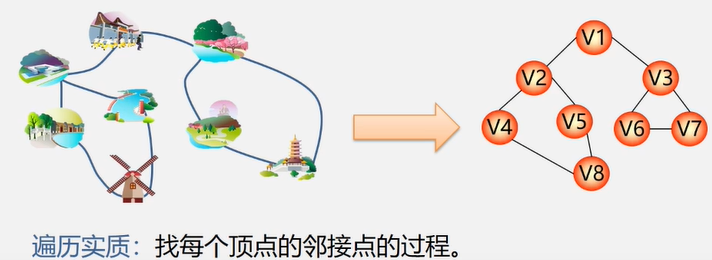
图的特点:图中可能存在回路,且图的任一顶点都可能与其它顶点相通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。
如何避免重复访问?
解决思路:设置辅助数组 visited[n] ,用来标记每个被访问过的顶点。
初始状态 visited[i] 为 0
顶点被访问,改 visited[i] 为 1 防止被多次访问
图常用的遍历:
- 深度优先搜索( Depth First Search--DFS
- 广度优先搜索( Breadth frist search-BFS)
深度优先遍历(DFS)
例子:点亮迷宫中所有的灯
遍历思想
一条道走到黑,有临界点没访问就访问,
方法
■在访问图中某一起始顶点v后,由v出发,访问它的任一邻接顶点W1;
■再从W1出发,访问与W邻接但还未被访问过的顶点W2
■然后再从W2出发,进行类似的访问,
■如此进行下去,直至到达所有的邻接顶点都被访问过的顶点 u 为止。
■接着,退回一步,退到前一次刚访问过的顶点,看是否还有其它没有被访问的邻接顶点。
■如果有,则访问此顶点,之后再从此顶点出发,进行与前述类似的访问
■如果没有,就再退回一步进行搜索。重复上述过程,直到连通图中所有顶点都被访问过为止

连通图的深度优先遍历类似于树的先根遍历
邻接矩阵表示的无向图深度优先遍历实现
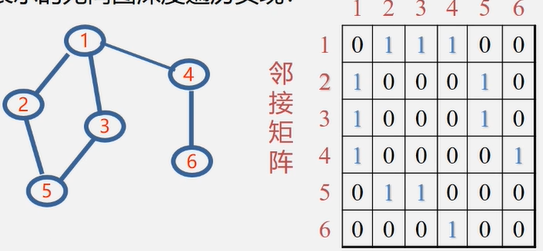

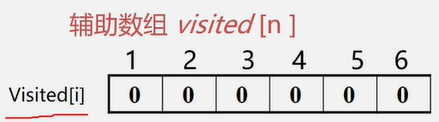
使用辅助数组来判断顶点是否被访问过,默认为0 , 被访问过表记1.
这里我们假设遍历起点为2.

//深度优先搜索遍历 v 开始遍历的顶点
void DFS(int v){
//创建辅助数组
System.out.println(vexs[v]);
boolean[] visited = new boolean[vexmun];
visited[v] = true;
//依次检查 v 所在行的定点
for (int w = 0; w < vexmun; w++) {
if (arcs[v][w] != 0 && !visited[w]){
DFS(w);
}
}
}
邻接表表示的无向图深度优先遍历实现
算法效率
用邻接矩阵来表示图,遍历图中每一个顶点都要从头扫描该顶点所在行,时间复杂度为O(n * n)
用邻接表来表示图,虽然有2e个表结点,但只需扫描e个结点即可完成遍历,加上访问m个头结点的时间,时间复杂度为O(m+e)
结论:
- 稠密图适于在邻接矩阵上进行深度遍历
- 稀疏图适于在邻接表上进行深度遍历。
非连通图的深度优先遍历
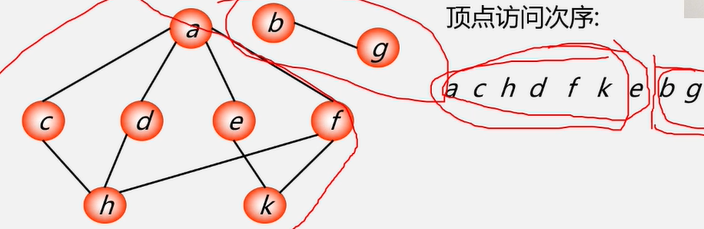
广度优先搜索遍历(BFS)
遍历思想
方法:从图的某一结点出发,首先依次访问该结点的所有邻接顶点,Vi1 , Vi2,...,Vin 再按这些顶点被访问的先后次序依次访问与它们相邻接的所有未被访问的顶点
重复此过程,直至所有顶点均被访问为止。
和树的层次遍历非常相似

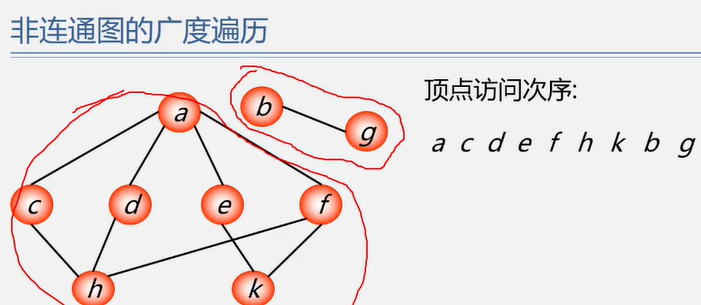
实现
使用队列保存顶点的下一元素,使用数组保存顶点是否被访问过

效率分析
如果使用邻接矩阵,则BFS对于每一个被访问到的顶点,都要猸环检测矩阵中的整整一行(n个元素),总的时间代价为O(n*n)
用邻接表来表示图,虽然有2e个表结点,但只需扫描e个结点即可完成遍历,加上访问n个头结点的时间,时间复杂度为o(n+e)
DFS与BFS算法效率比较
空间复杂度相同,都是o(n) (借用了堆栈或队列)
时间复杂度只与存储结构、(邻接矩阵或邻接表)有关,而与搜索路径无关
6.6图的应用
最小生成树
生成树:
所有顶点均由边连接在一起,但不存在回路的图。
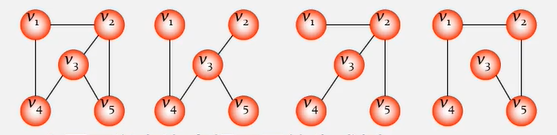
-
一个图可以有许多棵不同的生成树
-
所有生成树具有以下共同特点
- 生成树的顶点个数与图的
顶点个数相同 - 生成树是图的
极小连通子图,去掉一条边则非连通 - 一个有 n 个顶点的连通图的生成树有 n - 1条边
在生成树中再加一条边必然形成回路。- 生成树中任意两个顶点间的路径是唯一的
- 生成树的顶点个数与图的
-
含 n 个顶点n-1条边的图不一定是生成树
无向图的生成树

设图G=(V ,E)是个连通图,当从图任一顶点出发遍历图G时,将边集E(G)分成两个集合T(G)和B(G)。其中T(G)是遍历图时所经过的边的集合,B(G)是遍历图时未经过的边的集合。显然,G1(V,T)是图G的极小连通子图。即子图G1是连通图G的生成树。
最小生成树
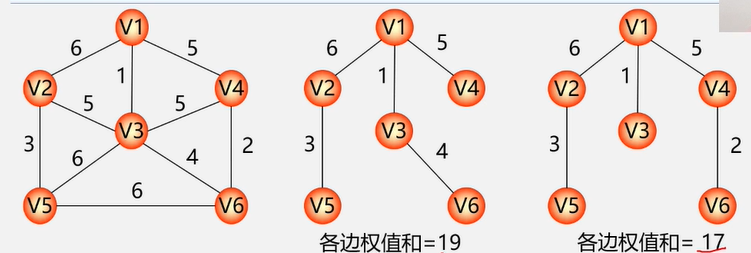
最小生成树:给定一个无向网络,在该网的所有生成树中,使得各边权值之和最小的那棵生成树称为该网的最小生成树也叫最小代价生成树。
典型应用
欲在n个城市间建立通信网,则n个城市应铺 n-1 条线路;
但因为每条线路都会有对应的经济成本,而n个城市最多有n(n-1)/ 2条线路,那么,如何选择n-1条线路,使总费用最少?显然此连通网是一个生成树。

构造最小生成树


在生成树的构造过程中,图中n个顶点分属两个集合
已落在生成树上的顶点集:U
尚未落在生成树上的顶点集:V-U
接下来则应在所有连通∪中顶点和V-∪中顶点的边中选取权值最小的边
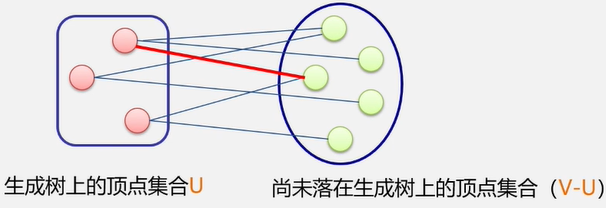
普里姆(Prim)算法


克鲁斯卡尔(Kruskal)算法

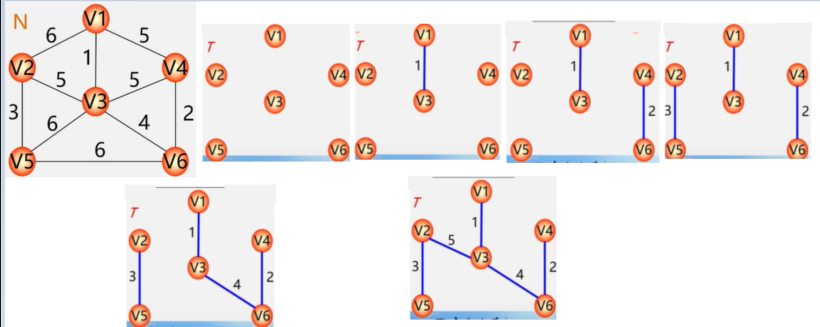
两种算法比较

最短路径
典型用途:交通网络的问题—从甲地到乙地之间是否有公路连通?在有多条通路的情况下,哪一条路最短?
交通网络用有向网来表示:
顶点——表示地点
弧——表示两个地点有路连通
弧上的权值——表示两地点之间的距离、交通费或途中所花费的时间等
如何能够使一个地点到另一个地点的运输时间最短或运费最省?这就是一个求两个地点间的最短路径问题。
问题抽象:在有向网中A点(源点)到达B点(终点)的多条路径中,寻找一条各边权值之和最小的路径,即最短路径。
最短路径与最小生成树不同,路径上不一定包含n个顶点,也不定包合n-1条边。
第一类问题:两点间最短路径
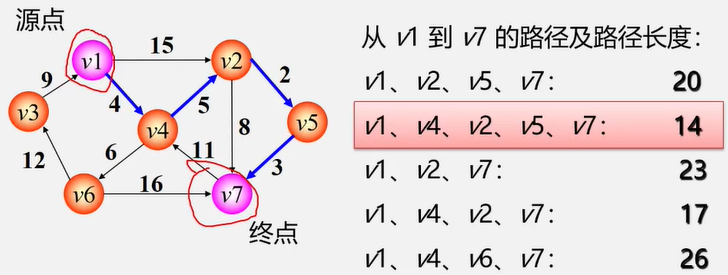
第二类问题:某源点到其他各点最短路径

两种常见的最短路径问题:
一、单源最短路径——用Dijkstra(迪杰斯特拉)算法
二、所有顶点间的最短路径——用Floyd(弗洛伊德)算法
Dijkstra(迪杰斯特拉)算法


迪杰斯特拉( Dijkstra)算法:按路径长度递增次序产生最短路径

 、
、
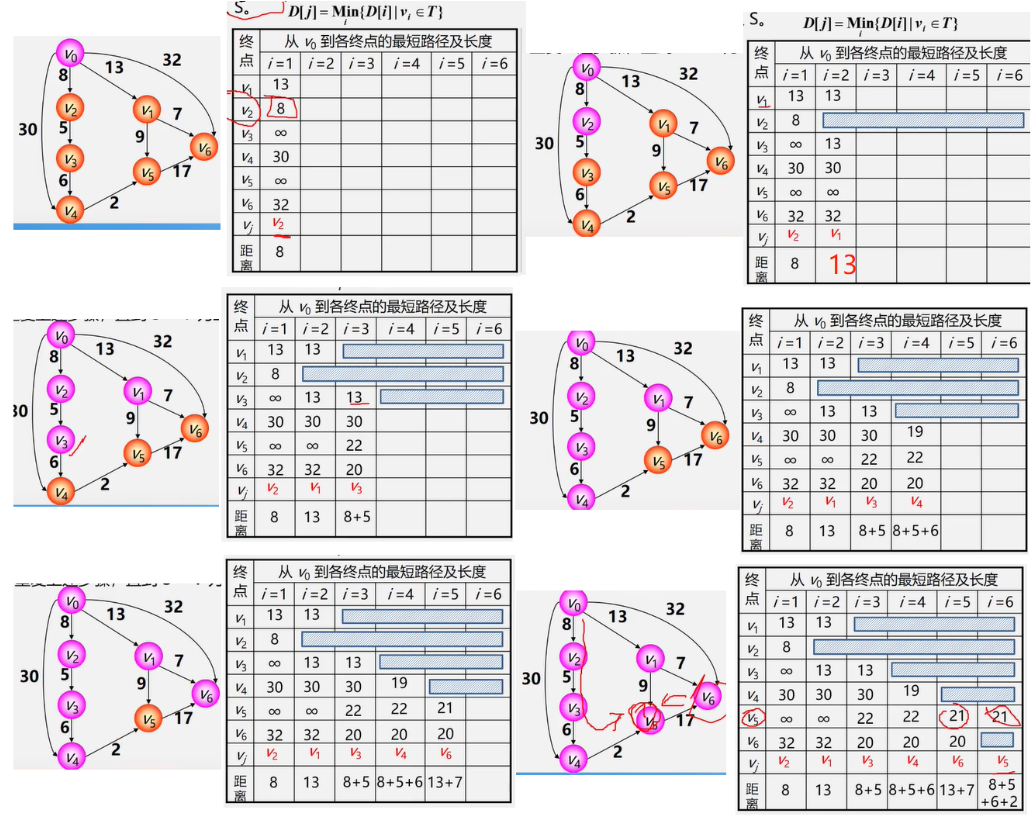
Floyd(弗洛伊德)算法
所有顶点间的最短路径
算法思想:
- 逐个顶点试探
- 从 Vi 到 Vj 的所有可能存在的路径中
- 选出一条长度最短的路径
求最短路径步骤: 初始时设置一个 n 阶方阵,令其对角线元素为0,若存在弧<Vi,Vj>,则对应元素为权值;否则为∞。
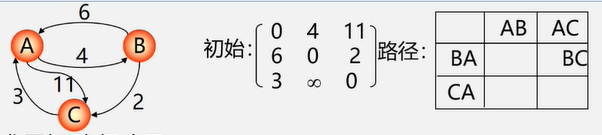
逐步试着在原直接路径中增加中间顶点,若加入中间顶点后路径变短,则修改之;否则,维持原值。所有顶点试探完毕,算法结束。
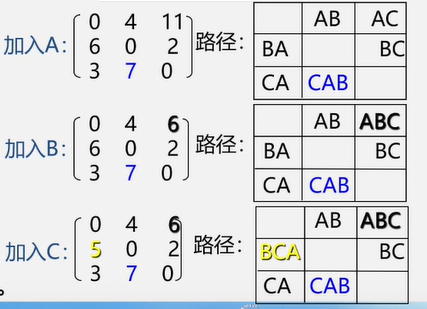
有向无环图及其应用
有向无环图:无环的有向图,简称DAG图 Directed acycline Graoh)
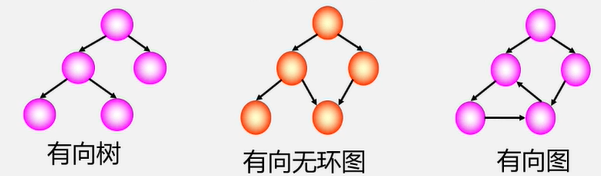
有向无环图常用来描述一个工程或系统的进行过程。(通常把计划施工、生产、程序流程等当成是一个工程)
一个工程可以分为若干个子工程,只要完成了这些子工程(活动)就可以导致整个工程的完成
AOV网:
用来解决拓扑排序问题
用一个有向图表示一个工程的各子工程及其相互制约的关系,其中以顶点表示活动,弧表示活动之间的优先制约关系,称这种有向图为顶点表示活动的网,简称AOV网( Activity On Vertex network)。
若从i到j有一条有向路径,则i是j的前驱; j是i的后继。
若<i,j>是网中有向边,则i是j的直接前驱;j是i的直接后继。
AOV网中不允许有回路,因为如果有回路存在,则表明某项活动以自己为先决条件,显然这是荒谬的。
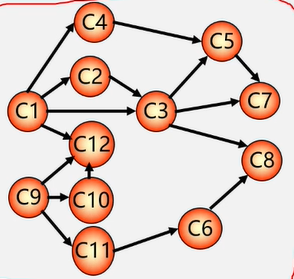
问题:如何判别AOV网中是否存在回路?
这里就需要用到拓扑排序
AOE网:
用来解决关键路径问题
用一个有向图表示一个工程的各子工程及其相互制约的关系,以弧表示活动,以顶点表示活动的开始或结束事件,称这种有向图为边表示活动的网,简称为AOE网( Activity On Edge)。
拓扑排序
在AOV网没有回路的前提下,我们将全部活动排列成一个线性序列,使得若AOV网中有弧<i , j>存在,则在这个序列中,i一定排在j的前面,具有这种性质的线性序列称为拓扑有序序列,相应的拓扑有序排序的算法称为拓扑排序。

1、在有向图中选一个没有前驱的顶点且输出之。
2、从图中删除该顶点和所有以它为尾的弧。
重复上述两步,直至全部顶点均已输出或者当图中不存在无前驱的顶点为止
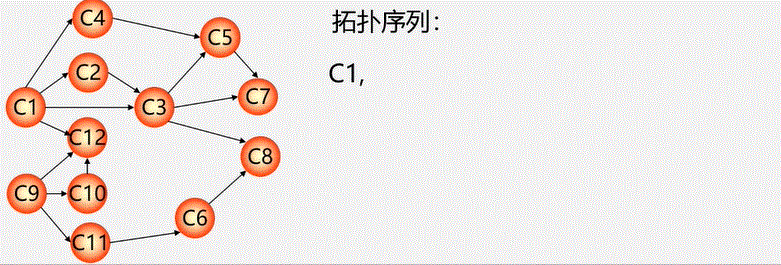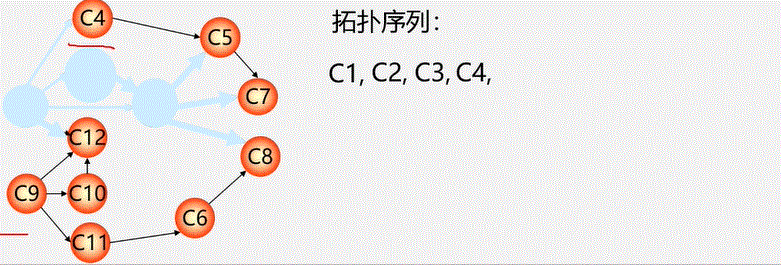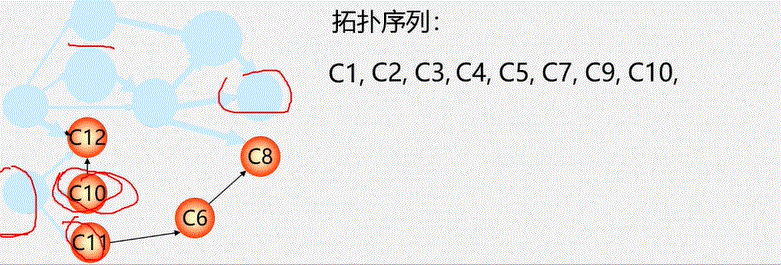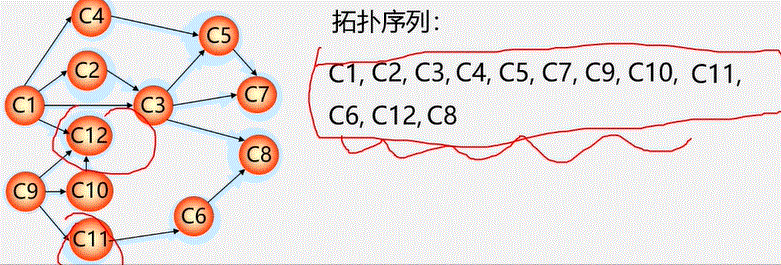

检测AOV网中是否存在环
对有向图构造其顶点的拓扑有序序列,若网中所有顶点都在它的拓扑有序序列中,则该AOV网必定不存在环。

关键路径
【例1】某项目的任务是对A公司的办公室重新进行装修,如果10月1日前完成装修工程,项目最迟应该何时开始?
需完成的活动、活动所需时间、及先期需完成工作如图所示
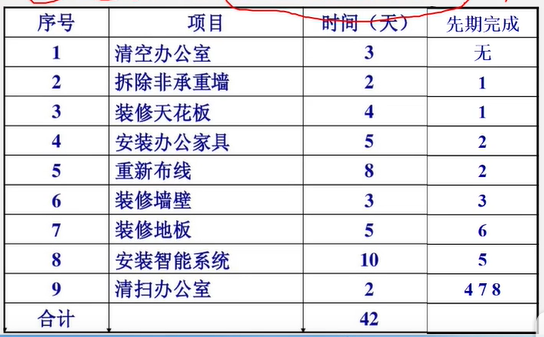
【例2】准备一个小型家庭宴会,晚6点宴会开始,最迟几点开始准备?压缩哪项活动时间可以使总时间减少?
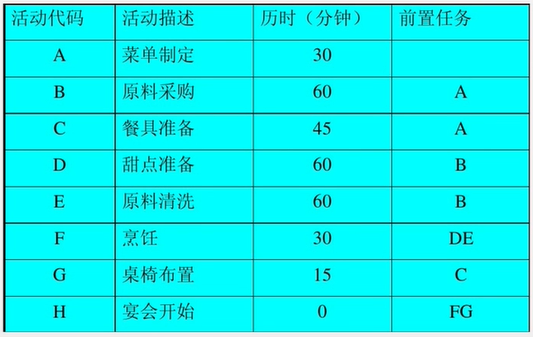
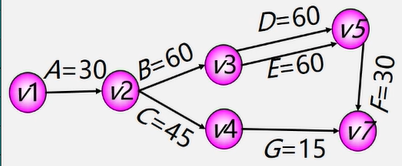
把工程计划表示为边表示活动的网络,即AOE网,用顶点表示事件,弧表示活动,弧的权表示活动持续时间。
事件表示在它之前的活动已经完成,在它之后的活动可以开始。
例:设一个工程有11项活动,9个事件。
事件V1——表示整个工程开始(源点:入度为0的顶点)
事件V9—一表示整个立程结束(汇点:出度为0的顶点)
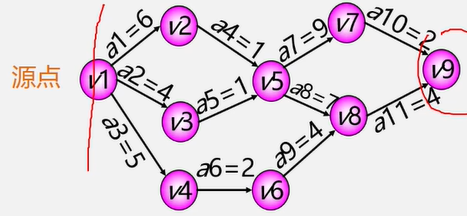
对于AOE网,我们关心两个问题
(1)完成整项工程至少需要多少时间?
(2)哪些活动是影响工程进度的关键?
关键路径——路径长度最长的路径
路径长度——路径上各活动持续时间之和。
关键路径
如何确定关键路径,需要定义4个描述量:


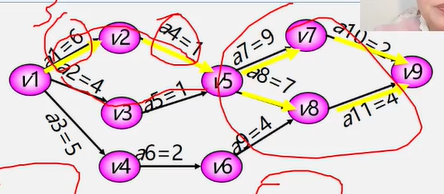
1、若网中有几条关键路径,则需加快同时在几条关键路径上的关键活动如:a11、a10、a8、a7
2、如果一个活动处于所有的关键路径上,那么提高这个活动的速度,就能缩短整个工程的完成时间。如:a1、a4。
3、处于所有的关键路径上的活动完成时间不能缩短太多,否则会使原来的关键路径变成不是关键路径。这时,必须重新寻找关鍵路径。如:a1由6天变成3天,就会改变关键路径。
基本的数据处理技术
查找技术
查找的概念
问题:在哪里找?
查找表是由同一类型的数据元素(或记录)构成的集合。由于“集合”中的数据元素之间存在着松散的关系,因此查找表是一种应用灵便的结构。
问题:什么是查找?
根据给定的某个值,在查找表中确定一个某关键字等于给定值的数据元素或(记录)
关键字——用来标识一个数据元素(或记录)的某个数据项的值
主关键字——可唯一地标识一个记录的关键字是主关键字:
次关键字——反之,用以识别若干记录的关键字是次关键字。
问题:查找成功否?
若查找表中存在这样一个记录,则称“查找成功“
查找结果给出整个记录的信息,或指示该记录在查找表中的位置;、
否则称“查找不成功”。查找结果给出“空记录”或“空指针”。
问题查找目的是什么?
对查找表经常进行的操作:
1、查询某个“特定的”数据元素是杏在查找表中;
2、检索某个“特定的”数据元素的各种属性;
3、在查找表中插入一个数据元素;
4、删除查找表中的某个数据元素。
问题:查找表怎么分类?
查找表可分为两类:
静态查找 表:
仅作(检索)操作的查找表。
动态查找表
作”插入“和“删除”操作的查找表。
有时在查询之后,还需要将“查询”结果为“不在查找表中”的数据元素插入到查找表中;或者,从查找表中删除其查询结果为"查我表中”的数据元素,此类表为动态查找表.
问题:如何评价查找算法
查找算法的评价指标:

问题:查找过程中我们要研究什么?
查找的方法取决于查找表的结构,即表中数据元素是依何种关系组织在一起的。
由于对查找表来说,在集合中查询或检索一个“特定的”数据元素时,若无规律可循,只能对集合中的元素—一加以辨认直至找到为止。
而这样的“查询”或“检索”是任何计算机应用系统中使用频度都很高的操作,因此设法提高査找表的査找效率,是本章讨论问题的出发点
为提高査找效率,一个办法就是在构造查找表时,在集合中的数据元素之间人为地加上某种确定的约关系
研究查找表的各种组织方法及其查找过程的实施
线性表的查找
顺序查找
应用范围:
-
顺序表或线性链表表示的静态查找表
-
表内元素之间无序
//数据元素类型定义
typedef struct{
KeyType key; //关键字域
... //其他域
}ElemType
//顺序表的表示
typedef struct{
ElemType *R //表基址
int length; //表厂
}SSTable;//Sequential Search Table
SSTable ST;// 定义顺序表St
在顺序表ST中查找值为key的数据元素。从最后一个元素开始比较

//查找元素
int locateElem(int b){
for (int i = 1; i < length; i++) {
if (data[i] == b) return i;
}
return 0;
}
其他形式

设置监视哨的顺序查找
改进:把待查关键字key存入表头(“哨兵”、”监视哨”),可免去査找过程中每一步都要检测是否査找完毕,加快速度。

//设置监视哨的顺序查找
int seachElem(int e){
data[0] = e;
int i = data.length;
for (; data[i] != e ; i--);
return i;
}
当ST.length较大时,此改进能使进行一次查找所需的平均时间几乎减少一半。
时间效率分析


讨论:
1、记录的查找概率不相等时如何提高查找效率?
查找表存储记录原则—按査找概率高低存储
1)查找概率越高,比较次数越少;
2)查找概率越低,比较次数较多。
2、记录的查找概率无法测定时如何提高查找效率?
方法——按查找概率动态调整记录顺序
1)在每个记录中设一个访问频度域
2)始终保持记录按非递增有序的次序推列
3)每次查找后均将刚查到的记录直接移至表头
特点:
优点:算法简单,逻辑次序无要求,且不同存储结构均适用。
缺点:ASL太长,时间效率太低。
折半查找(二分或对分)
折半查找:每次将待查记录所在区间缩小一半
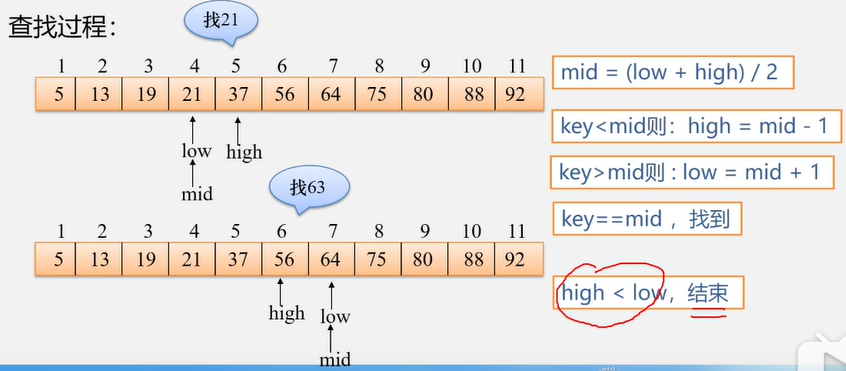


//二分查找
int binSearch(int e){
int left = 1; //低位
int rigth = data.length;//高位
while (left <= rigth){
int mid = (left + rigth) / 2;
if (data[mid] == e){ //找到待查元素
return mid;
}else if (e < data[mid]){ //缩小查找区间
rigth = mid-1; //在前半区查找
} else {
left = mid+1; //在后半区查找
}
}
return 0;
}
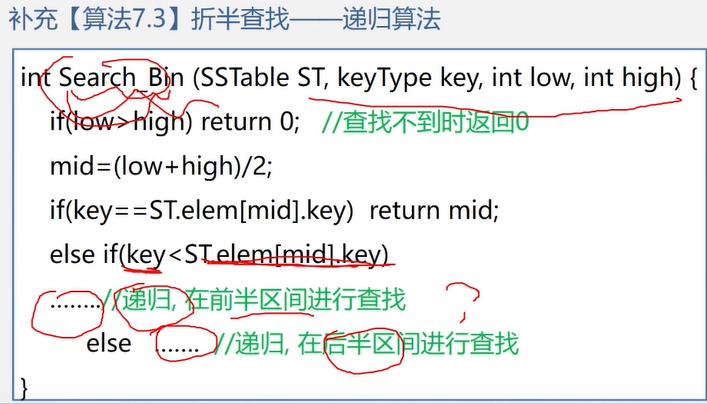
折半查找的性能分析-判定树

假定每个元素的查找概率相等,求查找成功时的平均查找长度。
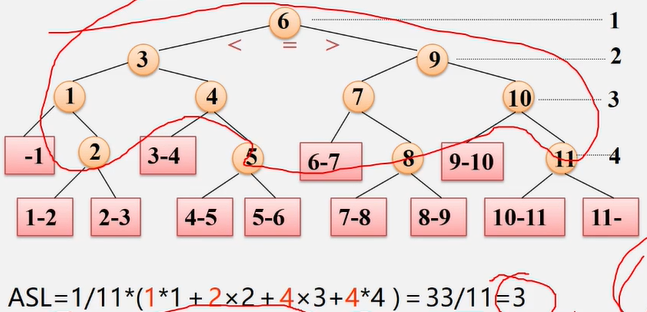
平均查找长度ASL(成功时):

折半查找优点:效率比顺序查找高。
折半查找缺点:只适用有序表,且限于顺序存结构(对线性链表无效)
分块查找(索引顺序查找)


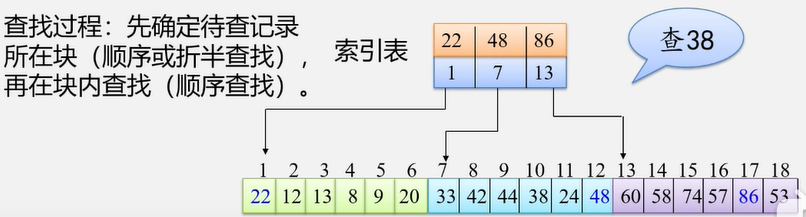
性能分析

优点:插入和删除较容易,无需进行大量移动
缺点:要增加一个索引表的存储空间并对初始索引表进行排序运算。
适用情况:如果线性表既要快速查找又经常动态变化,则可采用分块查找
查找方法比较
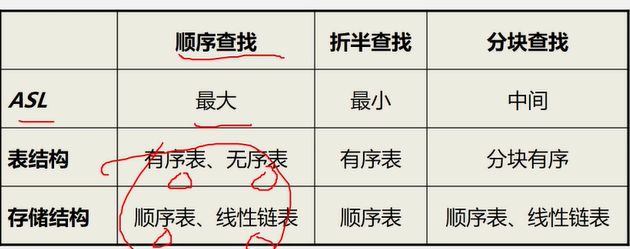
树表的查找
当表插入、删除操作频繁时,为维护表的有序性,需要移动表中很多记录。
改用动态查找表——几种特殊的树
- 二叉排序树
- 平衡二叉树
- 红黑树
- B - 树
- B + 树
- 键树
表结构在查找过程中动态生成
对于给定值key若表中存在,则成功返回;
否则,插入关键字等于key的记录
二叉排序树/搜索树/查找树
二叉排序树( Binary Sort Tree)又称为二叉搜索树、二叉查找树,
定义:
二叉排序或是空树,或是满足如下性质的二叉树
1、若其左子树非空,则左子树上所有结点的值均小于根结点的值;
2、若其右子树非空,则右子树上所有结点的值均大于等于根结点的值;
3、其左右子树本身又各是棵二叉排序树
小左 大右
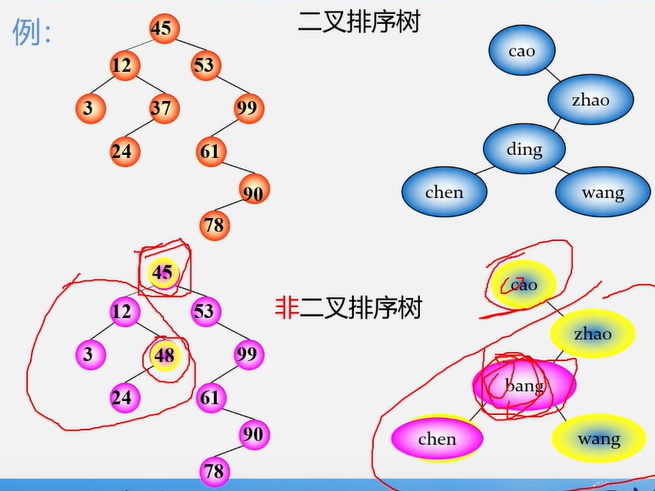
思考:中序遍历二叉排序树结果有什么规律?

3 12 24 37 45 53 61 78 90 100 ——》 递增
二叉排序树的性质:
中序遍历非空的二叉排序树所得到的数据元素序列是一个按关键字排列的递增有序序列。
二叉排序树存储结构
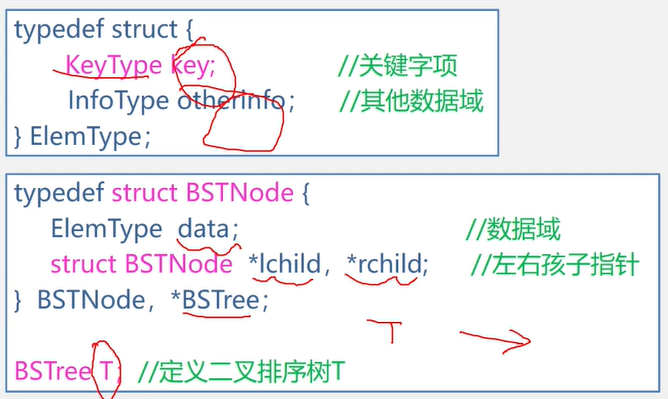
public class BSTree {
class BSTNode{
int data;
BSTNode lchild;
BSTNode rchild;
}
BSTNode root;
}
二叉排序树的查找
若查找的关键字等于根结点,成功
否则
若小于根结点,查其左子树
若大于根结点,查其右子树
在左右子树上的操作类似
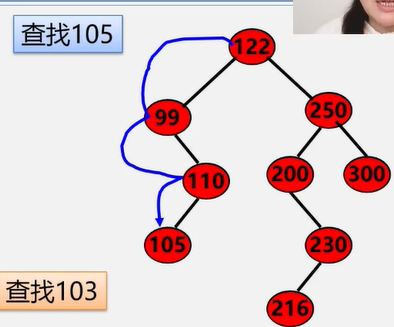
二叉排序树的递归查找
【算法思想】
(1)若二叉排序树为空,则查找失败,返回空指针。
(2)若二叉排序树非空,将给定值key与根结点的关键字T->data. keyj进行比较
①若key等于T->data.key,则查找成功,返回根结点地址;
②若key小于T->data.key,则进一步查找左子树;
③若key大于T-> data. key,则进一步查找右子树。

int search(int e){
return search(e,root);
}
//二叉排序树的递归查找
int search(int e , BSTNode node){
if (node == null) return -1;
if (node.data == e){
return node.data;
}else if (e < node.data){
return search(e , node.lchild);
}else {
return search(e , node.rchild);
}
}
二叉排序树的操作
插入
若二叉排序树为空,则插入结点作为根结点插入到空树中
否则,继续在其左、右子树上查找
树中已有,不再插入
树中没有
查找直至某个叶子结点的左子树或右子树为空为止,则插入结点应为该叶子结点的左孩子或右孩子
插入的元素一定在叶结点上
void insert(int e){
insert(e , root);
}
//二叉排序树的插入
void insert(int e , BSTNode node){
if (node == null){ //为空则插入到空树中
node = new BSTNode();
node.data = e;
}else if(e == node.data){ //树中已有不操作
}else if (e < node.data){
insert(e , node.lchild);
}else {
insert(e , node.rchild);
}
}
生成
从空树出发,经过一系列的查找、插入操作之后,可生成一楳二叉排序树。
例:设查找的关键字序列为{45 , 24 , 53 , 45 , 12 , 24 , 90}可生成二叉排序树如下:
一个无序序列可通过构造二叉排序树而变成一个有序序列。
构造树的过程就是对无序序列进行排序的过程。
插入的结点均为叶子结点,故无需移动其他结点。相当于在有序序列上插入记录而无需移动其他记录。
但是关键字的输入顺序不同,建立的不同二叉排序树

//生成二叉排序树
BSTree create(int[] elems){
BSTree tree = new BSTree();
for (int i = 0; i < elems.length; i++) {
tree.insert(elems[i]);
}
return tree;
}
删除
从二叉排序树中删除一个结点,不能把以该结点为根的子树都删去,只能删掉该结点,并且还应保证删除后所得的二叉树仍然满足二叉排序树的性质不变。
由于中序遍历二叉排序树可以得到一个递增有序的序列。那么,在二叉排序树中删去一个结点相当于删去有序序列中的一个结点
- 将因删除结点而断开的二叉链表重新链接起来
- 防止重新链接后树的高度增加
(1)被删除的结点是叶子结点:直接删去该结点
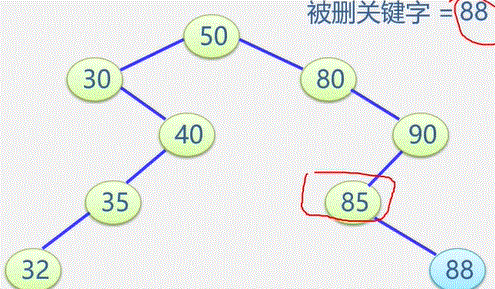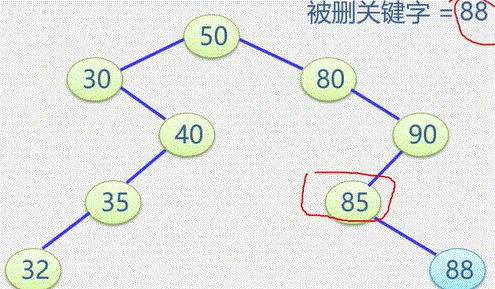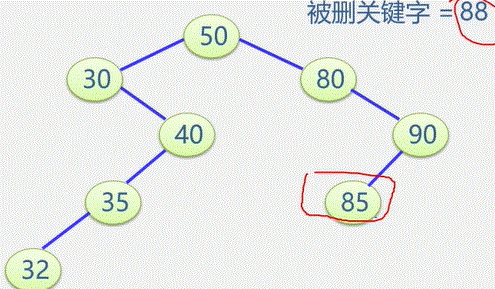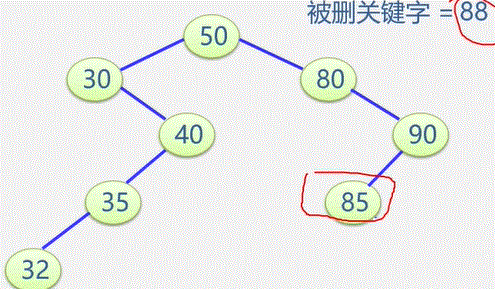
(2)被删除的结点只有左子树或者只有右子树,用其左子树或者右子树替换它(结点替换)。
其双亲结点的相应针域的值改为“指向被删除结点的左子树或右子树
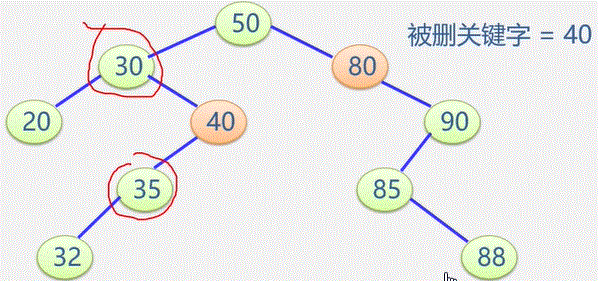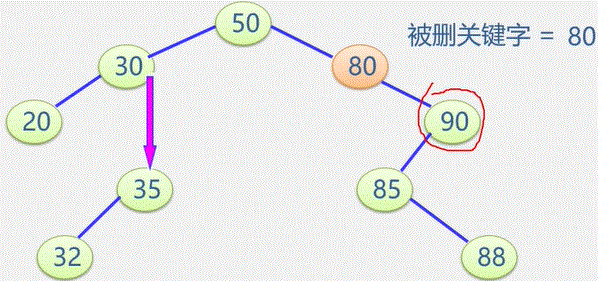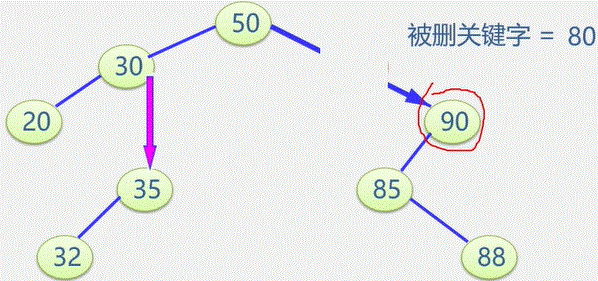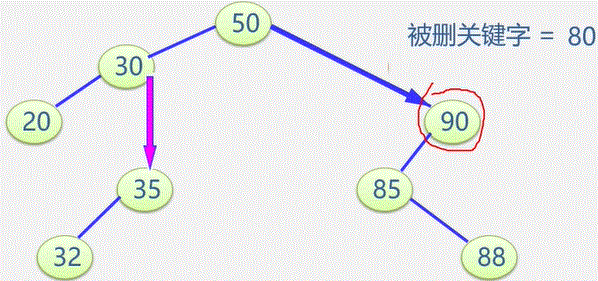
(3)被删除的结点既有左子树,也有右子树
以一种方式:以其中序前趋值替换之(值替换),然后再删除该前趋结点。前趋是左子树中最大的结点。
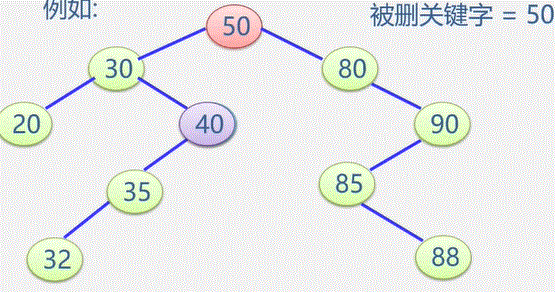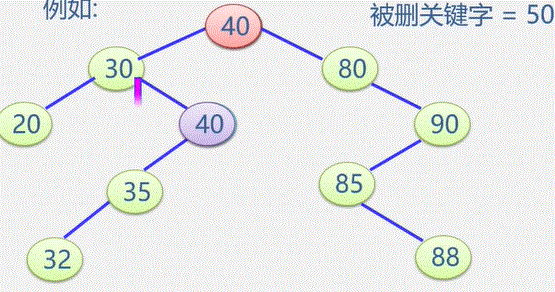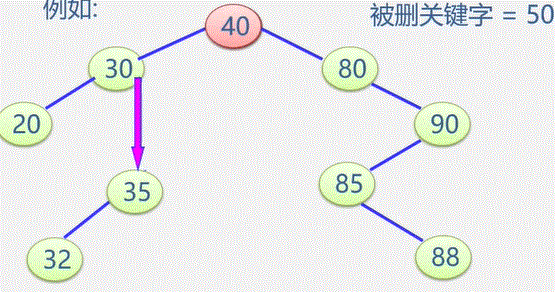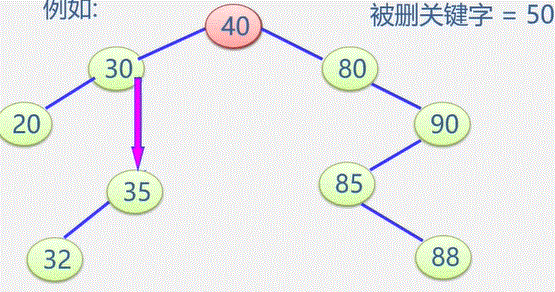
第二种方式:
可以用其后继替换之,然后再删除该后继结点。后继是右子树中最小的结点。
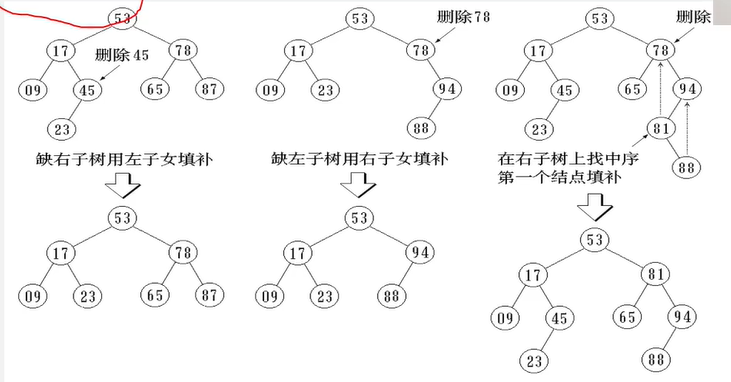
二叉排序树的查找分析
二叉排序树上查找某关键字等于给定值的结点过程,其实就是走了一条从根到该结点的路径。
比较的关键字次数 = 此结点所在层次数
最多的比较次数 = 树的深度
二叉排序树的平均查找长度:



问题:
如何提高形态不均衡的二叉排序树的查找效率?
解决办法:做“平衡化”处理,即尽量让二叉树的形状均衡,这就是平衡二叉树
平衡二叉树AVL
平衡二又树( balanced binary tree)又称AVL树( Adelson- Velskii and landis)。
一棵平衡二叉树或者是空树,或者是具有下列性质的二叉排序树
1、左子树与右子树的高度之差的绝对值小于等于1
2、左子树和右子树也是平衡二叉排序树
为了方便起见,给每个结点附加一个数字,给出该结点左子树与右子树的高度差。这个数字称为结点的平衡因子(BF)
平衡因子 = 结点左子树的高度 - 结点右子树的高度
根据平衡二叉树的定义,平衡二叉树上所有结点的平衡因子只能是 -1、0,或1

失衡二叉排序树的分析与调整
当我们在一个平衡二叉排序树上插入一个结点时,有可能导致失衡,即出现平衡因子绝对值大于1的结点,如:2、-2
 '
'
如果在一棵AVL树中插入一个新结点后造成失衡,划必须重新调整树的结构,使之恢复平衡。
平衡调整的四种类型:
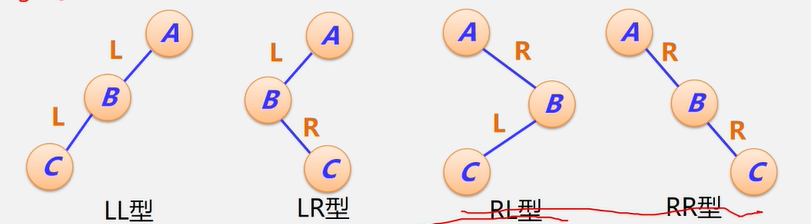
A:失衡结点 不止一个失衡结点时,为最小失衡子树的根结点
B: A结点的孩子,C结点的双亲
C:插入新结点的子树
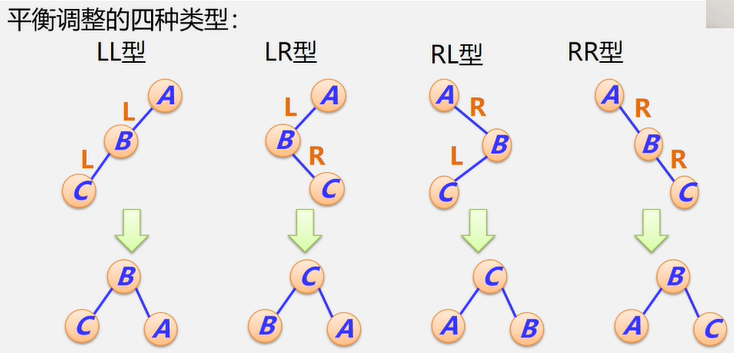

LL型调整
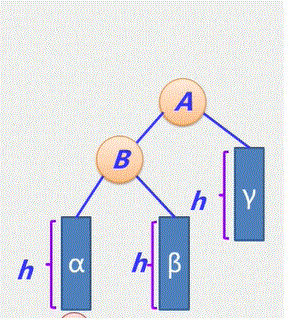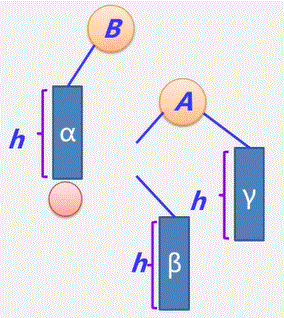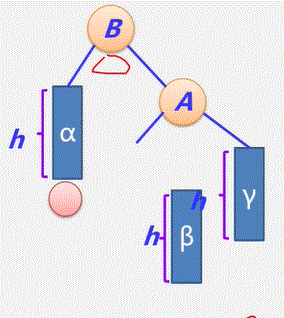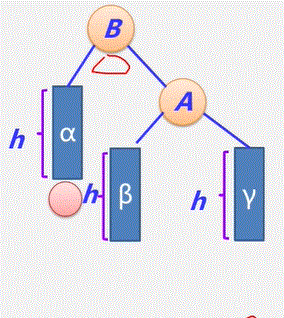
- B结点带左子树α一起上升
- A结点成为B的右孩子
- 原来B结点的右子树β作为A的左子树
RR型调整
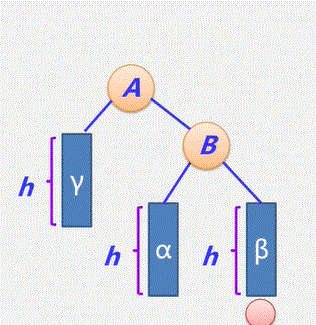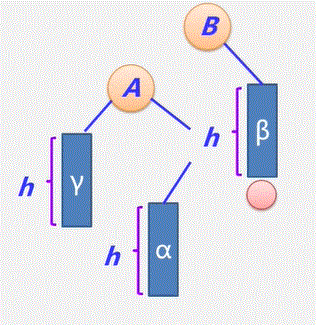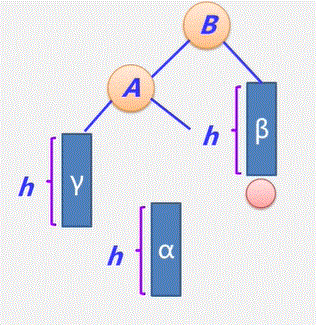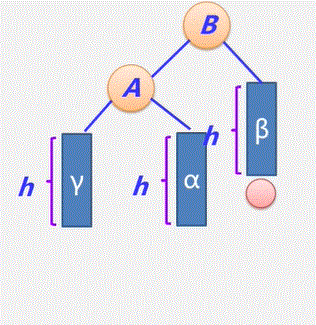
- B结点带右子树β—起上升
- A结点成为B的左孩子
- 原来B结点的左子树α作为A的右子树
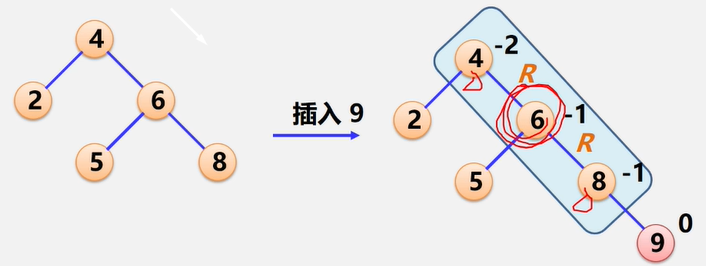
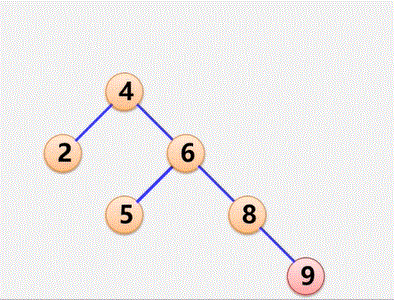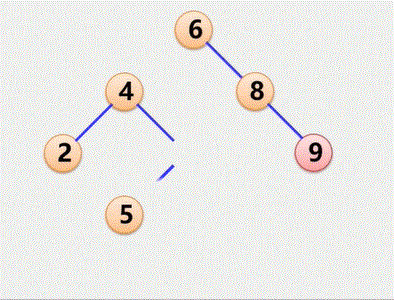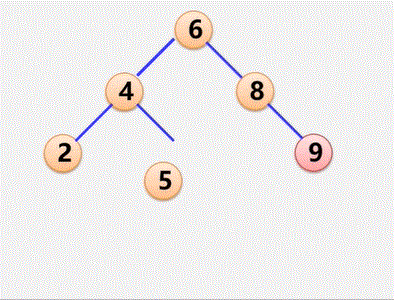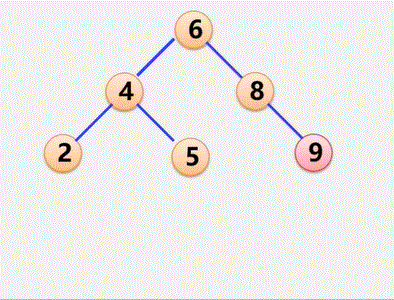
LR型调整
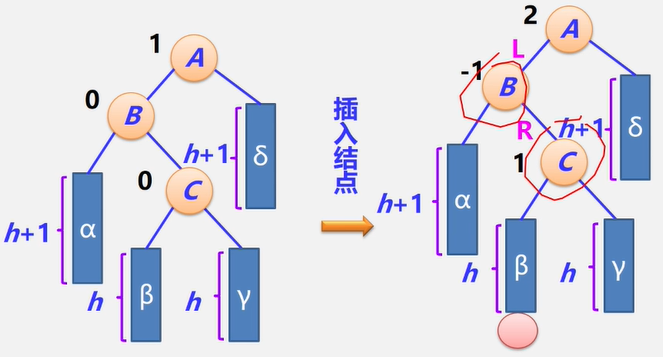
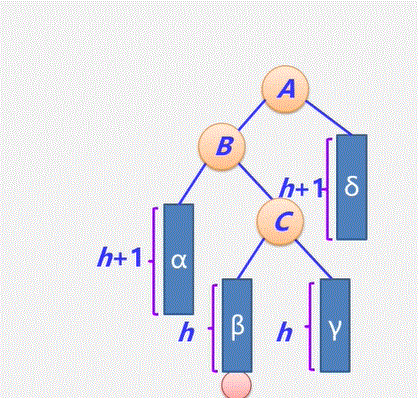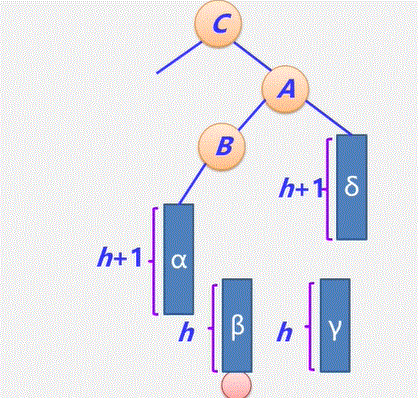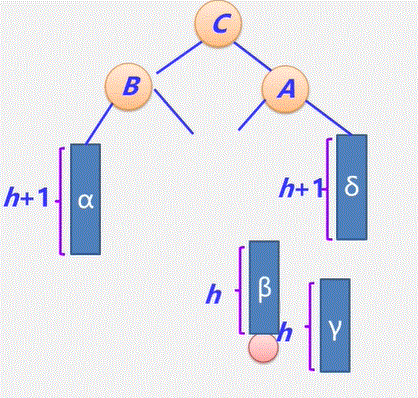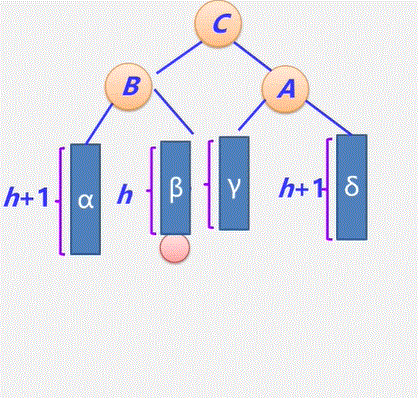
- C结点穿过A、B结点上升
- B结点成为C的左孩子, A结点成为C的右孩子
- 原来C结点的左子树β作为B的右子树;原来C结点的右子树γ作为A的左子树
RL型调整

例子:
输入关键字序列(16,3,7,11,9,26,18,14,15),给出构造AVL树的步骤。

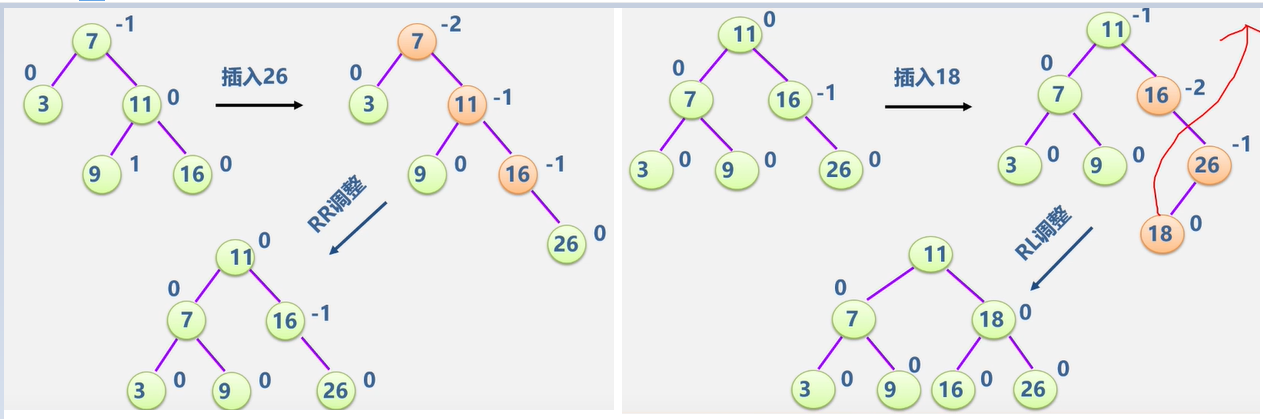
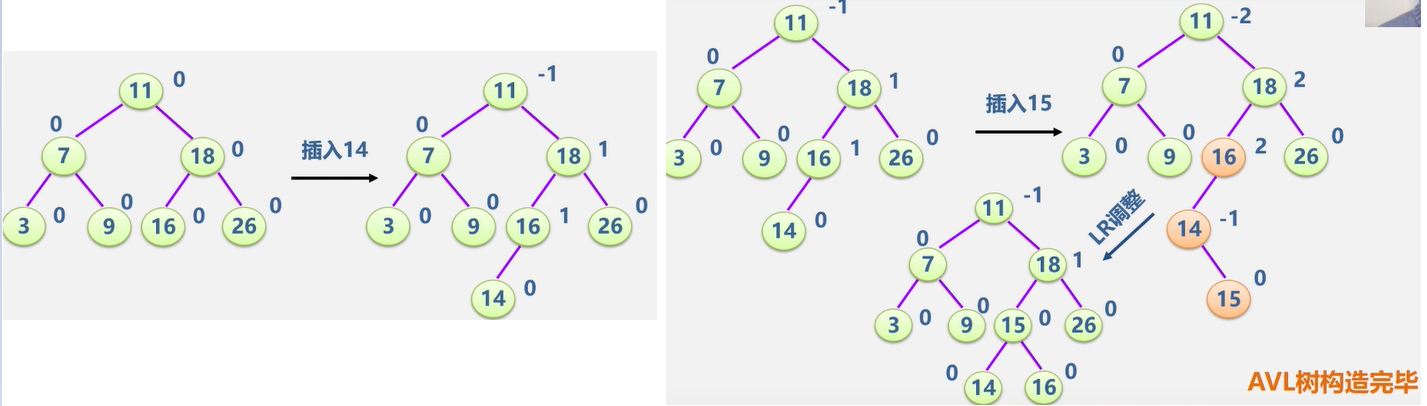
红黑树RBT
为什么有了平衡树还需要红黑树?
虽然平衡树解决了二叉查找树退化为近似链表的缺点,能够把查找时间控制在 O(logn),不过却不是最佳的,因为平衡树要求每个节点的左子树和右子树的高度差至多等于1,这个要求实在是太严了,导致每次进行插入/删除节点的时候,几乎都会破坏平衡树的第二个规则,进而我们都需要通过左旋和右旋来进行调整,使之再次成为一颗符合要求的平衡树。
显然,如果在那种插入、删除很频繁的场景中,平衡树需要频繁着进行调整,这会使平衡树的性能大打折扣,为了解决这个问题,于是有了红黑树
红黑树性质
1、是一颗二叉查找树
2、每个结点不是红色就是黑色
3、不可能有连在一起的红色结点
4、根节点是黑色
5、红色结点的两个孩子节点都是黑色
6、每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存数据
7、每个节点,从该节点到达其可达的叶子节点是所有路径,都包含相同数目的黑色节点。
为了满足以上性质,红黑树在插入删除时会做很多操作来保证性质。左旋、右旋、变颜色。
旋转和颜色变换规则:所有插入的点默认为红色
变颜色
颜色变化规则:插入的结点默认为红色,如果它的双亲结点为红色,它的叔叔结点(它父亲双亲的另一个孩子)也是红色结点,这样的情况就需要变颜色。
变换步骤
1、把它的双亲结点变为黑色
2、叔叔结点变为黑色
3、爷爷(双亲的双亲)结点变为红色
此时仍然满足红黑树性质!将要左旋!
左旋
左旋规则:以不满足性质的两结点的低层结点为当前结点。如果当前双亲点是红色,叔叔结点是黑色,且当前结点是右子树。这时要左旋,以双亲节点作为E,当前结点为S 左旋。左旋没有颜色改变
步骤:
S移上去
E移下来
S的左子树挂到E的右子树上
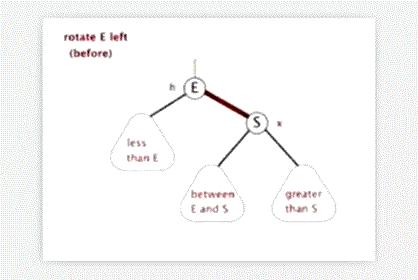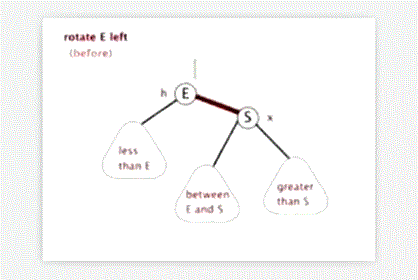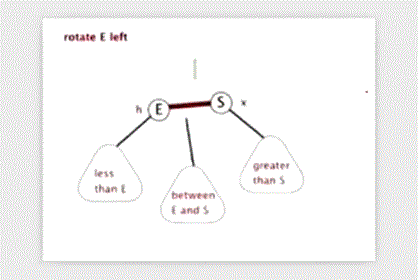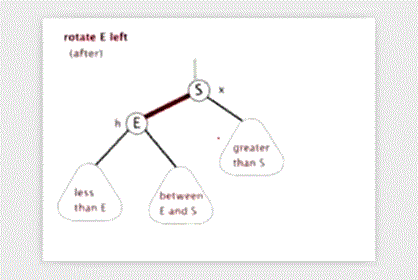

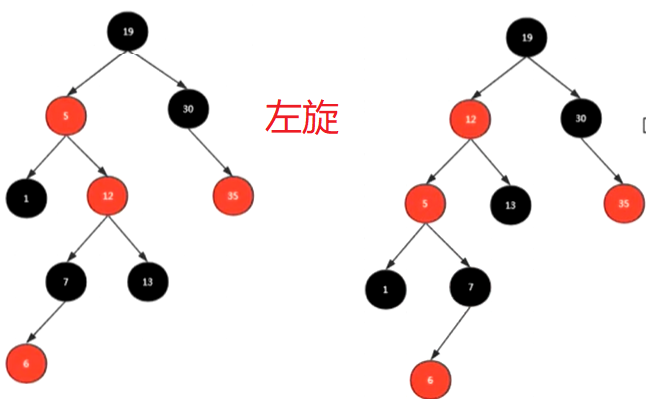
上图仍不满足红黑树性质!将右旋!
右旋
右旋规则:以不满足性质的两结点的低层结点为当前结点。如果当前双亲点是红色,叔叔结点是黑色,且当前结点是左子树。这时变颜色并右旋,
步骤:
当前结点的双亲结点变为黑色
当前结点的爷爷结点变为红色
以双亲节点作为E,以爷爷结点结点为S 右旋。
E移上去
S移下来
E的右子树挂到S的左子树
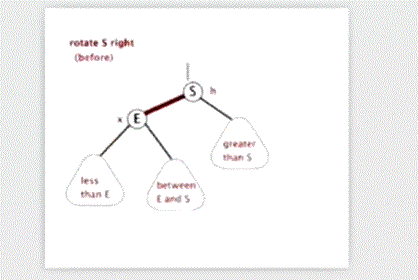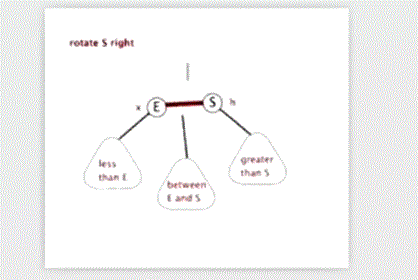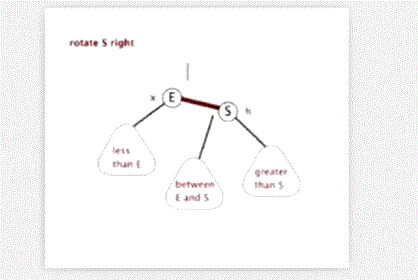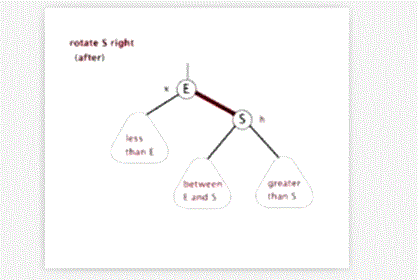

变色左右选完整例子图解
插入6
不满足性质要左旋
不满足性质要右旋
B-树
B+树
键树
散列表的查找
散列表的基本概念
基本思想:记录的存储位置与关键字之间存在对应关系
对应关系—hash函数

例一:


例二:
数据元素序列(21,23,39,9,25,11),若规定每个元素k的存储地址H(k)= k,请画出存储结构图

查找
根据散列函数H(key)=k
查找key=9,则访问H(9)= 9号地址,若内容为9则成功;若査不到,则返回一个特殊值,如空指针或空记录。
优点:查找效率高
缺点:空间效率低
散列表的相关术语
散列方法(杂凑法):
选取某个函数,依该函数按关键字计算元素的存储位置,并按此存放;
查找时,由同一个函数对给定值K计算地址,将k与地址单元中元素关键码进行比,确定查找是否成功。\
散列函数(杂凑函数):散列方法中使用的转换函数
散列表(凑表):按上述思想构造的表
散列函数:H(key)=k
冲突:不同的关键码映射到同一个散列地址
key1≠key2,但是H(key1)=H(key2)
例:有6个元素的关键码分别为:(25,21,39,9,23,11)。
- 选取关键码与元素位置间的函数为H(K)=k mod 7,
- 地址编号从0 - 6
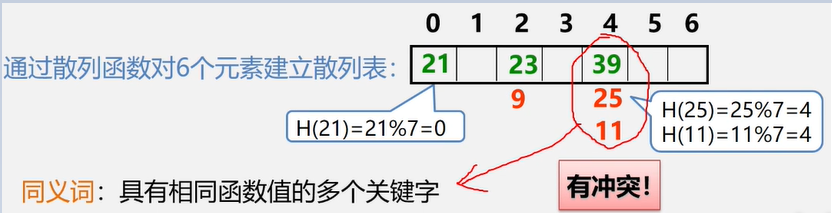
同义词:具有相同函数值的多个关键字
散列函数的构造方法
散列存储选取某个函数,依该函数按关键字计算元素的存储位置
LoC(i)= H(keyi)
冲突:不同的关键码映射到同一个散列地址
key1≠key2,但是H(key1)=H(key2)
在散列查找方法中,冲突是不可能避免的,只能尽可能减少
使用散列表要解决好两个问题
1、构造好的散列函数
(a)所选函数尽可能简单,以便提高转换速度;
(b)所选函数对关键码计算出的地址,应在散列地址集中致均匀分布,以减少空间浪费
2、制定一个好的解决冲突的方案
查找时,如果从散列函数计算出的地址中查不到关键码,则应当依据解决冲突的规则,有规律地查询其它相关单元。
构造散列函数考虑的因素
①执行速度(即计算散列函数所需时间)
②关键字的长度;
③散列表的大小
④关键字的分布情况;
⑤查找频率。

直接定址法
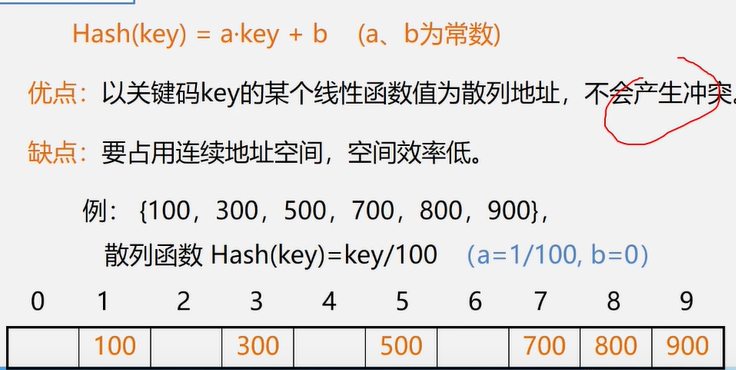
除留余数法

处理冲突的方法
开放定址法(开地址法)
基本思想:有冲突时就去寻找下一个空的散列地址,只要散列表是哆大空的散列地址总能找到,并将数据元素存入。
求di得方法右三种

线性探测法
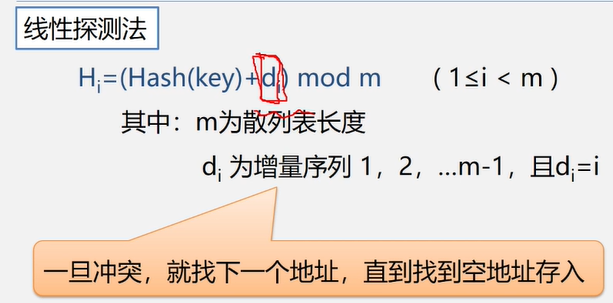
例:关键码集为{47,7,29,11,16,92,22,8,3},散列表大小为m=11;散列函数为Hash(key)= key mod11;拟用线性探测法解决冲突。建散列表如下:

二次探测法


伪随机探测法
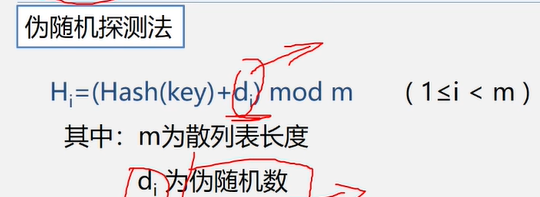
链地址法(拉链法)
基本思想:相同散列地址的记录链成一单链表
m个散列地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构
例如:一组关键字为
{19,1423168,20,84,27,55,11,10,79}
散列函数为Hash(key)=key mod 13
链地址法建立散列表步骤
- step1:取数据元素的关键字key,计算其散列函数值(地址)。若该地址对应的链表为空,则将该元素插入此链表;否则执行Step2解决冲突。
- step2根据择的冲突处理方法,计算关键字key的下一个存储地址。若该地址对应的链表为不为空,则利用链表的前插法或后插法将该元素插入此链表。
链地址法的优点:
- 非同义词不会冲突,无“聚集”现象
- 链表上结点空间动态申请,更适合于表长不确定的情况
再散列法(双散列函数法)
建立一个公共溢出区
散列表的查找效率
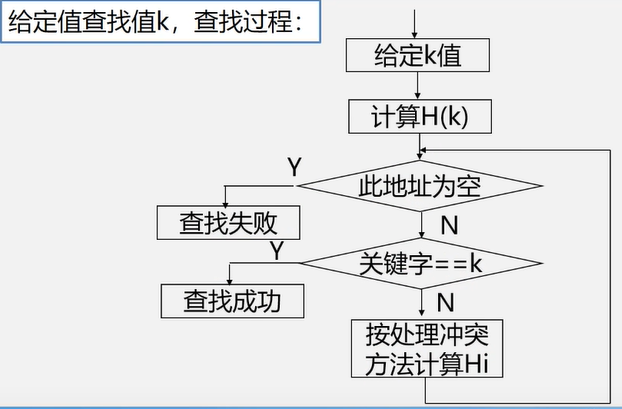


思考:
对于关键字集(19,1423168,20,8427,55,111079),n=12无序表查找ASL?
有序表折半查找ASL?
那么,散列表上查找ASL?。
散列表的查找效率分析:
使用平均査找长度ASL来衡量查找算法,ASL取决于
- 散列函数
- 处理冲突的方法
- 散列表的装填因子α

ASL与装填因子α有关!既不是严格的O(1),也不是O(n)

总结
- 散列表技术具有很好的平均性能,优于一些传统的技术
- 链地址法优于开地址法
- 除留余数法作散列函数优于其它类型函数
排序技术
基本概念和排序方法概述
什么是排序?
排序:将一组杂乱无章的数据按一定规律顺次排列起来。
即,将无序序列排成一个有序序列(由小到大或由大到小)的运算。
如果参加排序的数据结点包含多个数据域,那么排序往往是针对其中某个域而言
排序的应用非常广泛
- 软件中直接应用
- windows文件夹排序
- 购物网站商品排序
- 游戏排行榜的排序
排序方法的分类
按数据存储介质:内部排序和外部排序
按比较器个数:串行排序和并行排序
按主要操作:比较排序和基数排序
按辅助空间:原地排序和非原地排序
按稳定性:稳定排序和非稳定排序
按自然性:自然排序和非自然排序
按存储介质可分为:
- 内部排序:数据量不大、数据在内存,无需内外存交换数据
- 外部排序:数据量较大、数据在外存(文件排序)
外部排序时,要将数据分批调入内存来排序,中间结果还要及时放入外存,显然外部排序要复杂得多
按比较器个数可分为
- 串行排序:单处理机(同一时刻比较一对元素)
- 并行排序:多处理机(同一时刻比较多对元素)
按主要操作可分为
- 比较排序:用比较的方法插入排序、交换排序、选择排序、归并排
- 基数排序:不比较元素的大小仅仅根据元素本身的取值确定其有序位置。
按辅助空间可分为
- 原地排序:辅助空间用量为O(1)的排序方法。
(所占的辅助存储空间与参加排序的数据量大小无关) - 非原地排:助空间用量超过O(1)排序方法
按稳定性可分为
- 稳定排序:能够使任何数值柟等的元素,排序以店相对次序不变。
- 非稳定性排序:不是稳定排序的方法。
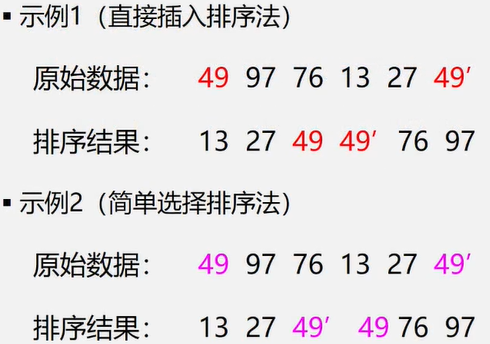
- 排序的稳定性只对结构类型数据排序有意义。
- 例如:
n个学生信息(学号、姓名、语文、数学、英语、总分)
1、按数学成绩从高到低排序2、按照总分从高到低排序。
3、总分相同的情况下,数学成绩高的排在前面 - 排序方法是否稳定,并不能衡量一个排序算法的优劣。

按自然性可分为
- 自然排序:输入数据越有序,排序的速度越快的排序方法。
- 非自然排序:不是自然排序的方法。
学习内容
- 按数据存储介质:内部排序和外部排序
- 按比较器个数:串行排序和并行排序
- 按主要操作:比较排序和基数排序
存储结构

插入排序
基本思想:每步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止。
即边插入边排序,保证子序列中随时都是排好序的
基本操作:有序插入f
1、在有序序列中插入一个元素,保持序列有序,有序长度不断增加
2、起初,a[0]是长度为1的子序列。然后逐一将a[1]至a[n-1]插入到有序子序列中。
在插入a[i] 前,数组的前半段( a[0] - a[i-1])是有序段,后半段(a[i]~a[n-1])是停留于输入次序的“无序段”。
插入a[i]使a[0] ~ a[i-1]有序,也就是要为a[i]找到有序位置j( 0 ≤ j ≤ i ),将a[i]插入在a[j]的位置上
可能的插入位置

根据寻找插入位置的方法不同,可以分为顺序法、二分法、缩小增量

直接插入排序
直接插入排序—采用顺序查找法查找插入位置


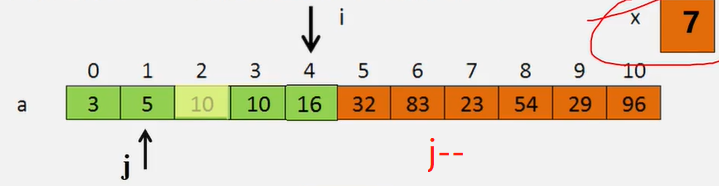
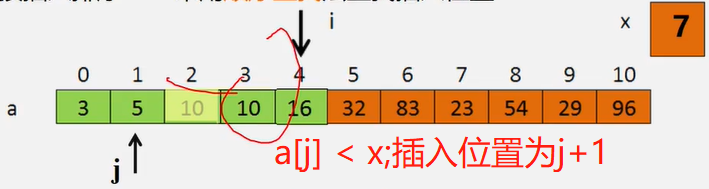
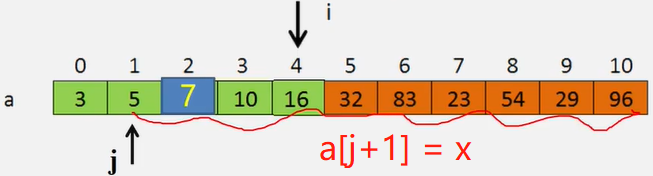
1、复制插入元素
2、记录后移,查找插入位置
3、插入到正确的位置
// i 要插入的元素位置 , x 要插入的元素 ,
x = a[i]
// j 先查找第 i -1 的是元素 , (也可以从 a[0] 开始查找)
j = [i -1]
// 如果比x大
a[j] > x
//元素后移 继续寻找 比x小的元素
a[j+1] = a[j]
//继续寻找 , 直到 j == 0 ,或者a[j] < x 获得j+1 的位置
for(j = i-1; j>=0 && x < a[j];j--)
//插入到正确的位置
a[j+1] = x
//直接插入排序
public static void insertSort(int[] data){
//当前查找的元素变量
int x ;
//要插入位置变量
int j;
for (int i = 1; i < data.length; i++) {
if (data[i] < data[i-1]){ //如果要插入的位置比它前一个位置大,那么就不用排序了
x = data[i];
//寻找 data[i] 的插入位置
for (j = i-1; j >=0 && x < data[j] ;j--){//从i-1开始,一直找到比x还要小的值
data[j+1] = data[j]; //元素后移
}
//插入到正确的位置
data[j+1] = x;
}
}
}
带哨兵的直接插入排序
由于for(j = i-1; j>=0 && x < a[j];j--)每次又要比较两次,因此我们可以使用哨兵


性能分析
实现排序的基本操作有两个:
(1)“比较”序列中两个关键字的大小;
(2)“移动”记录。
最好的情况(关键字在记录序列中顺序有序)

最坏的情况(关键字在记录序列中逆序有序)

平均的情况
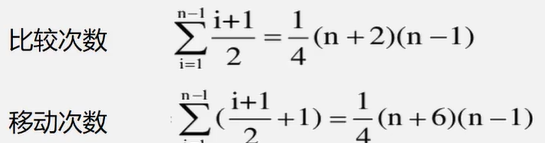
总结
- 原始数据越接近有序,排序速度越快
- 最坏情况下(输入数据是逆有序的)Tw(n)=O(n*n)
- 平均情况下耗时差不多是最坏情况的一半Te(n)= O(n*n)
- 要提高查找速度需要减少元素的比较次数减少元素的移动次数
折半插入排序
查找插入位置时采用折半查找法
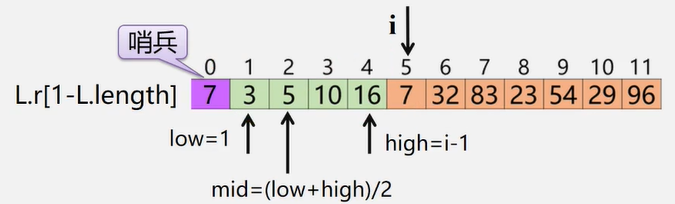

算法分析:
- 折半查找比顺序查找快,所以折半插入排序就平均性能来说比直接插入排序要快;
- 它所需要的关键码比较次数与待排序对象序列的初始排列无关,仅依赖于对象个数。在插入第i个对象时,需要经过
 次关键码比较,才能确定它应插入的位置;
次关键码比较,才能确定它应插入的位置;
- 当n较大时,总关键码比较次数比直接插入排序的最坏情况要好得多,但比其最好情况要差;
- 在对象的初始排列已经按关键码排好序或接近有序时,直接插入排序比折半插入排序执行的关键码比较次数要少
- 折半插入排序的对象移动次数与直接插入排序相同,依赖于对象的初始排列
- 减少了比较次数,但没有减少移动次数
- 平均性能优于直接插入排序
- 时间复杂度为O(n*n)
- 空间复杂度O(1)
- 是一种稳定的排序方法
希尔排序
直接插入排序在什么情况下效率比较高?
直接插入排序在基本有序时,效率较高
在待排序的记录个数较少时,效率较高
希尔排序算法思想的出发点:能否比较一次移动一大步?
基本思想:
先将整个待排记录序列分割成若干序列,分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
希尔排序算法,特点:
1)缩小增量
2)多遍插入排序
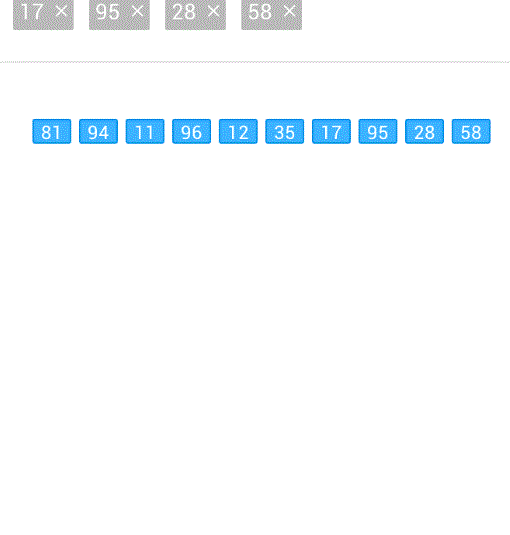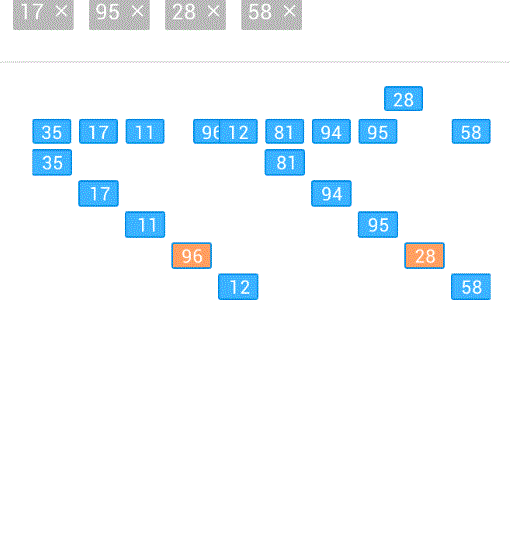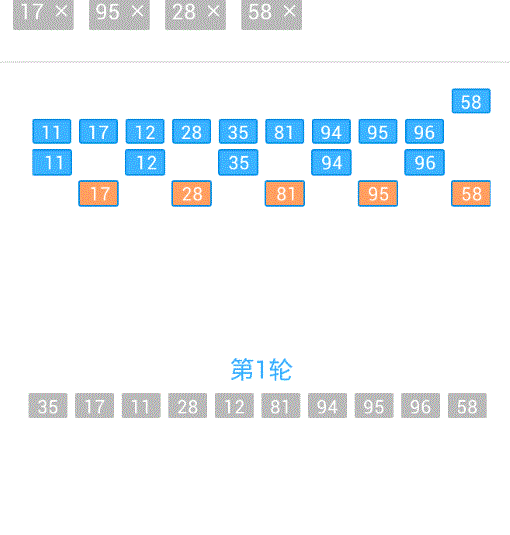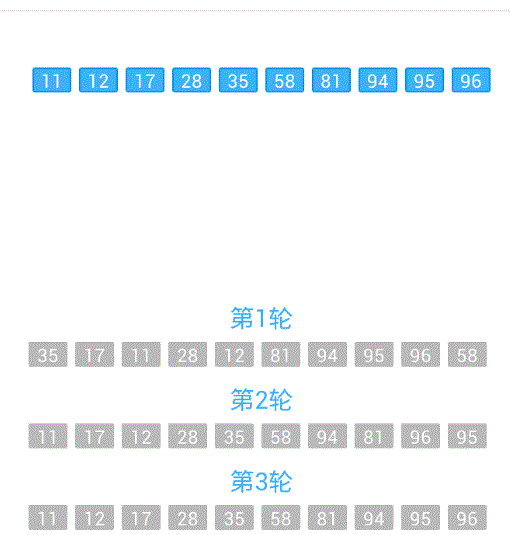
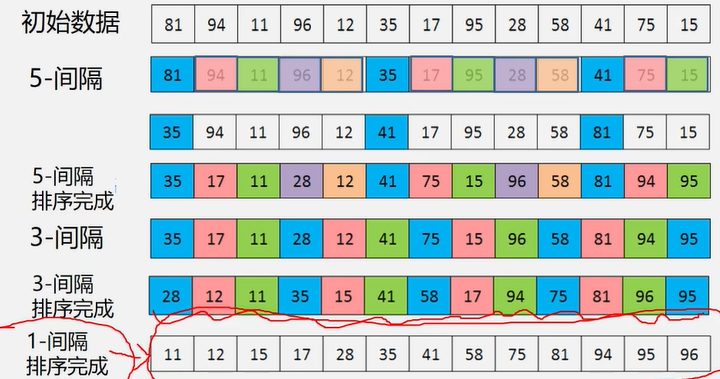

希尔排序特点:
- 一次移动,移动位置较大,跳跃式地接近排序后的最终位置
- 最后一次只需要少量移动
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
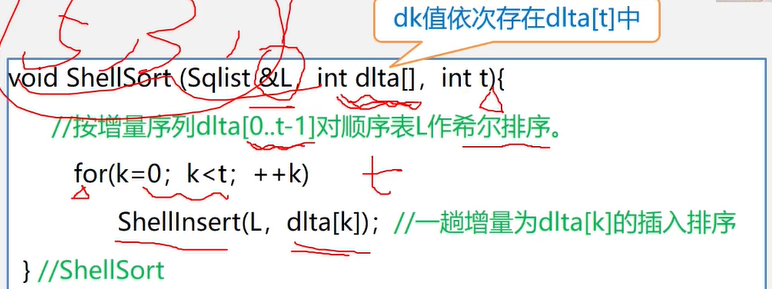
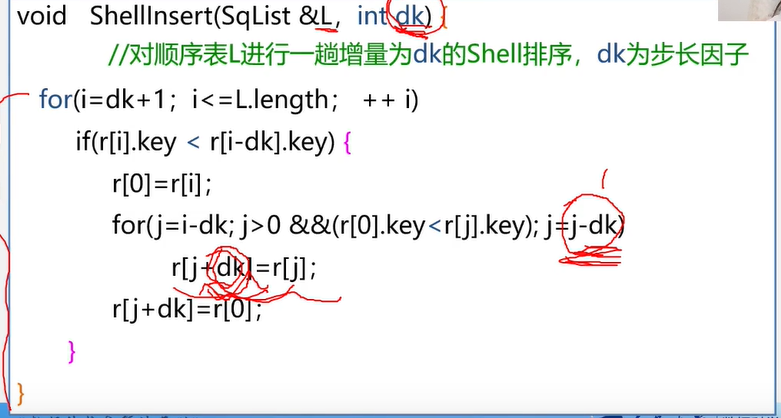
//希尔排序 dlta 增量序列
public static void shellSort(int[] data , int[] dlta){
//按照顺序增量dlta[0...t-1]对顺序表做希尔排序
//{5,3,1}
for (int k = 0; k < dlta.length ;k++){
shellInsert(data,dlta[k]); //一趟增量为dlta[k]的插入排序
}
}
private static void shellInsert(int[] arrays, int step) {
//对顺序表arr进行步长为step 的shell排序
for (int i = step; i < arrays.length; i++) {
int j = i;
int temp = arrays[j];
// j - step 就是代表与它同组隔壁的元素 他的同组元素大
while (j - step >= 0 && arrays[j - step] > temp) {
//互换位置
arrays[j] = arrays[j - step];
j = j - step;
}
arrays[j] = temp;
}
}
时间效率
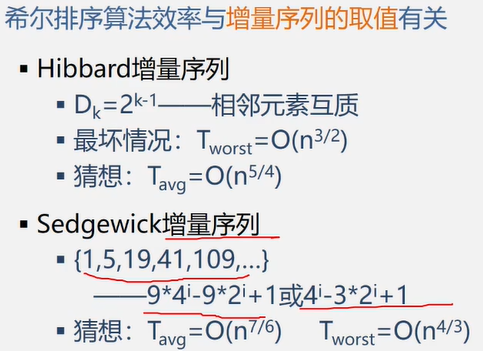
-
时间复杂度是n和d的函数:

-
空间复杂度为O(1)
-
是一种
不稳定的排序方法- 如何选择最佳d序列,目前尚未解决
- 最后一个增量值必须为1,无除了1之外的公因子
- 不宜在链式存储结构上实现
交换排序
基本思想:
常见的交换排序方法:
- 冒泡排序
- 快速排序
冒泡排序
基本思想:每趟不断将记录两两比较,并按“前小后大”规则交换
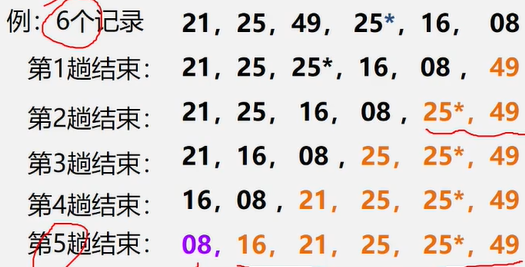

初始:21,25,49,25*,16, 08 n=6

总结
第n个记录,总共需要n-1趟
第m趟需要比较n-m次

//冒泡排序
public static void bubbleSort(int[] data){
for (int i = 0; i < data.length; i++) {
for (int j = data.length-1 ; j > i;j--){
if (data[j] < data[j-1]){//发生逆序,交换位置
int temp = data[j];
data[j] = data[j-1];
data[j-1] = temp;
}
}
}
}
//冒泡
static void test(int[] data){
for (int k = 0; k < data.length; k++) {
for (int i = 0 ; i < data.length-k-1 ; i++){
//如果不匹配交换位置
if (data[i] > data[i+1]){
int temp = data[i];
data[i] = data[i+1];
data[i+1] = temp;
}
}
}
}
冒泡算法改进
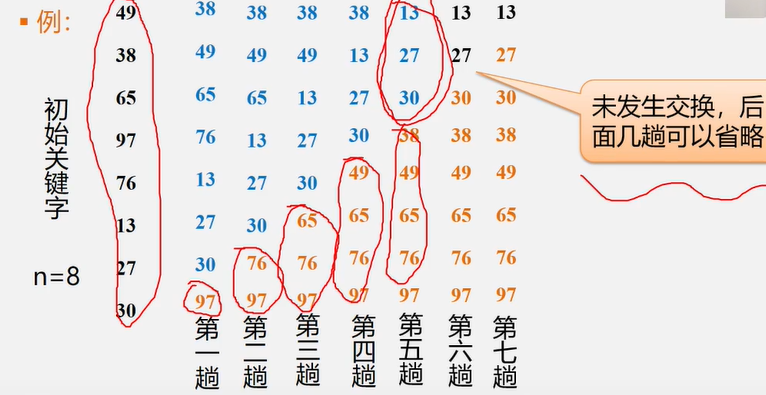

//冒泡
static void test(int[] data){
boolean flag = true; //未发生交换后面几趟可以省略
for (int k = 0; k < data.length && flag; k++) {
flag = false;
for (int i = 0 ; i < data.length-k-1 ; i++){
//如果不匹配交换位置
if (data[i] > data[i+1]){
flag = true;
int temp = data[i];
data[i] = data[i+1];
data[i+1] = temp;
}
}
}
}
算法分析

- 冒泡排序最好时间复杂度是O(n)
- 冒泡排序最坏时间复杂度为O(n*n)
- 冒泡排序平均时间复杂度为O(n*n)
- 冒泡排序算法中增加一个辅助空间temp,辅劻空间为S(n)=O(1)
- 冒泡排序是稳定的
快速排序
基本思想:
- 任取一个元素(如:第一个)为中心,:pⅳot:枢轴、中心点
- 所有比它
小的元素一律前放,比它大的元素一律后放,形成左右两个子表; - 对各子表重新选择中心元素并
依此规则调整:递归思想 - 直到每个子表的元素
只剩一个

基本思想:通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录进行排序以达到整个序列有序
具体实现:选定一个中间数作为参考,所有元素与之比较,小的调到其左边,大的调到其右边
(枢轴)中间数:可以是第一个数、最后一个数、最中间一个数、任选一个数等。
①每一趟的子表的形成是采用从两头向中间交替式逼近法;
②由于每趟中对各子表的操作都相似,可采用递归算法。

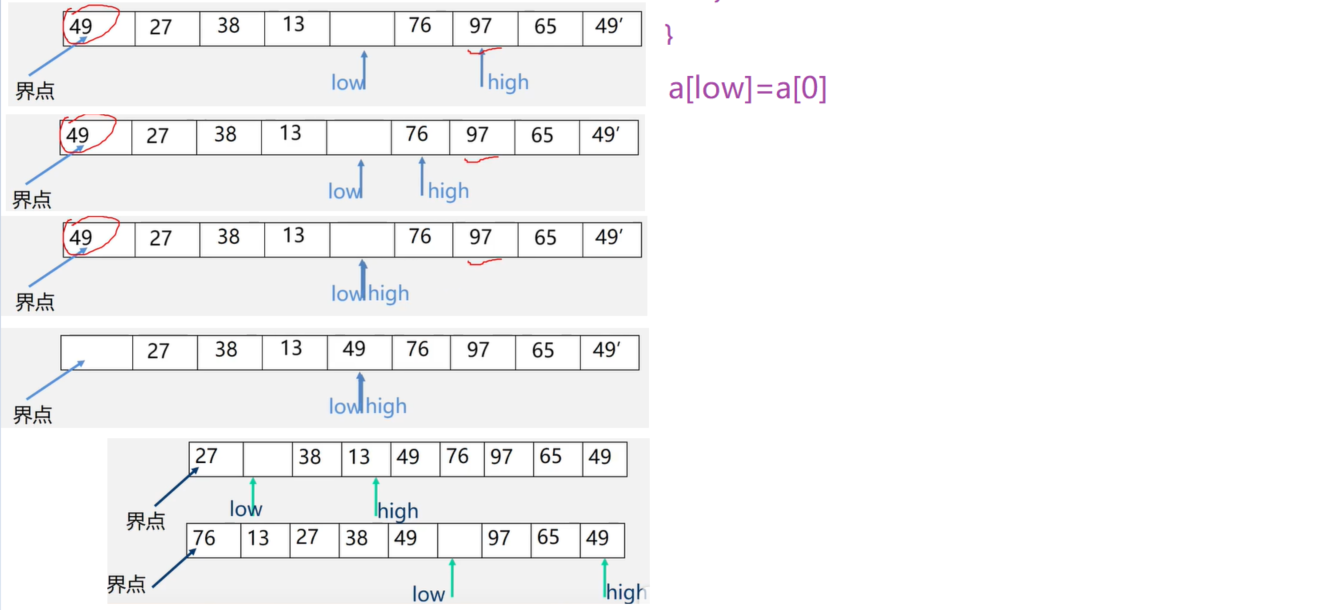
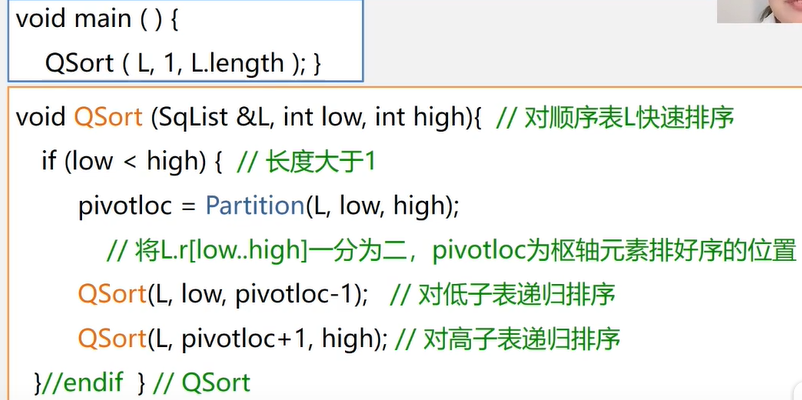
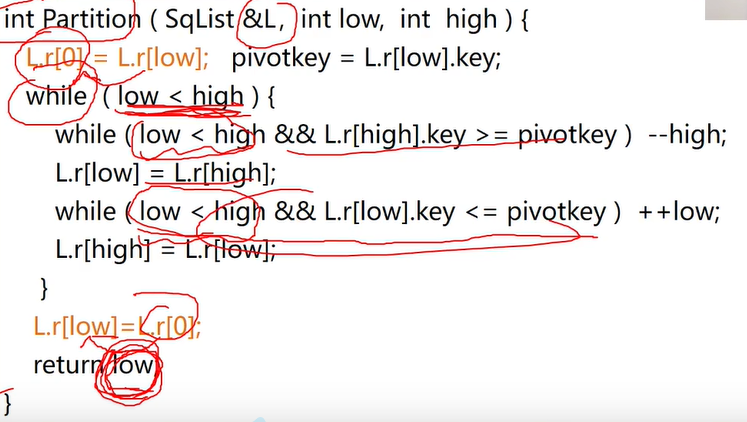
//快速排序 data[0] 不保存元素可以是0
public static void QSort(int[] data,int low,int high){
if (low < high){
int pivotloc = partition(data,low,high);
QSort(data,low,pivotloc-1);
QSort(data,pivotloc+1,high);
}
}
private static int partition(int[] data, int low, int high) {
//low = 1 high = length-1
data[0] = data[low];
data[low]=Integer.MAX_VALUE;
while (low!=high){
if(data[low]==Integer.MAX_VALUE){
if (data[0] > data[high]){
data[low]=data[high];
data[high]=Integer.MAX_VALUE;
}else {high--;}
}else if (data[high]==Integer.MAX_VALUE){
if (data[0] < data[low]){
data[high] = data[low];
data[low] = Integer.MAX_VALUE;
}else {
low++;
}
}
}
data[low] = data[0];
return low;
}
public static void main(String[] args) {
int[] data1 = {0,49,38,65,97,76,13,27,49};
QSort(data1,1,data1.length-1);
System.out.println(Arrays.toString(data1));
}
另一种快速排序的实现。
//快速排序3
public static void QSort3(int[] data , int left , int rigth){
if (left <= rigth){
int pivotloc = partition3(data,left,rigth);
QSort3(data,left,pivotloc-1);
QSort3(data,pivotloc+1,rigth);
}
}
private static int partition3(int[] data, int left, int rigth) {
int p = rigth;
while (left <= rigth){
while (data[left] < data[p] && left!=rigth){
left++;
}
while (data[rigth] > data[p] && left != rigth){
rigth--;
}
if (left == rigth){
swap(data,left,p);
return left;
}else {
swap(data,left,rigth);
}
}
return left;
}
public static void QSort3(int[] data){
QSort3(data,0,data.length-1);
}
另一种快速排序的实现

//快速排序
public static void QSort2(int[] data , int left , int rigth){
if (left <= rigth){
int pivotloc = partition2(data,left,rigth);
QSort2(data,left,pivotloc-1);
QSort2(data,pivotloc+1,rigth);
}
}
private static int partition2(int[] data, int left, int rigth) {
int p = data[left];
while (left < rigth){
while (left < rigth && data[rigth] >= p){
rigth--;
}
swap(data,left,rigth);
while (left < rigth && data[left] <= p){
left++;
}
swap(data,left,rigth);
}
return left;
}
public static void QSort2(int[] data){
QSort2(data,0,data.length-1);
}
算法分析
时间复杂度
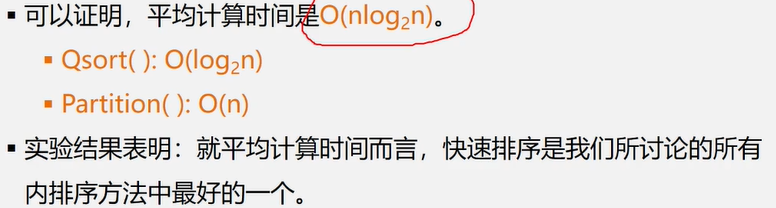
空间复杂度
快速排序不是原地排序
由于程序中使用了递归,需要递归调用栈的支持,而栈的长度取决于递归调用的深度。(即使不用递归,也需要用用户栈)
在平均情况下:需要O(log n)的栈空间
最坏情况下:栈空间可达O(n)。
稳定性

思考:
试对(90,85,79,74,68,50,46)进行快速排序的划分
■你是否发现什么特殊情况?
再对(46,50,68,7479,85,90)进行快速排序划分呢?
由于每次枢轴记录的关键字都是大于其它所有记录的关键字,致使次划分之后得到的子序列(1)的长度为0,这时已经退化成为没有改进措施的冒泡排序。
快速排序不适于对原本有序或基本有序的记录序列进行排序。
总结
- 划分分元素的选取是影响时间性能的关键
- 输入数据次序越乱,所选划分元素值的随机性越好,排序速度越快,快速排序不是
自然排序方法。 - 改变划分元素的选取方法,至多只能改变算法平均情况的下的时间性能,无法改变最坏情况下的时间性能。即最坏情况下,快速排序的时间复杂性总是O(n2)
选择排序
简单选择排序
基本思想:在待排序的数据中选出最大(小)的元素放在其最终的位置。
基本操作:
1、首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与策一个记录交换
2、再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与第二个记录交换
3、重复上述操作,共进行n-1趟排序后,排序结束
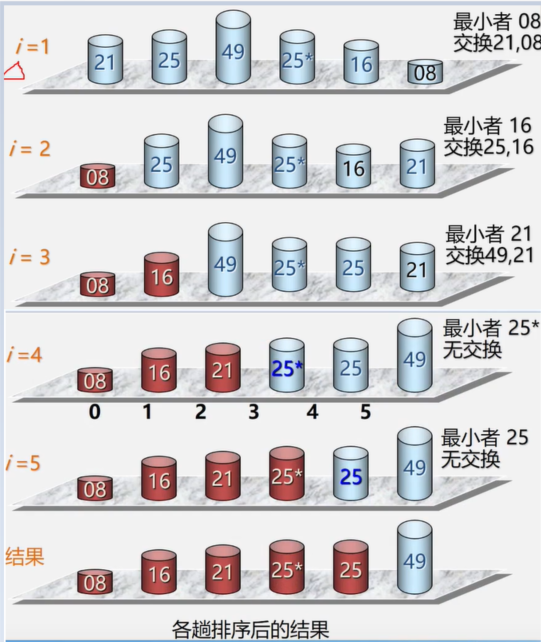


//简单选择排序
public static void selectSort(int[] data){
for (int i = 0; i <= data.length - 1; i++) {
int min = i; //记录最小元素下标
//查找最小元素
for (int k = i ; k <= data.length-1 ;k++){
if (data[min] > data[k]){
min = k;
}
}
//如果当前元素已经是最小的那就不替换
if (min!=i){
swap(data,i,min);//替换
}
}
}
//data元素中的 a , b 位置元素值互换
public static void swap(int[] data , int a , int b){
int temp = data[a];
data[a] = data[b];
data[b] = temp;
}
算法分析

堆排序
堆的定义

从堆的定义可以看出,堆实质是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于(大于)它的孩子结点
那么堆的性质也和完全二叉树一样,i结点的左右孩子是 2i 和 2i-1
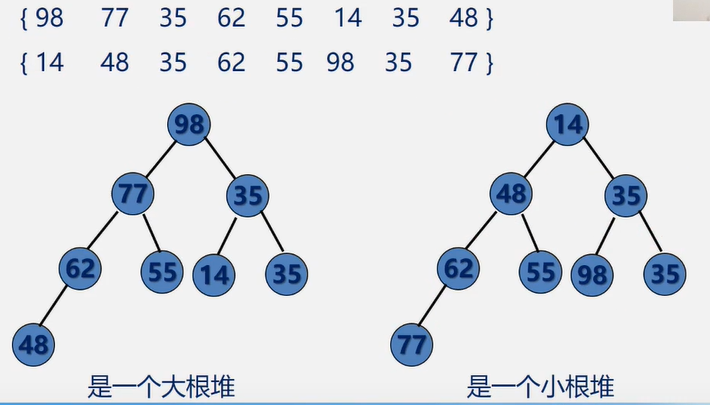
堆排序
若在输出堆顶的最小值(最大值)后,使得剩余n-1个元素的序列重又建成一个堆,则得到n个元素的次小值(次大值)……如此反复,便能得到一个有序序列,这个过程称之为堆排序。
实现堆排序需解决两个问题:
1、如何由一个序列建成一个堆?
2、如何在输出堆顶元素后,调整剩余元素为一个新的堆?
堆的调整(筛选)
如何在输出堆顶元素后,调整剩余元素为一个新的堆?
以小根堆为例:
1、输出堆顶元素之后,以堆中最后一个元素替代之
2、然后将根结点值与左、右子树的根结点值进行比较,并与其中小者进行交换;
3、重复上述操作,直至叶子结点,将得到新的堆,称这个从堆顶至叶子的调整过程为“筛选”
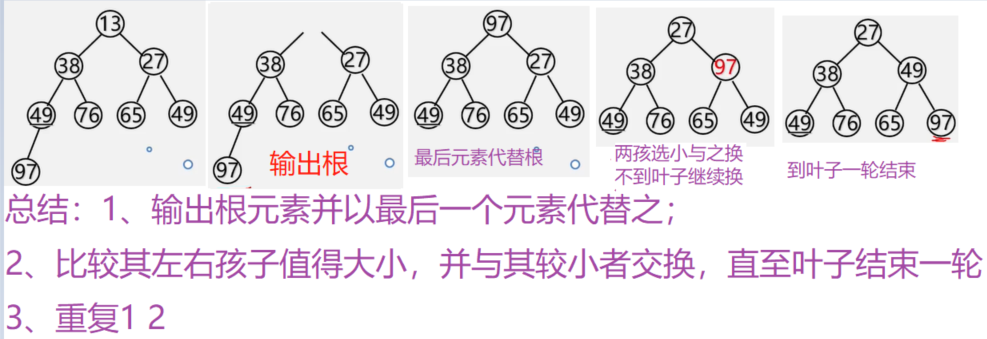
//小根堆的筛选
public static void heapAdjust(int[] data , int s , int m){
int rc = data[s];
for (int j = s * 2; j <= m ; j =j * 2){
if (j < m && data[j] > data[j+1]){//右孩子小
j++;
}
if (rc <= data[j])break;
data[s] = data[j];
s = j;
}
data[s] = rc;
}

可以看出对一个无序序列反复筛选”就可以得到一个堆
即:从一个无序序列建堆的过程就是一个反复“筛选”的过程。
堆的建立
显然单结点的二叉树是堆;
在完全二叉树中所有以叶子结点(序号i>n/2)为根的子树是堆。
这样,我们只需依次将以序号为n/2,n2-1,…,1的结点为根的子树坳调整为堆即可
即:对应由n个元素组成的无序序列,“筛选”只需从第n/2个元素开始
由于堆实质上是一个线形表,那么我们可以顺序存储一个堆。
下面以一个实例介绍建一个小根堆的过程。
例:有关键字为49,38,65,97,76,13,27,49的—组记录,将其按关键字调整为一个小根堆。
从最后一个非叶子结点开始,以此向前调整
1、调整从第n/2个元素开始,将以该元素为根的二叉树调整为堆
2、将以序号为n/2-1的结点为根的二叉树调整为堆;
3、再将以序号为n/2-2的结点为根的二叉树调整为堆;
4、再将以序号为n/2-3的结点为根的二叉树调整为堆;
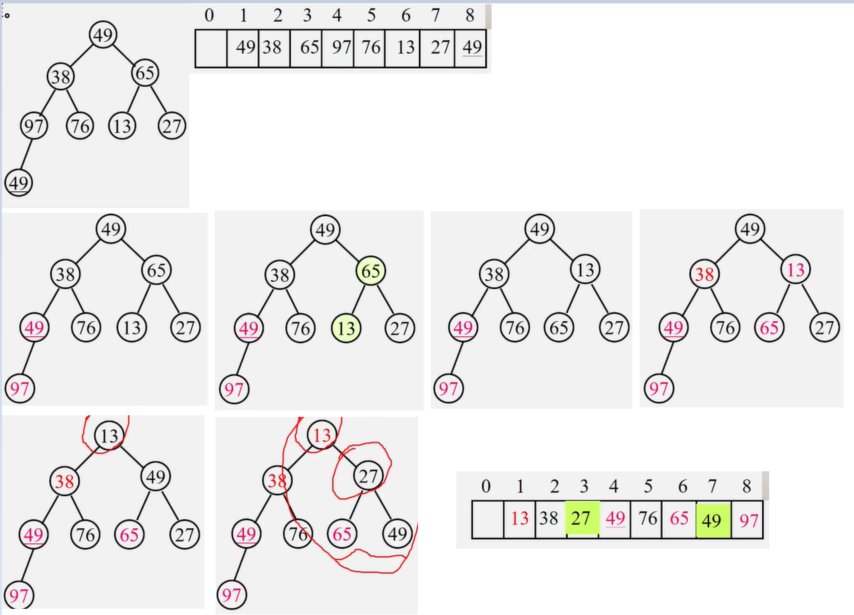

//创建小根堆
public static void createHeap(int[] data){
for (int i = (data.length-1)/2 ; i >= 1;i--){
System.out.println(i);
heapAdjust(data , i , data.length-1);
}
}
排序
由以上分析知:
若对个无序序列建堆,然后输出根:重复该过程就可以由一个无需序列输出有序序列。
实质上,堆排序就是利用完全二二叉树中父结点与孩子结点间的内在关系来排序的。


//排序
public static void heapSort(int[] data){
//初始化
createHeap(data);
for (int i = data.length-1 ; i > 1;i--){
System.out.println(data[1]);
swap(data , 1 , i);
heapAdjust(data , 1 ,i-1);
}
}
完整代码
//堆的筛选
public static void heapAdjust(int[] data , int s , int m){
//System.out.println(s);
int rc = data[s];
for (int j = s * 2; j <= m ; j =j * 2){
if (j < m && data[j] > data[j+1]){//右孩子小
j++;
}
if (rc <= data[j])break;
data[s] = data[j];
s = j;
}
data[s] = rc;
}
//创建小根堆
public static void createHeap(int[] data){
for (int i = (data.length-1)/2 ; i >= 1;i--){
heapAdjust(data , i , data.length-1);
}
}
//排序
public static void heapSort(int[] data){
//初始化
createHeap(data);
for (int i = data.length-1 ; i > 1;i--){
System.out.println(data[1]);
swap(data , 1 , i);
heapAdjust(data , 1 ,i-1);
}
}
public static void main(String[] args) {
int[] heap = {0 , 49 , 38 , 65 , 97 , 76 , 13 , 27 , 49};
//heapAdjust(hep , 1 , heap.length-1);
heapSort(heap);
}
性能 分析

- 堆排序的时间主要耗费在建初始堆和调整建新堆时迸行的反复筛选上。堆排序在最坏情况下,其时间复杂度也为
 ,这是堆排序的
,这是堆排序的最大优点。无论待排序列中的记录是正序还是逆序排列,都不会使堆排序处于"最好"或"最坏"的状态。 - 另外,堆排序仅需一个记录大小供交换用的辅助存储空间。
- 然而堆排序是种不稳定的排序方法,它不适用于待排序记录个数n较少的情况,但对于n较大的文件还是很有效的
归并排序
基本思想:将两个或两个以上的有序子序列“归并”为一个有序序列。
在内部排序中,通常采用的是2-路归并排序。




基数排序
基本思想:分配+收集
也叫桶排序或箱排序:设置若干个箱子,将关键字为k的记录放入第k个箱子,然后在按序号将非空的连接。
基数排序:数字是有范闺的,均由0-9这十个数字组成则只需设置十个箱子,相继按个、十、百…迸行排序

算法分析
时间效率:O(k(n+m)
k:关键字个数,
m:关键字取值范围为m个值
空间效率:O(n+m)
稳定性:稳定

外部排序(略)
各种排序方法比较

一、时间性能
1.按平均的时间性能来分,有三类排序方法:
时间复杂度为 O(nlogn)的方法有:快速排序、堆排序和归并排序,其中以快速排序为最好;
时间复杂度为O(n*n)的有直接插入排序、冒泡排序和简单选择排序,其中以直接插入为最好,特别是对那些对关键字近似有序的记录序列尤为如此;
时间复杂度为O(n)的排序方法只有:基数排序
2.当待排记录序列按关键字顺序有序时,直接插入排序和冒泡排序能达到O(n)的时间复杂度;而对于快速排序而言,这是最不好的情况,此时的时间性能退化为O(n2),因此是应该尽量避免的情况。
3.简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
二、空间性能
指的是排序过程中所需的辅助空间大
1.所有的简单排序方法(包括:直接插入、冒泡和简单选择)和堆排序的空间复杂度为O(1)
2.快速排序为O(logn),为栈所需的辅助空间
3.归并排序所需辅助空间最多,其空间复杂度为O(n)
4.链式基数排序需附设队列首尾指针,则空间复杂度为O(rd)
三、排序方法的稳定性能
稳定的排序方法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变
当对多关键字的记录序列进行LSD方法排序时,必须采用稳定的排序方法。
对于不稳定的排序方法,只要能举出一个实例说明即可。
快速排序和堆排序是不稳定的排序方法。
四、关于“排序方法的时间复杂度的下限
本章讨论的各种排序方法,除基数排序外,其它方法都是基于“比较关键字”进行排序的排序方法,可以证明,这类排序法可能达到的最快的时间复杂度为O(n log n)
(基数排序不是基于“比较关键字”的排序方法所以它不受这个限制)
可以用一棵判定树来描述这类基于“比较关键字”进行排序的排序方法。
补充
C语言

操作算法中用到的预定义的常量和类型

public class Const<T> {
public static final int TRUE = 1;
public static final int FALSE = 0;
public static final int OK = 1;
public static final int ERROR = 0;
public static final int INFEASIBLE= -1;
public static final int OVERFLOW = -2;
public static int Status;
public T ElemType;
}
数学相关
对数
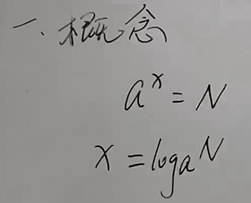
a的x次幂等于N,那么x叫做以a为底N的对数(a > 0 , a ≠ 1,N > 0)
a:底数
N:真数
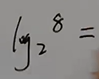 意思是2的几次幂等于8 , 2的3次幂等于8
意思是2的几次幂等于8 , 2的3次幂等于8
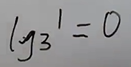 任何一个数(除0外)它的0次幂等于1
任何一个数(除0外)它的0次幂等于1